
The Science and Psychology of Voice Confrontation: A Comprehensive Guide to Overcoming Microphone Nerves
The aversion to the sound of one's own recorded voice is a phenomenon of nearly universal prevalence, frequently serving as the primary psychological catalyst for microphone anxiety, public speaking apprehension, and performance nerves. Formally classified in the psychological and audiologic literature as "voice confrontation," this profound discomfort arises from a highly complex intersection of anatomical acoustics, cognitive psychology, and psychoacoustic expectation. For professionals whose careers demand regular audio recording, public broadcasting, or remote digital communication-from corporate executives and educators to podcasters, voice actors, and media personalities-this physiological and psychological dissonance can represent a significant, career-limiting barrier to effective communication (American Academy of Audiology).
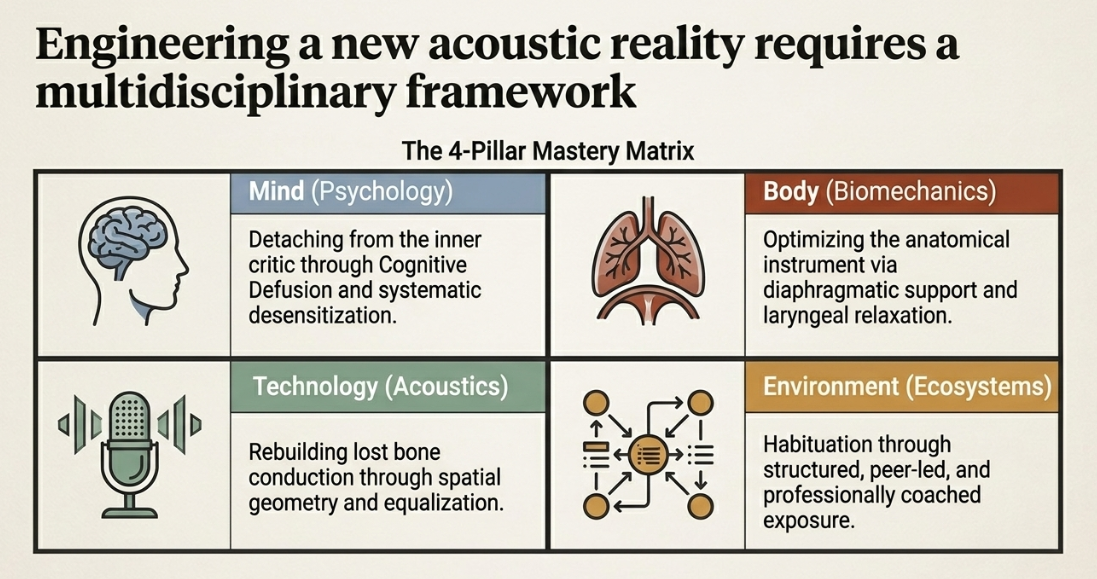
Historically, voice confrontation was a niche experience reserved for professional broadcasters, actors, and musicians. However, the proliferation of digital communication, virtual conferencing, and ubiquitous recording technology has democratized this anxiety, forcing the general public to confront their externalized voices on a daily basis. To systematically dismantle microphone anxiety, one must adopt a rigorous, multidisciplinary approach. The solution lies not merely in repeated exposure, but in understanding the precise physiological mechanisms that render a recorded voice alien, addressing the psychological defensiveness triggered by this acoustic mismatch, applying specific vocal pedagogy to optimize the anatomical instrument, utilizing acoustic engineering to bridge the gap between internal and external perception, and engaging in structured professional development.

The Physiological Mechanics of Self-Voice Perception
The foundation of voice confrontation is deeply rooted in the biomechanics and evolutionary biology of human hearing. When an individual listens to the voice of another person, or indeed any external environmental sound, the auditory information travels exclusively through the surrounding atmosphere. This standard acoustic process, known as air conduction, involves sound waves entering the outer ear, traveling down the external auditory canal, and vibrating the tympanic membrane (eardrum). These vibrations are subsequently transmitted through the ossicles of the middle ear-the malleus, incus, and stapes-to the fluid-filled cochlea of the inner ear, where hair cells convert the mechanical energy into electrical impulses for the brain to interpret.
The Dual-Pathway System: Air, Bone, and Cartilage Conduction
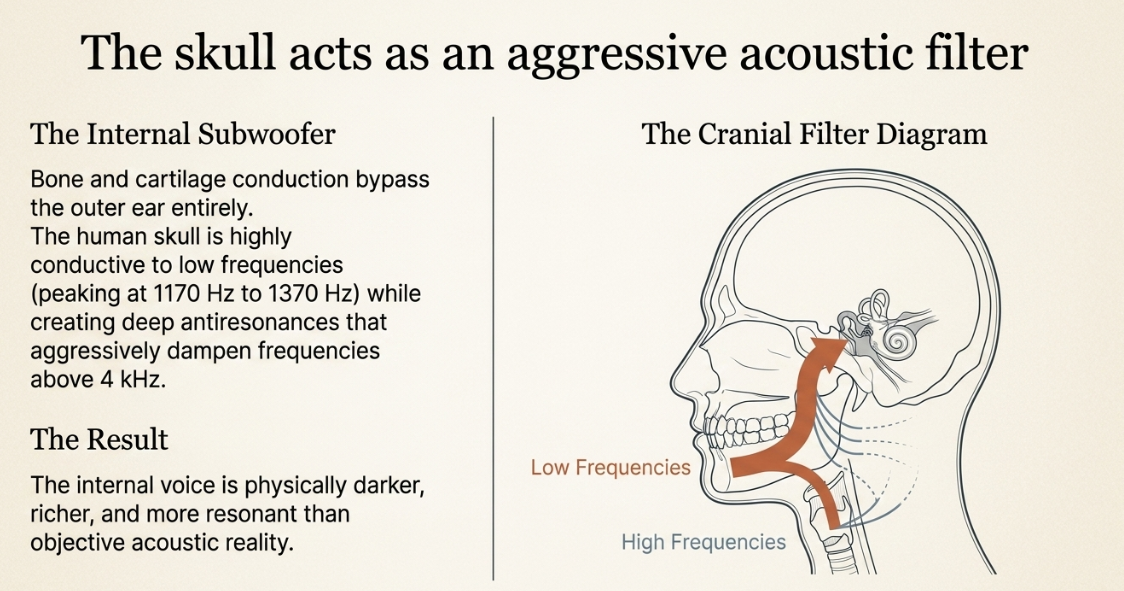
When individuals speak, however, they perceive their own vocalizations through a highly complex, internal dual-pathway system. As the vocal folds vibrate to produce sound, those acoustic waves are not only expelled outward through the oral and nasal cavities into the air, but they also travel inward, propagating through the dense tissues, cartilage, and osseous structures of the speaker's own body. This internal transmission route, primarily referred to as bone conduction, bypasses the outer and middle ear entirely. The mechanical vibrations generated by the diaphragm and larynx are transferred directly through the cranial bones to the cochleae. Because bone and dense biological tissues are highly efficient mediums for transmitting low-frequency acoustic energy, the human skull acts as a sophisticated, anatomical acoustic filter. This filter naturally amplifies the deeper, lower frequencies of the speaker's voice while simultaneously dampening higher frequencies. Consequently, the internal representation of one's own voice features a rich, resonant, "subwoofer" quality that is entirely imperceptible to external listeners (Vimeo).
When a speaker hears a raw audio recording of their voice, this internal bone and cartilage conduction pathway is completely eliminated. The recorded audio is delivered to the listener entirely via air conduction, ruthlessly stripping away the low-frequency resonance the speaker has spent a lifetime hearing. Deprived of these familiar, comforting bass frequencies, the recorded voice inevitably sounds higher-pitched, thinner, less authoritative, and fundamentally alien to the speaker's internal expectation (The Guardian).
The Acoustic Filtering Profile of the Human Skull
The degree to which bone conduction alters self-perception is not uniform; rather, it is a highly complex acoustic phenomenon that varies depending on individual anatomical structures and the specific frequencies being phonated. Advanced audiologic studies modeling human bone-conducted sound perception demonstrate that vibrations of the bone encapsulating the inner ear dominate the hearing response. The lowest thresholds for bone conduction-meaning the frequencies at which the skull is most sensitive, highly conductive, and requires the least intensity to detect-occur tightly around 1170 Hz to 1370 Hz, which aligns perfectly with the core frequency range of human speech intelligibility.
However, the skull's transmission of sound presents significant variance across the frequency spectrum. Research measuring the variance of frequency responses across different cranial locations-such as the chin angle, collarbone, forehead, inion, mastoid, vertex, and temple-reveals that while the human body conducts low tones with high efficiency, it presents sharp and deep antiresonances at frequencies exceeding 4 kHz. Because the skull aggressively dampens these higher frequencies while augmenting the fundamental lows, the internal voice is profoundly darker in timbre than the objective reality. Furthermore, some studies indicate that cartilage conduction acts as a tertiary pathway alongside bone and air, further complicating the internal acoustic profile and contributing to individual differences in own-voice perception based on unique physiological structures (PMC - NIH).
Understanding this specific frequency variance is not merely an exercise in acoustic trivia; it is of immediate clinical relevance. Advanced research indicates that deficits in self-other voice discrimination-the inability to accurately predict or recognize the acoustic parameters of one's own speech-have been linked to auditory-verbal hallucinations (AVHs), such as "hearing voices," which is a primary and highly distressing symptom in major psychiatric disorders like schizophrenia (PMC). The brain's reliance on bone conduction to accurately tag a voice as "self" underscores how deeply the physical properties of sound are intertwined with human neurology and identity (PMC).
The Psychology of Voice Confrontation: Expectancy and Identity
While the physiological absence of bone conduction efficiently explains the acoustic mechanics of why the recorded voice sounds physically different, it does not fully explain the intense affective disturbance, the visceral psychological cringe, and the subsequent performance anxiety that accompany the experience. The psychological dimensions of voice confrontation are deeply tied to self-identity, expectation violation, and implicit ego defense mechanisms.
The Expectancy Gap and Affective Disturbance
The term "voice confrontation" was extensively explored and defined in a seminal 1966 clinical study conducted by psychologists Philip S. Holzman and Clyde Rousey. Through their rigorous experiments involving vocal recordings and subject playbacks, Holzman and Rousey concluded that the intense discomfort of hearing one's recorded voice arises from a profound "affective disturbance" triggered by a severe expectancy violation (The Guardian).
By measuring subjects' responses using coded interviews and serial measurements of semantic differential ratings, alongside physiological markers of autonomic arousal such as galvanic skin responses, the researchers identified three core components of this psychological disturbance:
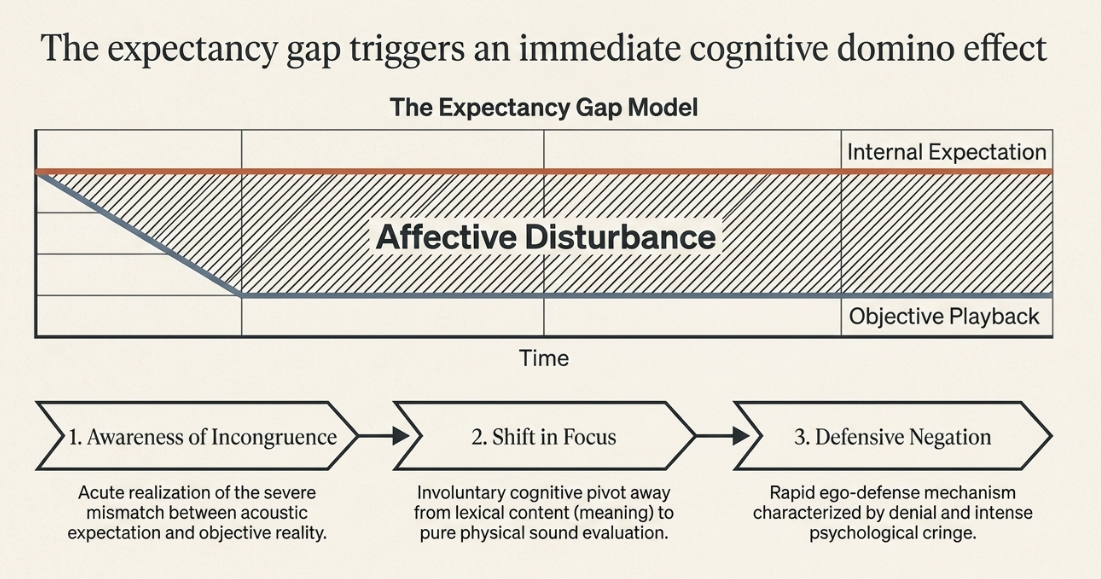
1. Awareness of Incongruence: Subjects became acutely and uncomfortably aware of the severe mismatch between their deeply held internal expectations of how their voices would sound and the actual, objective auditory experience of the recording (ResearchGate).
2. Shift in Focus: Upon hearing the recording, subjects immediately and involuntarily shifted their cognitive attention away from the lexical content of their speech (the actual meaning of the words they were saying) or their personological qualities, and fixated entirely on their objective vocal qualities (how they physically sounded) (ResearchGate).
3. Defensive Negation: Subjects exhibited a rapid, defensive psychological reaction, characterized by a defensive negation of the voice-confrontation experience. They frequently expressed discomfort in acknowledging the voice as their own, often reacting within seconds of playback with statements of denial (ResearchGate).
This intense reaction occurs because the human voice is not merely a tool for data transfer; it is a foundational pillar of personal identity. Over a lifetime, an individual builds an internal self-concept based heavily on their internal acoustic resonance. When the recorded voice sounds thinner, higher-pitched, or less authoritative than expected, it severely violates this internal self-concept. The jarring realization that one sounds different to the world-and perhaps less imposing or professional-than they do to themselves can lead to acute disappointment, embarrassment, and a feeling of lost authority. The Holzman and Rousey study posited that this phenomenon suggests the continuous activity of an internal "monitoring function" that subconsciously edits and oversees vocal expression, playing a massive role in personality theory and ego preservation (ResearchGate).
Vocal Implicit Egotism and Self-Enhancement
Interestingly, the aversion to one's own voice is almost entirely dependent on the conscious recognition of the voice. A fascinating and pivotal 2013 study conducted by evolutionary psychologist Susan Hughes explored the concept of "vocal implicit egotism"-a specialized form of subconscious self-enhancement (PubMed).
In this comprehensive experiment, 80 male and female participants were asked to rate the attractiveness of various recorded voice samples. Unbeknownst to the participants, recordings of their own voices had been secretly mixed into the stimulus array (PubMed). The researchers meticulously controlled the variables, testing across different stimulus types including isolated numbers, vowels, and complete words (Taylor & Francis).
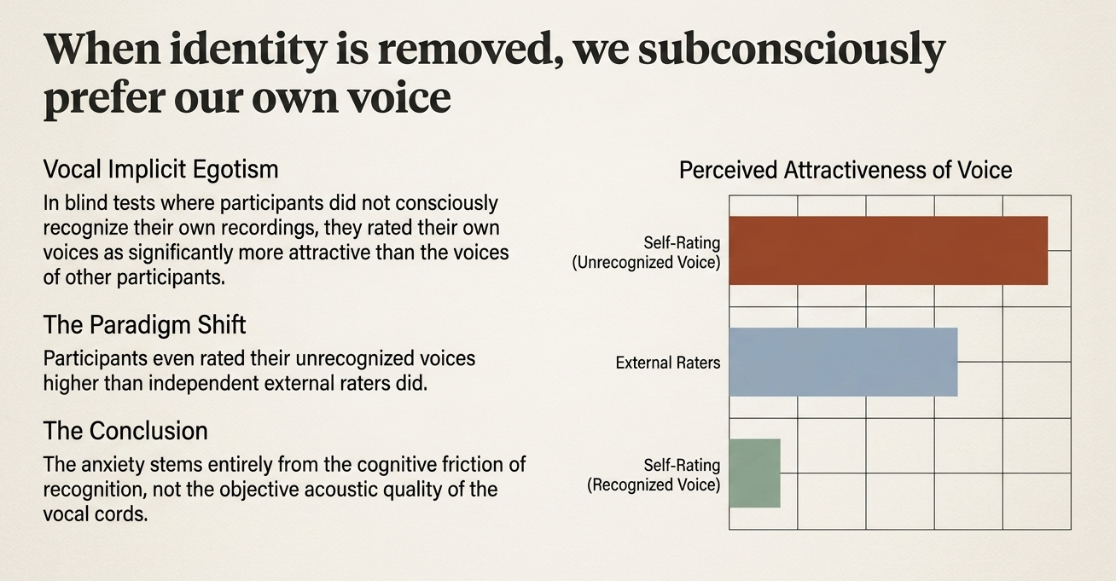
The results of the study were highly illuminating and entirely counterintuitive to the standard narrative of voice confrontation: when participants did not consciously recognize their own voices, they consistently rated their own voices as significantly more attractive than the voices of the other participants (PubMed). Furthermore, an a posteriori Tukey HSD statistical test revealed that participants rated their own voices as sounding significantly more attractive than did external, independent opposite-sex and same-sex raters (ResearchGate). This self-enhancement bias occurred robustly, irrespective of the gender of the speaker or the specific vocal stimuli used (Taylor & Francis).
These findings carry massive implications for the treatment of microphone anxiety. They clearly suggest that individuals do not inherently possess "bad," "annoying," or "unpleasant" voices, nor do they objectively hate the sound of their own vocal cords (Social Confidence Center). Rather, the psychological friction, the cringe, and the anxiety of voice confrontation stem entirely from the conscious recognition of the expectation gap (Social Confidence Center). Once the identity trigger is bypassed and the individual evaluates the acoustic signal objectively, they actually prefer the sound of their own external voice over others (Taylor & Francis).
Psychotherapeutic Frameworks for Microphone Anxiety
Because microphone anxiety and voice confrontation are sustained by an affective disturbance and profound cognitive fusion with negative self-evaluations, psychological interventions drawn from Acceptance and Commitment Therapy (ACT) and Cognitive Behavioral Therapy (CBT) are highly effective in treating the condition. Avoidance behaviors-such as refusing to listen to playbacks, declining speaking engagements, or relying exclusively on text-based communication-only serve to reinforce the anxiety loop by treating the recorded voice as a genuine psychological threat (Social Confidence Center).
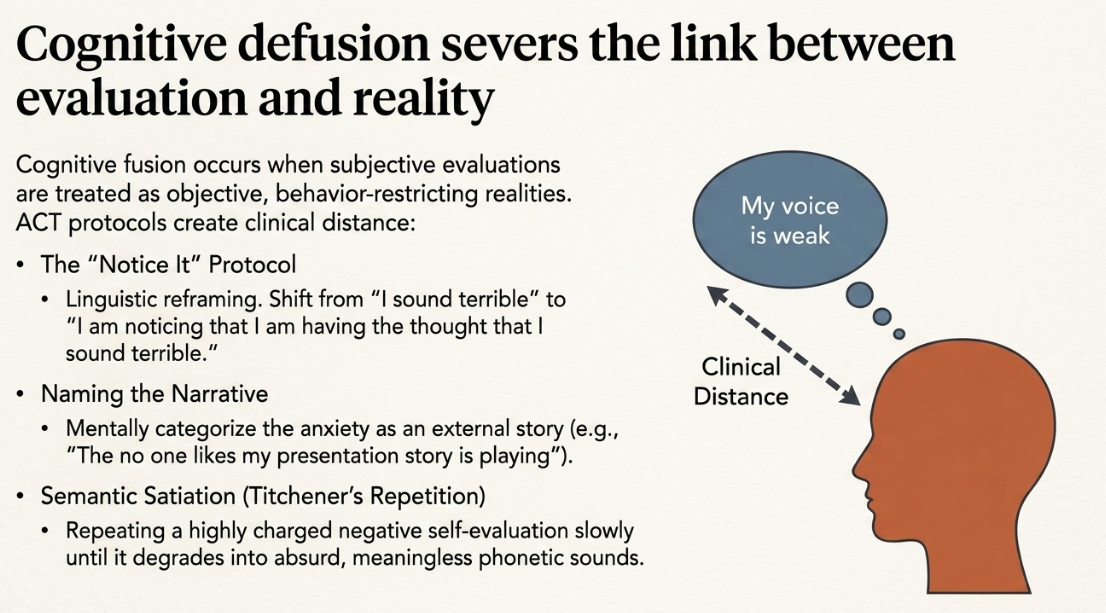
Cognitive Defusion (ACT)
When individuals experience voice confrontation, they frequently fuse with highly critical internal monologues, such as "My voice sounds weak," "I sound unintelligent," or "The audience is judging my tone." In the clinical framework of Acceptance and Commitment Therapy, the fundamental problem is not the semantic content of these thoughts, but the individual's psychological relationship to them. Cognitive fusion occurs when a speaker accepts an internal, subjective evaluation as an absolute, objective reality, allowing the thought to dictate and restrict their behavior (Providence).
Cognitive defusion is a specific psychological skill designed to detach, separate, and create clinical distance from these unhelpful thoughts. By systematically shifting the perspective from looking from the thoughts to looking at the thoughts, the speaker can drastically reduce the emotional impact of voice confrontation, allowing the thoughts to pass as mere neurological events rather than absolute truths (Providence).
Techniques for cognitive defusion in the context of microphone anxiety include:
The "Notice It" Protocol: Instead of engaging with the thought "I sound terrible on this recording," the speaker reframes the cognitive event by explicitly stating, "I am noticing that I am having the thought that I sound terrible" (University of Sydney). This linguistic shift inserts a critical layer of objective distance between the observing self and the self-evaluation.
Naming the Narrative: When anxiety arises during a recording session, the speaker can mentally categorize the experience by naming the internal narrative, such as, "Here is the 'I hate my voice' story again" or "The 'no one likes my presentation' story is playing" (University of Sydney).
Titchener's Repetition (Semantic Satiation): This exercise involves taking a highly charged negative self-evaluation and repeating it aloud very slowly until it completely loses its semantic meaning and becomes merely a series of absurd phonetic sounds, destroying the thought's emotional power (Association for Contextual Behavioral Science).
Externalizing the Mind: By treating the anxious inner critic as an external entity, a separate object, or even singing the anxious thought to a goofy melody, the speaker can observe the anxiety without being controlled by it (Cognitive Behavioral Therapy Los Angeles).
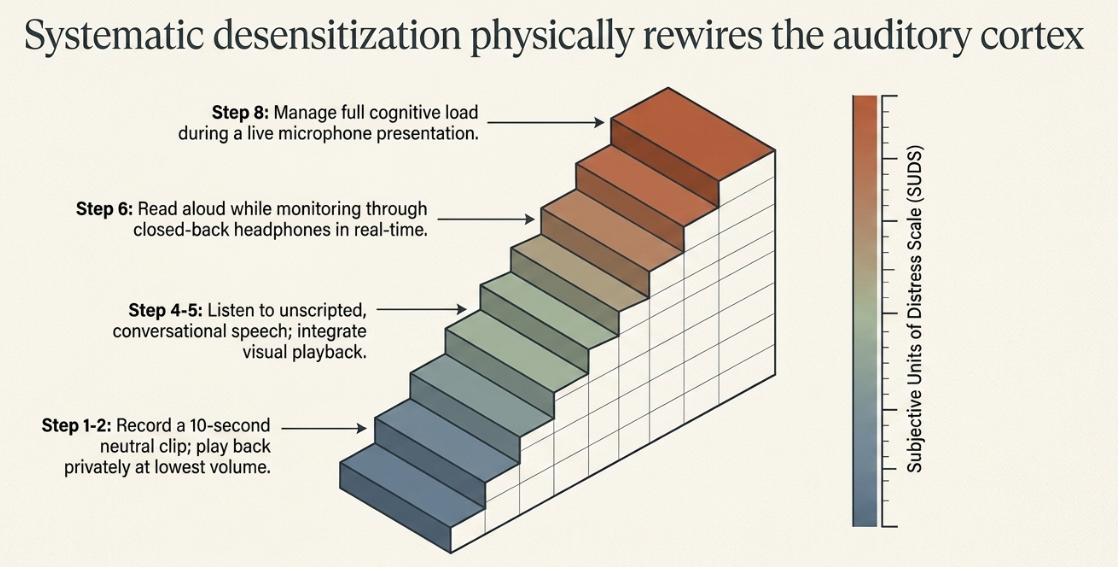
Systematic Desensitization and Exposure Hierarchies
Developed initially by psychiatrist Joseph Wolpe, systematic desensitization is an evidence-based behavioral intervention that utilizes classical counterconditioning principles to reduce phobias and anxiety disorders (Wikipedia). Because avoidance behaviors reinforce microphone anxiety, progressive, highly structured exposure to the feared stimulus (the recorded voice) is mandatory for lasting relief (Social Confidence Center).
Systematic desensitization operates in three distinct, methodical phases: identifying an anxiety stimulus hierarchy, learning physiological relaxation and coping mechanisms, and systematically exposing the subject to the triggers while maintaining physiological calm (Wikipedia). Research has shown that verbal presentations of anxiety-eliciting stimuli during desensitization generate measurable autonomic arousal (measured by galvanic skin response, cardiac rate, and blood pressure), proving that controlled exposure actively engages the nervous system to facilitate habituation (PubMed).
This methodology is so robust that it is routinely utilized in allied health sciences to treat hyperacusis-a condition where normal environmental sounds are perceived as intolerably loud. In clinical case studies, patients undergoing systematic auditory desensitization using recorded human voices and environmental sounds demonstrated improvements in their hearing thresholds by up to 40 dB, highlighting the brain's profound capacity to habituate to distressing acoustic stimuli through structured exposure (NSUWorks).
For a professional struggling with severe voice confrontation, a structured exposure fear ladder (graded exposure plan) must be utilized. The subject ranks each feared situation using the Subjective Units of Distress Scale (SUDS), beginning with mildly difficult exposures and progressing upward (University of Michigan Medicine). The individual does not progress to the next step until the current step no longer provokes a significant sympathetic nervous system response (University of Michigan Medicine).
By consistently engaging in these exposure exercises, the novelty of the external voice completely wears off. The speaker stops registering it as an alien sound and begins to process it objectively, much like an audio engineer mixing an instrument (Social Confidence Center).
Vocal Pedagogy and Biomechanical Optimization
While psychological acceptance of the recorded voice is necessary, speakers must also take proactive, biomechanical steps to optimize their vocal instrument. Psychological nerves frequently cause shallow breathing and muscular tension, which tightens the vocal cords, restricts airflow, and genuinely alters the acoustic output of the voice, making it sound strained, thin, or excessively high-pitched (Musicians Institute). Proper vocal pedagogy ensures that the voice being recorded is supported, rich, healthy, and authoritative.
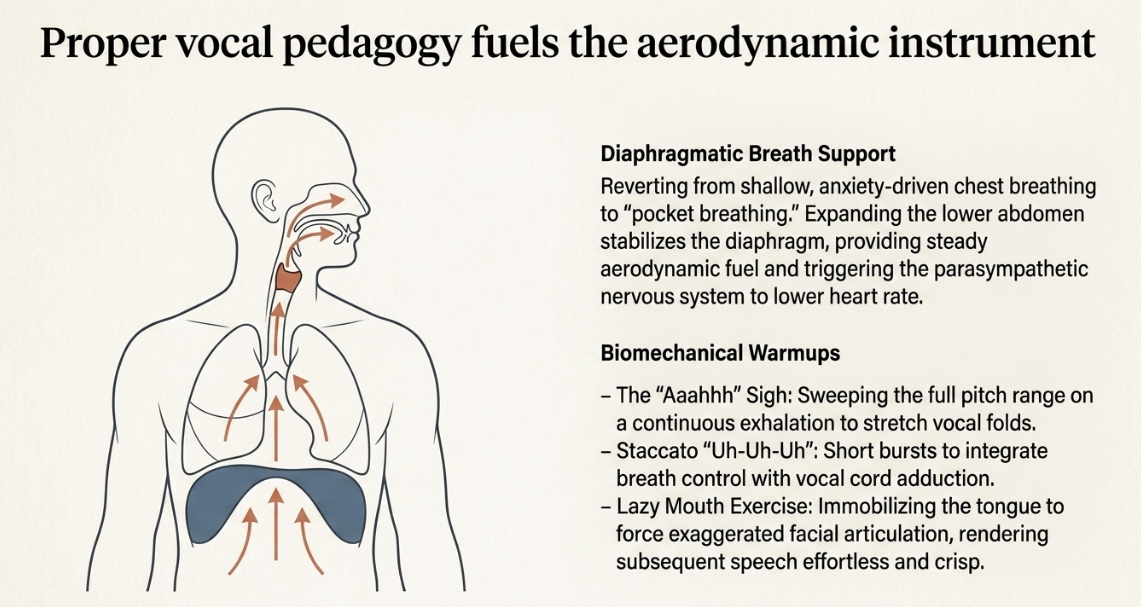
Diaphragmatic Breath Support
The human voice is essentially a highly complex wind instrument; sound is created only when a steady stream of air from the lungs passes between the vocal cords in the larynx, causing them to vibrate against one another (Musicians Institute). Inexperienced speakers and those suffering from microphone anxiety often revert to shallow chest breathing, driven by the sympathetic nervous system's fight-or-flight response. This shallow breathing fails to provide the necessary aerodynamic fuel for sustained phonation, resulting in a weak tone and a rapid loss of breath (School of Rock).
Diaphragmatic breathing, often referred to as "belly breathing" or "pocket breathing," is the absolute foundational technique utilized by professional voice actors, broadcasters, and opera singers across all voice types (School of Rock). By actively expanding the lower abdomen and engaging the lower lobes of the lungs during inhalation, the speaker stabilizes the diaphragm-a large, dome-shaped muscle located at the base of the lungs (School of Rock).
This technique serves multiple crucial purposes. First, it strengthens the abdominal muscles required to provide a controlled, steady exhalation that supports long phrases and prevents the voice from cracking or wavering (School of Rock). Second, engaging the diaphragm physically grounds the speaker, activating the parasympathetic nervous system, which actively lowers the heart rate and mitigates the physiological symptoms of anxiety (Oregon Ear, Nose & Throat Center). While it may feel unnatural initially to adults accustomed to chest breathing, consistent practice returns the body to its primal, highly efficient method of respiration (School of Rock).
Specialized Biomechanical Vocal Warmups
To counteract the restrictive effects of microphone nerves, speakers must utilize specific, targeted warm-up routines designed to relax the laryngeal muscles, engage the articulators, and expand the available vocal range prior to recording (MasterClass). Expert vocal coaches and broadcasting professionals rely heavily on a series of specialized exercises (Voices).
The 'Aaahhh' (Sigh) Technique: The speaker begins by taking a deep abdominal breath and exhaling into a silent sigh or low whisper, gradually adjusting the pitch from high to low (Voices). Following another deep breath, the speaker hums on a single continuous exhalation, sweeping from the lowest comfortable pitch to the highest, and back down again (Voices). This exercise gently stretches the vocal folds, increases immediate emotional expressiveness, and helps the speaker locate their full available pitch range before committing to speech (Voices).
The 'Uh-Uh-Uh' Staccato Technique: To integrate breath control directly with vocal cord adduction, the speaker exhales in short, sharp, staccato bursts, vocalizing the sound "uh-uh-uh" (Voices). By moving from projecting with tight vocal cords to speaking softly with loose cords, the speaker strengthens the lower end of the vocal register, warming up the instrument to access deeper, fuller tones for a richer acoustic profile (Voices).
The Enunciation Technique (Lazy Mouth Exercise): Nerves often lead to mumbled, rushed, or highly compressed speech. To combat this, the speaker sticks their tongue out as far as possible so it rests on the lower lip, and attempts to speak with the tongue completely immobilized (Voices). Because the tongue cannot be used for pronunciation, the speaker is forced to heavily exaggerate the movements of the jaw and facial muscles to remain intelligible (Voices). Once the tongue is retracted, normal articulation feels utterly effortless, sharp, and highly precise (Voices).
Lip Trills and Resonator Humming: Gently pushing air through closed lips to create a fluttering, motor-boat sound (lip trills) or humming at a natural frequency safely warms up the physical resonators in the face, nasal cavity, and chest (MasterClass). This ensures that the acoustic energy is directed forward through the mask of the face, rather than trapped in the throat.
Acoustic Engineering: Bridging the Psychoacoustic Gap
Even with perfect psychological acceptance, deep diaphragmatic support, and immaculate articulation, a raw audio recording inherently lacks the bone-conducted resonance the speaker expects to hear. However, through the sophisticated application of acoustic engineering, precise microphone placement, and digital signal processing, audio engineers can artificially reconstruct the warmth, depth, and spatial dimensions of the internal voice, making the playback significantly more comfortable, authoritative, and natural (Reddit).
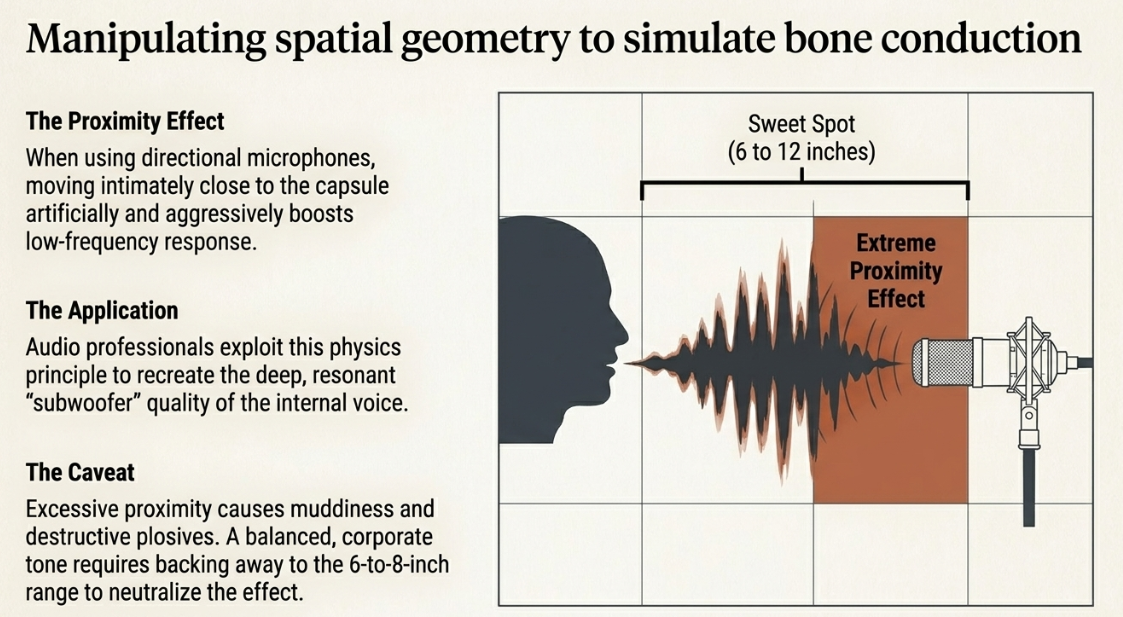
Microphone Placement and the Proximity Effect
The physical relationship and geometry between the speaker's mouth and the microphone capsule drastically alter the captured sound. The optimal "sweet spot" for most vocal recordings is generally positioned 6 to 12 inches (15 to 30 cm) from the microphone (Shure).
When utilizing directional microphones-such as those with cardioid or figure-8 polar patterns, which reject sound from the rear to isolate the voice-moving very close to the capsule triggers a phenomenon in acoustic physics known as the proximity effect (Shure). The proximity effect artificially and significantly boosts the low-frequency response of the microphone (Shure).
Audio professionals frequently exploit this physics principle to make a voice sound warmer, larger, more intimate, and incredibly rich-effectively simulating the deep, subwoofer resonance of bone conduction that the speaker misses in standard recordings (Reddit). However, this technique requires extreme caution. Excessive proximity effect can cause the voice to sound excessively muddy, boomy, or distorted, particularly if the speaker produces heavy plosives (bursts of air on 'P' and 'B' consonants) (Shure). If a speaker desires a highly formal, clean, and professional tone-such as for corporate e-learning narration or academic presentations-they must back away from the microphone to the standard 6-to-8-inch range to neutralize the proximity effect and present a balanced frequency response (Joe Passaro Voiceovers). For those who wish to avoid the proximity effect entirely, utilizing an omnidirectional microphone provides a flat bass response regardless of distance, though it requires a highly treated, silent recording environment (Mastering.com).
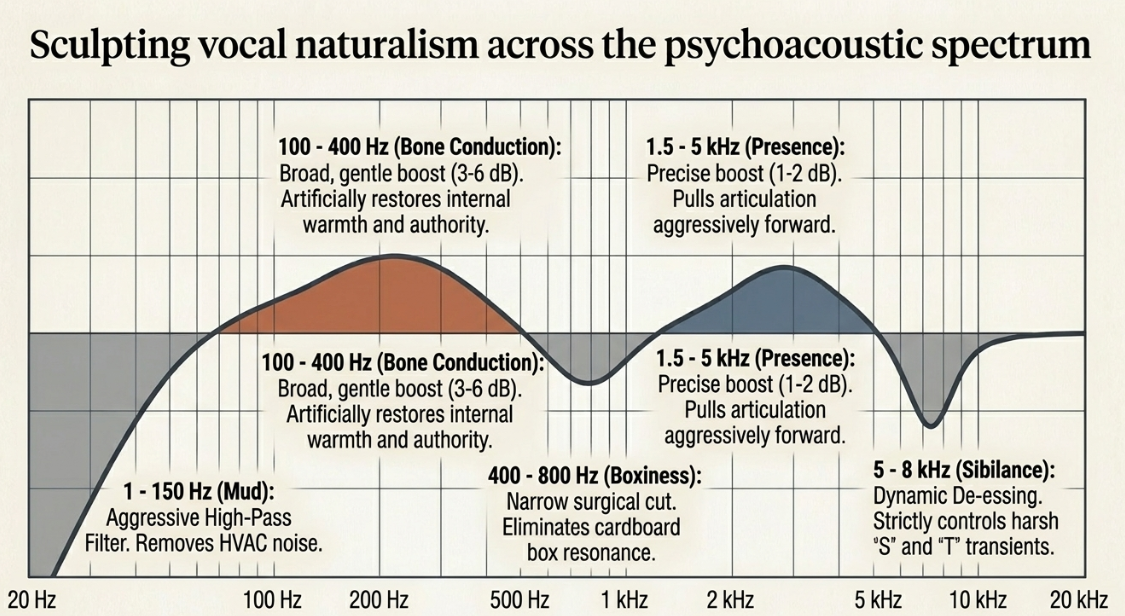
Equalization (EQ) Strategies for Vocal Naturalism
Equalization (EQ) allows an audio engineer to adjust specific frequency bands to surgically sculpt the tonal balance of the voice (Avid). Because the human skull acts as a complex acoustic filter that emphasizes low frequencies and dampens high frequencies, strategic, targeted EQ can seamlessly bridge the gap between air-conducted recordings and bone-conducted expectations (The International Tinnitus Journal).
A foundational, guiding philosophy in vocal EQ is to "boost wide, cut narrow" (Avid). Wide boosts gently affect a broader range of frequencies, improving warmth and presence in a highly musical and natural way, whereas narrow cuts are utilized to surgically locate and remove problematic resonances without stripping the voice of its fundamental character (Avid). Furthermore, engineers often utilize "harmonic feathering"-applying small, cumulative boosts to a fundamental frequency and its mathematical intervals (e.g., 120 Hz, 240 Hz, 360 Hz) to create a richer profile rather than relying on a single, unnatural gain spike (Pro Audio Files).
Dynamic Range Compression
Untrained speakers naturally fluctuate wildly in volume, getting overly loud when excited or emphasizing a point, and trailing off into a whisper at the ends of sentences. Dynamic range compression is a critical audio tool that automatically reduces the decibel span between the loudest and quietest parts of the audio, providing a highly consistent, punchy, and professional broadcast sound (JustAskJimVO).
However, heavy or improper compression can sound brutally artificial, stripping the voice of emotion and creating a suffocating "radio DJ" effect (JustAskJimVO). For natural-sounding voiceovers, the compressor must be tuned to allow the vocal's inherent human dynamics to breathe (Sonarworks Blog). Standard parameters for natural processing involve a modest Ratio (between 2:1 and 4:1) to control peaks without violently squashing expression, and a moderate Attack time (10-20 ms) to allow the natural, sharp transients of consonants to punch through before the compressor clamps down (Sonarworks Blog). The Release time (50-150 ms) should mirror the natural acoustic decay of human speech phrases (Sonarworks Blog). The Threshold is typically set to achieve roughly 3 to 6 dB of gain reduction only on the loudest peaks, followed by a touch of makeup gain to match the unprocessed volume level (Sonarworks Blog). Crucially, any equalization boosts for warmth or presence should typically be applied after compression, ensuring the compressor does not overreact to the boosted frequencies (Pro Audio Files).
Room Tone, Reverb, and Psychoacoustic Space
Finally, the acoustic environment deeply influences how a voice is perceived by both the speaker and the listener. A completely "dry" recording-one with zero room reflections, reverberation, or processing-can sound highly sterile, unnervingly unnatural, and psychologically suffocating to the speaker, as human beings never hear voices in a true acoustic vacuum (Simon Fraser University). Conversely, a highly "wet" signal recorded in an untreated, echo-heavy room sounds distinctly unprofessional, distant, and amateurish (Simon Fraser University).
The human brain utilizes reverberation as a primary psychoacoustic cue for spatial and distance perception, subconsciously analyzing the ratio between direct acoustic energy and indirect reflected sound (Simon Fraser University). To make a recorded voice sound comfortable, authoritative, and situated in reality, audio engineers utilize controlled room tone (iZotope). Even when a vocal is meticulously recorded in a deadened isolation booth, mixing in a highly subtle, incredibly short room reverb (with a decay time of less than 1 second) provides a crucial sense of dimension and spatial verisimilitude, anchoring the voice in a realistic physical space (Sonarworks Blog). Utilizing tools like mid/side equalization and high-pass filters on the reverb sends (specifically removing frequencies below 500Hz from the reverb tail) ensures that the spatial effect adds life and width without muddying the crucial low-end warmth of the primary vocal track (Reddit). For those recording in highly compromised home environments, modern Al-powered noise reduction and de-reverberation plugins-such as AutoTune Vocal Prep or Waves Clarity Vx DeReverb-analyze the recording using neural networks to strip away harsh room reflections and HVAC noise without degrading the core vocal tone, creating a pristine canvas for subsequent processing (YouTube).
Professional Development and Structured Support Ecosystems
For individuals seeking to permanently conquer microphone nerves and achieve mastery over their recorded output, theoretical knowledge of anatomy and acoustic engineering must be paired with structured, rigorous practical application. Joining a professional support group, enrolling in specialized adult education, or securing bespoke coaching provides the necessary environment for systematic desensitization to occur safely. The extensive ecosystem of voice training available in metropolitan hubs like London serves as a premier, comprehensive model for the types of interventions available to professionals globally.
Peer-Led Practice Environments: Toastmasters International
Toastmasters International operates a massive global network of non-profit clubs specifically designed to build public speaking confidence through rigorous peer evaluation and regular, structured practice (Toastmasters International). In an environment completely devoid of professional risk or corporate consequence, members deliver prepared speeches, respond rapidly to impromptu speaking prompts (Table Topics), and receive highly constructive, structured feedback from their peers (Toastmasters International).
The London area hosts dozens of highly specialized chapters, catering to various schedules, geographic locations, and professional demographics. This peer-led model is incredibly effective for exposure therapy, as it continuously forces the individual into their "fear hierarchy" on a routine basis, transforming the act of speaking from a rare, high-stakes event into a mundane, practiced skill (Social Confidence Center).
Institutional Voice and Speech Workshops
For individuals requiring rigorous, highly technical anatomical instruction rather than just peer practice, institutional adult education centers offer targeted curricula. City Lit, based in Covent Garden, provides some of the most comprehensive adult voice training in Europe, utilizing specialized performance studios, digital media suites, and expert tutors who hold MA degrees in Voice Studies from the prestigious Royal Central School of Speech and Drama (City Lit).
Their curriculum is systematically divided into specific pathways to address different facets of vocal delivery, making it ideal for targeting precise technical weaknesses that cause microphone anxiety (City Lit).
Drama-Based Interventions and Psychological Coaching
For individuals whose microphone nerves are deeply rooted in severe social anxiety, impostor syndrome, or extreme introversion, traditional mechanical speech coaching may be insufficient. Organizations like Making Moves in Central London utilize a highly adapted form of drama therapy known as the Sunflower Effect. Rather than teaching mechanical speaking techniques or rigid rules of posture, these courses (such as the "Breakthrough" and "Express Yourself" workshops) address the deep psychological blocks that keep quieter individuals trapped in a cycle of self-consciousness. By bypassing the logical, critical brain through improvisation, character work, and dramatic play, participants build genuine, embodied confidence that translates directly and powerfully to public speaking and microphone recording (Making Moves).
Similarly, executive communication coaching firms like London Speech Workshop and independent practitioners such as Alan Woodhouse focus heavily on the intersection of deep psychology and physical voice production. They frame voice work practically as "taking the voice to the gym," emphasizing that true gravitas, absolute pace control, and managing the intense physiological arousal of nerves require dedicated, physical repetition and highly tailored, evidence-based guidance (London Speech Workshop). By combining the science of speech with the discipline of performance, these coaches ensure that the sounds a professional makes have a fighting chance of living up to their own high internal expectations (Alan Woodhouse).
Conclusion
The intense discomfort associated with hearing one's own recorded voice-and the subsequent, often crippling microphone anxiety it produces-is not an indication of a poor vocal instrument, nor is it a personal failing. It is, rather, a perfectly natural, entirely predictable collision of human anatomy and psychology. Physiologically, the absolute absence of bone-conducted, low-frequency acoustic energy in standard audio recordings guarantees that the external voice will sound jarringly different from the speaker's internal perception. Psychologically, this sudden expectation gap triggers a profound affective disturbance within the ego, leading rapidly to defensive negation, acute self-consciousness, and cognitive fusion with feelings of professional inadequacy.
However, empirical, controlled evidence definitively demonstrates that this aversion is a trick of the brain. When the psychological bias of self-recognition is carefully removed in laboratory settings, individuals actually rate their own voices as highly attractive and authoritative. Overcoming microphone nerves, therefore, does not require the speaker to fundamentally or surgically change their voice, but to systematically, patiently, and scientifically change their relationship to it.
By employing evidence-based cognitive defusion techniques to safely detach from the internal critic, and by committing to a graded exposure hierarchy through systematic desensitization, speakers can entirely neutralize the affective disturbance of voice confrontation. When this newfound psychological resilience is combined with strong, diaphragmatic breath support, targeted anatomical vocal warm-ups, and the strategic, highly considered application of acoustic engineering-utilizing the proximity effect, subtractive equalization, dynamic compression, and psychoacoustic room tone to faithfully recreate natural warmth-the microphone ceases to be a source of anxiety or dread. Ultimately, through structured practice in peer-led or professionally coached ecosystems, the recorded voice transitions from an alien, threatening stimulus into a mastered, deeply familiar, and highly effective tool for professional communication.











