
The Fundamental Nature of High-Frequency Distortion in Audio Reproduction
Sibilance represents one of the most pervasive, complex, and frustrating acoustical phenomena encountered in the disciplines of linguistics, psychoacoustics, and audio engineering. At its core, sibilance is a specialized class of fricative consonant sound characterized by intense, high-frequency acoustic energy. In human speech, sibilants primarily manifest in the pronunciation of consonants such as 's', 'z', 'sh', 'ch', 'f', and 't' Sage Audio. While these sounds are absolutely foundational to phonetic articulation, linguistic clarity, and human communication, they possess an inherent acoustic density in the upper midrange and high-frequency spectrums that frequently translates into harsh, piercing, and disproportionately loud sonic artifacts during audio recording and digital reproduction Sage Audio.
The intrinsic difficulty in managing sibilance arises from a deeply interwoven intersection of human articulatory anatomy, aerodynamic physics, transducer electro-mechanics, and the evolutionary biology of human hearing. Unlike a low-frequency plosive—which is essentially a localized, low-frequency burst of kinetic air pressure that can be easily dispersed with a physical mesh barrier—sibilance is sustained, turbulent aerodynamic noise that fundamentally excites the most sensitive regions of the human auditory system. Furthermore, the modern aesthetic of audio production, which heavily favors intimately close-miked, hyper-compressed, and spectrally bright vocal presentations, inherently magnifies these high-frequency artifacts Sage Audio. When a vocal performance is captured by a highly sensitive microphone, the natural sibilant frequencies are frequently exaggerated by proximity effects, inherent transducer capsule resonances, preamplifier distortion, and the subsequent dynamic compression applied during the mixing phase Bobby Owsinski Blog.
First, it must be noted that the appearance of sibilance is highly variable across different human voices; in many singers, its disruptive presence may be entirely negligible. A common axiom in audio engineering dictates that if the sibilance is not actively distracting from the overall vocal track, intervention should be avoided, as corrective processing inherently risks dulling the broader vocal tone. Sibilance is not inherently a vocal defect or a physiological problem; it is a natural, requisite component of human speech and singing. However, certain anatomical variations, such as a whistling sibilant—where air escapes over the teeth in a specific manner that creates a sharp, concentrated tonal whistle during 's' and 'z' sounds—can be classified as a minor speech impediment that requires drastic technical intervention.
Resolving excessive sibilance requires an exhaustive, multi-disciplinary understanding of how high-frequency fricatives are generated within the human vocal tract, how they physically interact with microphone diaphragms and room environments, how the human auditory cortex perceives them, and how modern digital signal processing (DSP) algorithms can manipulate their spectral properties. This comprehensive report provides an exhaustive analysis of sibilance, progressing from its acoustic origins to advanced algorithmic mitigation, delivering actionable, highly technical frameworks for audio professionals, acousticians, and vocalists.
The Acoustics, Aerodynamics, and Phonetics of Fricative Generation
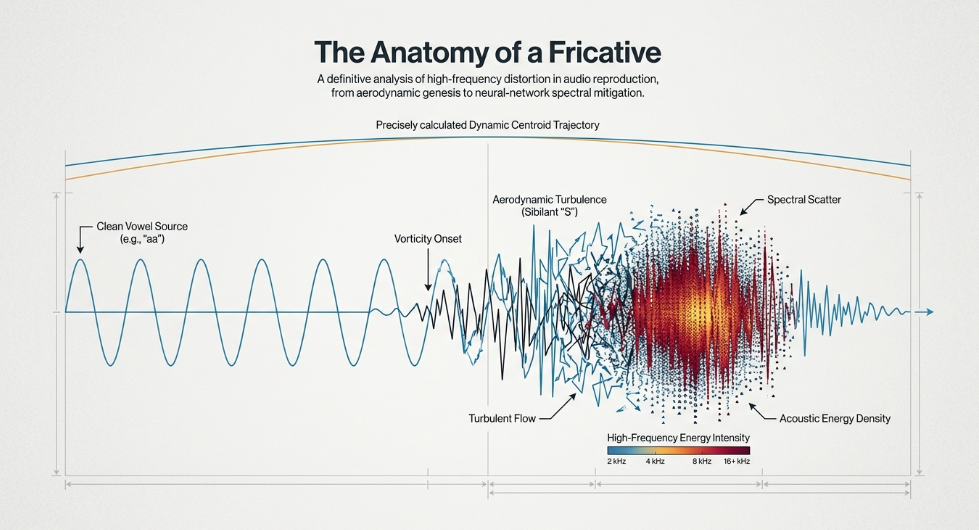
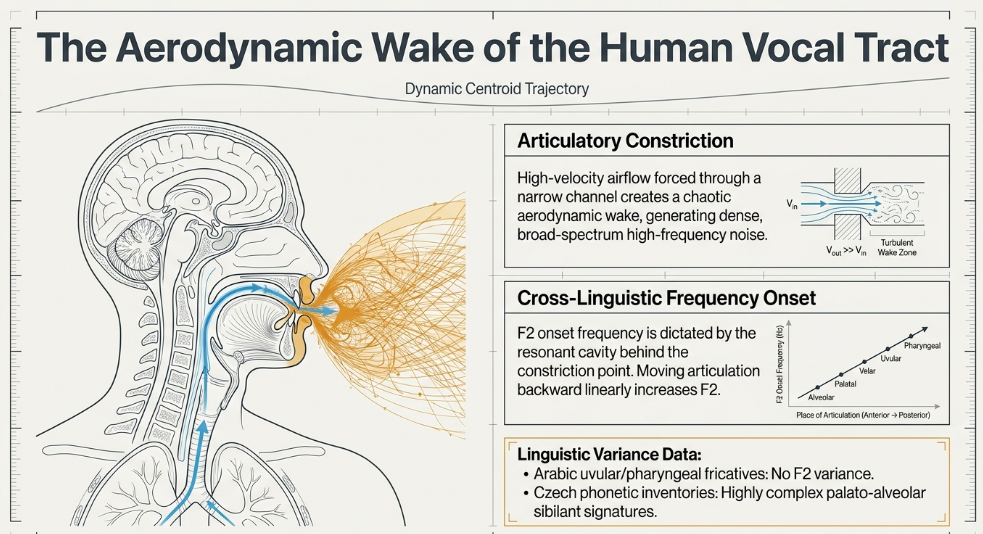
To successfully mitigate sibilance, it is a prerequisite to understand the biomechanical and aerodynamic processes that actively generate it. Sibilant fricatives are produced by forcing a continuous stream of air from the lungs through a highly constricted, narrow channel within the vocal tract, typically formed by pressing the tongue against the alveolar ridge or the hard palate. This high-velocity airflow violently strikes the teeth, creating a turbulent, chaotic aerodynamic wake that generates dense, broad-spectrum high-frequency noise.
Articulatory Mechanisms and Cross-Linguistic Frequency Distribution
The precise acoustic signature, bandwidth, and center frequency of a sibilant are dictated primarily by the physical location of the articulatory constriction and the resulting size of the resonant cavity located anteriorly (in front of) the constriction point. Comprehensive acoustic analyses of the F2 onset frequency—measured precisely at the transition point from a fricative consonant into the subsequent following vowel—reveal that resonances are heavily affiliated with the cavity positioned directly behind the constriction. Consequently, a more posterior (backward) articulatory constriction results in a fundamentally higher F2 transition frequency KU.
As the place of articulation moves sequentially backward deeper into the vocal tract—progressing from labiodental, to dental, to alveolar, and finally to post-alveolar positions in the English language—the F2 onset frequency generally increases in a predictable, linear fashion. However, cross-linguistic studies demonstrate that this exact pattern does not universally extend to all phonetic inventories. For instance, in Arabic, detailed spectrographic analysis reports no statistically significant difference in F2 onset frequency between deeper uvular and pharyngeal fricatives. Conversely, languages such as Czech possess highly complex sibilant inventories that contrast across three highly specific places of articulation: alveolar, pre-post-alveolar, and palato-alveolar, each generating a unique high-frequency dispersion pattern Frontiers.
The Dynamic Trajectory of the Centroid Frequency
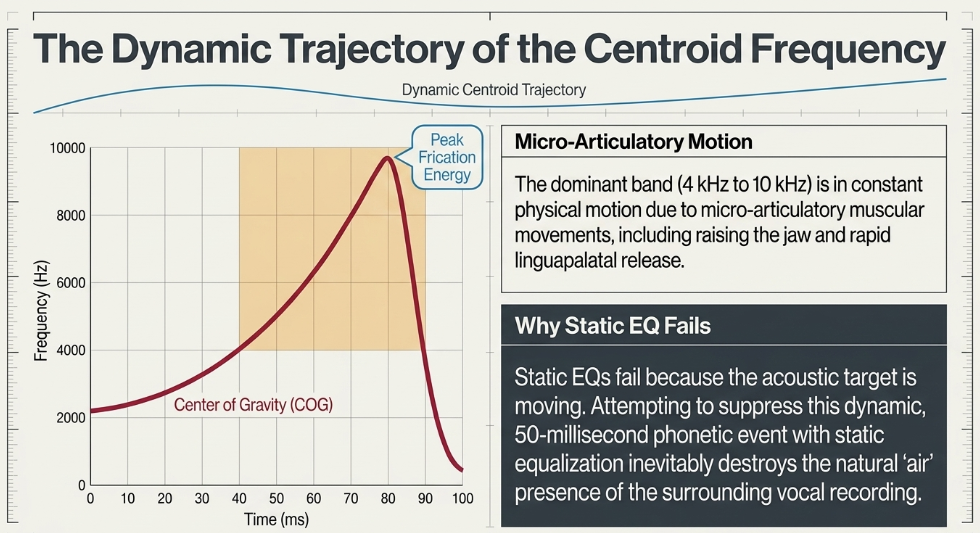
The dominant frequency band of a standard English 's' sound typically lies somewhere between 4 kHz and 10 kHz, occasionally dropping as low as 1.5 kHz or 2 kHz depending on the specific combination of vocalist anatomy and microphone characteristics. However, a critical misconception in audio engineering is the assumption that sibilance exists as a static, immovable frequency peak. Advanced spectrographic studies have conclusively proven that the exact center of this energy—known as the Center of Gravity (COG) or the centroid frequency—is highly dynamic and constantly shifting throughout the duration of the consonant PMC.
In adult productions of the /s/ phoneme, the centroid frequency does not remain static; instead, it follows an increasing, highly concave trajectory across the temporal course of the fricative PMC. The frequency rises steadily from the onset of the consonant, reaching a global maximum peak at approximately 80% of the fricative's total duration, before rapidly falling off just prior to the release of the constriction and the transition into the vowel PMC.
This complex temporal variation in the centroid frequency directly corresponds to micro-articulatory muscular movements, specifically the physical raising of the jaw across the first half of the frication process, followed by the rapid muscular release of the linguapalatal constriction near the absolute end of the frication PMC. Psychoacoustic experiments utilizing concatenated high- and low-COG /z/ syllables, matched with specific vowel portions and tapered precisely over 50-millisecond periods to emulate the natural rising amplitude characteristics of fricatives, further demonstrate how the Long-Term Average Spectrum (LTAS) of these sounds heavily influences listener perception PMC. Because these spectral features are fluid, highly complex, and in constant physical motion, rudimentary static acoustic models and basic static equalization are woefully insufficient to characterize or effectively mitigate /s/ sounds without inflicting collateral damage on the surrounding audio PMC. The dynamic, moving nature of the COG explains why simple static EQ cuts often fail to control sibilance without simultaneously destroying the natural "air" and presence of the vocal recording.
Psychoacoustics: The Evolutionary Biology of the Human Auditory Response
The primary reason sibilance is universally perceived by human beings as disproportionately loud, abrasive, harsh, or physically "piercing" is not merely a technical artifact of modern recording equipment. Rather, it is a fundamental, hardwired characteristic of human evolutionary biology and auditory anatomy. Sibilance weaponizes the most efficient frequency bands of the human ear against the listener.
Outer Ear Anatomy and Helmholtz Resonance Amplification
The human auditory system does not process sound linearly; it acts as a highly specialized, non-linear acoustic filter. Sound waves first interact physically with the pinna (the external, visible cartilage of the outer ear), which functions as a complex, biological acoustic horn and an impedance-matching device for sound pressure entering the meatus, or ear canal. The intricate ridges and shape of the pinna create micro-reflections that provide the brain with critical up/down spatial localization cues, particularly for extremely high-frequency transients.
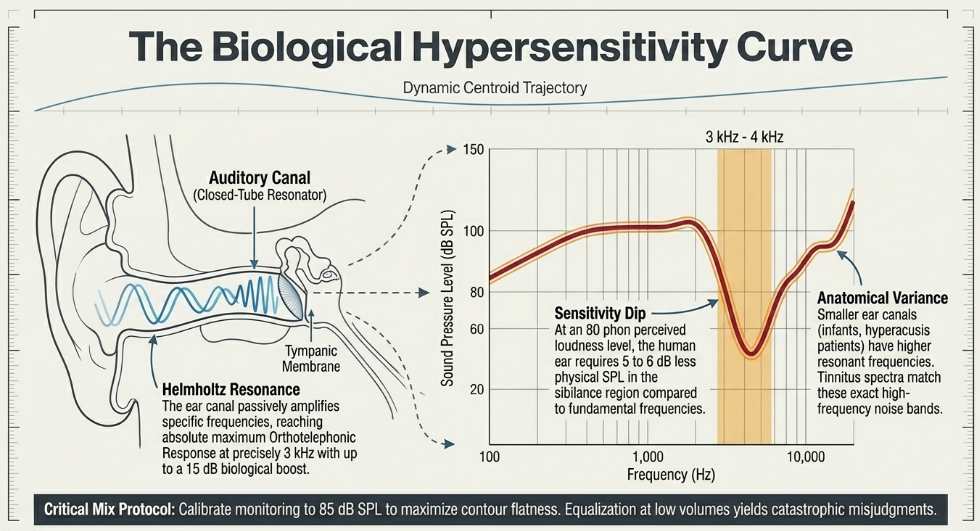
More critical to the perception of sibilance, however, is the meatus itself. The human ear canal physically functions as an acoustic tube closed at one end by the highly sensitive tympanic membrane (eardrum). This specific cylindrical physical structure creates a biological Helmholtz Resonance—an acoustic phenomenon where the enclosed volume of air within the canal naturally and passively amplifies specific incoming frequencies. The total response from an idealized on-axis free-field point source to the eardrum is known as the Orthotelephonic Response.
Due to the length and volume of the average adult meatus, the sound pressure level striking the eardrum is markedly enhanced for frequencies ranging broadly between 1.5 kHz and 6 kHz, with the absolute maximum biological enhancement occurring precisely at 3 kHz UC Davis Mathematics. At this 3 kHz resonant peak, the physical amplification can reach an astounding 15 dB. This natural, evolutionary resonance provides a critical signal-to-noise advantage for discerning the subtle, high-frequency transients of speech consonants in noisy environments, allowing human beings to communicate effectively and identify potential threats. However, this exact evolutionary advantage renders the human ear acutely and painfully hypersensitive to the concentrated, artificially amplified energy of sibilant fricatives.
Anatomical Variance, Hyperacusis, and Tinnitus Correlations
The physical dimensions of the ear canal strictly dictate the specific resonant frequencies and the degree of amplification. Individuals with smaller ear canals, such as infants and small children, possess inherently higher resonant frequencies and are consequently far more sensitive to, and bothered by, loud, high-pitched acoustic energy Resonance Hearing Clinic.
This anatomical variance is also directly linked to audiological pathologies such as hyperacusis—a condition defined by an extreme sensitivity to, and physical discomfort caused by, specific everyday acoustic stimuli, almost universally high-pitched sounds Resonance Hearing Clinic. Hyperacusis is frequently observed in individuals with smaller ear canal volumes, and these individuals are simultaneously more susceptible to long-term noise-induced hearing loss due to this localized biological amplification Resonance Hearing Clinic.
Furthermore, extensive research into the perceptual components of chronic tinnitus—auditory sensations perceived in the absolute absence of an external acoustic stimulus—reveals fascinating parallels to sibilance. When subjects with high-frequency hearing loss map their internal tinnitus spectra, the resulting psychometric data reveals broad peaks that fall directly within their specific hearing loss ranges PubMed. The data suggests that tinnitus sensations closely resemble the exact acoustic profile of high-frequency noise bands, occasionally with superimposed tonal pitches PubMed. The neural fatigue and auditory trauma associated with these specific frequency bands underscore exactly why unmitigated sibilance in a commercial audio recording is perceived as highly fatiguing, distracting, or even physically painful to the end listener.
When attempting to protect the ear from these frequencies, introducing standard foam earplugs into the canal fundamentally destroys the natural ear canal resonance, resulting in a muffled, unnatural frequency response Resonance Hearing Clinic. Specialized acoustic protection, such as Etymotic Research ETY plugs or custom-molded ER 15s, utilize tuned acoustic resonators and acoustic resistors to carefully replicate the frequency response of the average ear canal, preserving the natural orthotelephonic response while reducing overall amplitude Resonance Hearing Clinic.
Equal-Loudness Contours and the Fletcher-Munson Paradigm
The psychoacoustic perception of sibilance is formally, mathematically quantified by equal-loudness contours, historically known as the Fletcher-Munson curves, and currently standardized globally under the ISO 226:2003 specification CSS Audio. These complex contours map the specific sound pressure level (SPL) required across the entire frequency spectrum for an average human listener to perceive a constant, flat loudness when presented with pure steady sine wave tones Wikipedia.
The original curves were determined experimentally by Harvey Fletcher and Wilden A. Munson and published in a landmark 1933 paper in the Journal of the Acoustical Society of America titled "Loudness, its definition, measurement and calculation" Wikipedia. The unit of measurement established for perceived loudness levels is the phon Wikipedia. By strict definition, a 1 kHz reference tone played at precisely 70 dB SPL measures exactly 70 phons. If a 1 kHz tone is pushed to a deafening 105 dB SPL, it measures 105 phons iZotope.
Analysis of the updated ISO 226:2003 curves reveals drastic, extreme non-linearities in human hearing perception across the frequency spectrum. To read the graph, the Y-axis represents physical SPL (decibels), and the X-axis represents frequency (Hertz) CSS Audio. To achieve an equal perceived loudness of 80 phons, low frequencies require massive physical energy. For a 100 Hz tone to sound equally as loud as a 1 kHz tone at 80 dB SPL, the 100 Hz tone must be amplified to approximately 90 dB SPL iZotope. Similarly, a 50 Hz tone must hit roughly 83 dB SPL CSS Audio.
Conversely, observing the 3 kHz to 4 kHz region—the exact fundamental domain of sibilant presence—the equal-loudness contour dips severely UC Davis Mathematics. This dip physically proves that the ear requires a significantly lower physical SPL to perceive these frequencies as equally loud iZotope. At 80 phons, this sensitivity dip is roughly 5 to 6 dB deep.
However, the non-linearity becomes exponentially more extreme at lower listening volumes. For instance, at a quiet listening level of 20 phons, a 100 Hz tone requires a massive 25 dB increase to match the perceived volume of a 1 kHz tone, while the sensitivity to the 3 kHz to 4 kHz sibilance region remains acutely pronounced iZotope.
The implications of the Fletcher-Munson and ISO 226:2003 curves for audio mixing and mastering are profound. Because human hearing is intensely hyper-sensitive to the 3 kHz to 8 kHz range, any unnatural emphasis placed on these frequencies by close-miking or dynamic compression will be perceived as an aggressive, physically abrasive assault on the ear. Furthermore, because the shape of the equal-loudness contour changes drastically depending on the playback volume, making equalization decisions regarding sibilance at low monitoring volumes is highly dangerous Reddit. At low volumes, the human ear acts somewhat like a midrange-focused Auratone speaker, masking the low-end and highlighting the mid-to-high frequencies Reddit. For this reason, professional mixing engineers are heavily advised to mix and de-ess at a consistent, calibrated monitoring level—often around 85 dB SPL—which maximizes the flatness of the equal-loudness contour while remaining safe for extended exposure, preventing critical misjudgments regarding the balance of high-frequency sibilance versus low-frequency fundamental tones Reddit. Amplifiers intended for consumer playback often feature a "loudness" compensation button designed specifically to boost low and high frequencies at low listening volumes, attempting to artificially flatten this equal-loudness contour and prevent the sound from being entirely dominated by mid-frequency sensitivity Wikipedia.
Pre-Transducer Mitigation: Vocal Pedagogy and Source Control
The absolute most effective, sonically transparent, and artifact-free method for managing sibilance occurs in the physical world, long before the acoustic energy ever interacts with an electromechanical microphone diaphragm. High-frequency acoustic sounds are inherently highly directional; they project forward and downward from the human mouth in a tightly focused beam. Mitigating this physical beam requires a combination of vocal pedagogy, physiological awareness, and acoustic maneuvering.
Vocal Mechanics, Articulatory Modification, and Speech Therapy
Sibilance is, in many respects, a learned articulatory habit and a mechanical way of speaking, rather than an immutable physiological trait, and vocalists can be trained by vocal coaches to minimize its severity without compromising their diction. Voice actors, broadcast professionals, and singers utilize specialized warm-ups and Semi-Occluded Vocal Tract (SOVT) exercises to improve diaphragmatic breath support and relax the rigid articulatory muscles, which can significantly soften the abrasive, turbulent edges of fricative consonants before they are recorded.
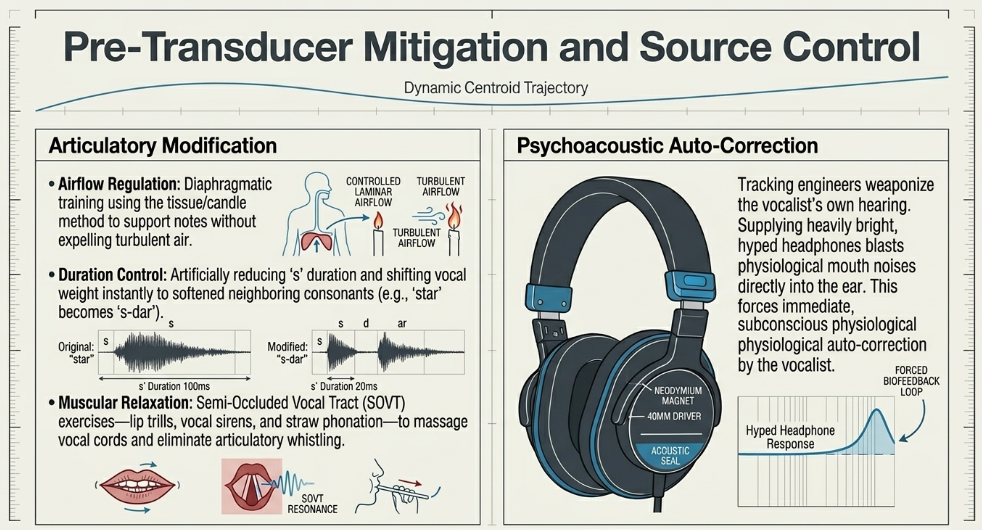
Airflow Regulation and Diaphragmatic Support: One highly effective diagnostic and training technique involves holding a tissue or a lit candle directly in front of the mouth. The vocalist practices articulating highly sibilant words while attempting to produce the exact same sound with minimal breath expulsion, ensuring the tissue or flame barely moves Reddit. This trains the diaphragm to support the note without pushing excess, uncontrolled turbulent air through the dental constriction. Deep belly breathing for 3 to 5 minutes prior to performance establishes this foundation Voice Acting Institute.
Consonant Substitution and Duration Control: Singers are frequently trained to artificially reduce the duration of the letter 's' by sustaining the neighboring vowels for longer periods and quickly but gently rolling off breath pressure during the fricative transition Reddit. Alternatively, emphasis can be dynamically shifted to the neighboring consonant. For example, when singing the word "star," the vocalist initiates a brief 's' position, but the moment sound is produced, the vocal weight is instantly transferred to a softened 't' or 'd' sound, resulting in a phonetic delivery that resembles "s-dar" Reddit.
SOVT and Muscular Relaxation: Voiceover and dubbing work requires immense facial dynamic expression and precise articulation. Exercises such as lip trills (buzzy motorboats), vocal sirens sweeping from lowest to highest pitch, humming on mid-range notes, and straw phonation (humming through a straw into a cup of water for 5 minutes) physically massage the vocal cords, tune the vocal resonance, and prevent the articulatory stiffness that often exacerbates high-frequency whistling during speech Voice Acting Institute. Pitch glides and the yawn-sigh technique further drop the larynx and open the throat, reducing the high-frequency constriction Voice Acting Institute.
Psychoacoustic Self-Correction via Headphone Monitoring
A sophisticated technique employed by high-level tracking engineers involves weaponizing the vocalist's own hearing against their sibilance. It is critical that vocalists practice and track using closed-back headphones specifically utilizing the exact microphone setup that will be used for the recording Reddit.
Engineers will often provide the vocalist with intentionally bright, heavily hyped headphones—such as the industry-standard Sony MDR-7506 Reddit. Because these specific headphones possess a massive spike in the high-frequency spectrum, any excessive sibilance generated by the vocalist is blasted directly into their ears with impossible-to-ignore intensity Reddit. By practicing with no accompaniment, the vocalist is forced to hear their own physiological mouth noises, clicks, and sibilance, prompting an immediate, subconscious physiological auto-correction Reddit. If an engineer can capture a take where no sibilance triggers through hyped 7506 headphones, the source audio is virtually guaranteed to be flawlessly clean Reddit.
Physical Proximity, Acoustic Deflection, and Axis Orientation
If vocal technique cannot be altered, microphone placement becomes the foremost engineering defense against sibilance. Because sibilant energy relies on high-velocity air pressure and high-frequency acoustic directionality, physically manipulating the geometric relationship between the sound source and the transducer drastically alters the captured signal URM Academy.
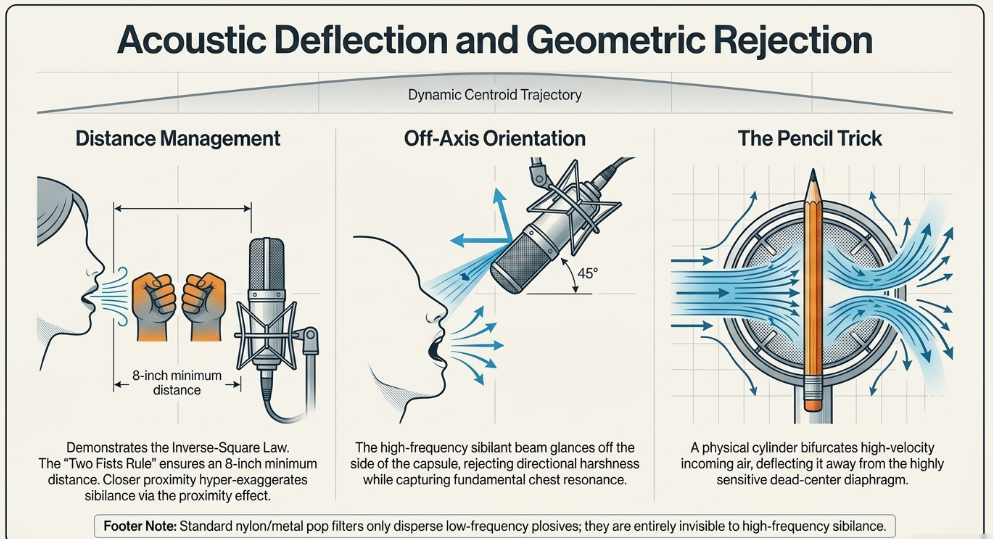
Distance Management and the Inverse-Square Law: The inverse-square law of acoustics dictates that sound energy dissipates rapidly over distance. Physically moving the vocalist further away from the microphone is critical. For highly sensitive condenser microphones, an absolute minimum distance of roughly 8 inches is strongly recommended. A standard industry tracking practice is the "Two Fists Rule": placing one fist between the microphone capsule and the pop filter, and a second fist between the pop filter and the singer's mouth to guarantee proper spacing. Distances closer than this hyper-exaggerate not only sibilance but also low-frequency plosives due to the proximity effect, heavily compressing the air against the transducer and hyping unnatural, resonant artifacts. If moving the vocalist back 6 to 12 inches introduces too much unwanted room ambiance or reverberation, the physical recording environment must be acoustically treated.
Off-Axis Orientation: Because sibilant high frequencies beam straight outward and slightly downward from the human mouth, placing the microphone directly in the line of fire guarantees maximum harshness. Off-axis placement is widely considered the easiest and most effective engineering technique. This involves adjusting the microphone so it sits slightly above the level of the vocalist's nose and is angled downward toward the lips at a 45-degree angle (or rotated horizontally to the left or right). The vocalist projects straight ahead toward a pop filter, allowing the high-frequency sibilant beam to glance off the side of the microphone capsule rather than impacting the diaphragm directly at 0-degrees Certain Sparks Music. This physical rejection captures the rich chest resonance and fundamental tone of the voice while effectively blinding the microphone to the directional high-frequency sibilance. However, engineers must be aware that depending on the microphone's polar pattern, extreme off-axis singing can introduce unwanted phase or directional frequency coloration Certain Sparks Music.
Acoustic Deflection (The Pencil Trick): A highly effective, albeit visually unconventional, mechanical intervention is known as the "pencil trick". By affixing a standard cylindrical wooden pencil vertically directly across the center of the microphone grille using tape or rubber bands, the incoming high-velocity breath stream is aerodynamically split and physically bifurcated. This literally splits the air from the mouth into two different directions, deflecting the direct blast away from the highly sensitive dead-center of the diaphragm Certain Sparks Music. This directly mitigates high-end harshness and plosive impact by altering the fluid dynamics of the vocal projection before it hits the transducer Certain Sparks Music. While effective, it must be used cautiously to avoid accidentally over-dulling the entire vocal take URM Academy.
Pop Filters vs. Windscreens: It should be explicitly noted that standard nylon or metal mesh pop filters, while excellent for dispersing low-frequency 'P' and 'B' plosives, do virtually nothing to impede high-frequency sibilance Sage Audio. Foam ball windscreens that cover the entire microphone head are effective for live stage settings to reduce wind noise, but in a studio environment, they are generally avoided as they overly muffle the high-end response; standard pop filters combined with distance are vastly preferred Certain Sparks Music.
Transducer Physics: Electroacoustic Microphone Selection
If articulatory therapy and geometric placement techniques prove insufficient, the fundamental electromechanical properties of the microphone itself must be addressed. Different transducer topologies—condenser, dynamic, and ribbon—react to high-frequency transients and high-pressure aerodynamic bursts in fundamentally different ways due to their varying diaphragm mass, internal electronic impedances, and mechanical damping coefficients. The belief that one can simply "buy" their way out of a sibilance problem with ultra-expensive condenser microphones is a common fallacy; often, a massive downgrade in price to a heavier technology yields superior results Reddit.
Condenser Microphones: Transient Exaggeration and Electronic Distortion
Condenser microphones operate using electrostatic principles, utilizing an incredibly thin, electrically charged Mylar or gold-sputtered diaphragm positioned mere microns away from a solid, charged metal backplate, forming a capacitor YouTube. Because this diaphragm is exceptionally lightweight, it possesses an ultra-fast transient response, allowing it to capture high-frequency microscopic detail, room ambiance, and vocal "air" with stunning, analytical clarity YouTube.
However, this exact physical property makes condenser microphones notoriously unforgiving and actively hostile toward sibilant vocalists The Self-Recording Band. Budget and mid-tier condensers—and even highly expensive modern flagship implementations—frequently feature a hyped, artificially boosted high-frequency response intentionally designed to sound "detailed." For example, microphones like the Audio-Technica AT2035 or even flagship 50XX series models are frequently described by engineers as inherently bright, shrill, and entirely unpleasant on sibilant human voices Reddit. Even highly regarded tube condensers, such as Neumann U87 clones or modern variations, can sound brittle on an aggressive singer YouTube.
When a high-velocity sibilant breath strikes a bright condenser, the ultra-fast transient response perfectly traces and exaggerates the aggressive leading edge of the 's' waveform, while the inherent high-frequency presence boost amplifies the chaotic body of the fricative Reddit. Furthermore, cheap microphones and their paired preamplifiers often suffer from relatively low high-frequency electrical headroom. When hit by a massive transient blast of high-amplitude sibilance, the internal electronics or the preamp (such as an improperly gain-staged Neve 1073) may run out of voltage and induce harsh micro-distortion, adding ugly harmonic overtones that compound the psychoacoustic pain exponentially. If an engineer is committed to a condenser, utilizing a highly neutral, un-hyped microphone like the Neumann TLM-170, or utilizing hardware "capsule tuning" (physically modifying the capsule tension and backplate to remove specific resonant peaks) are the only physical hardware workarounds Reddit.
Dynamic Microphones: Inertia and Mechanical Damping
Dynamic microphones rely on classic electromagnetic induction, utilizing a Mylar or plastic diaphragm permanently attached to a tightly wound copper voice coil suspended entirely within a strong magnetic field YouTube. This entire moving-coil assembly possesses significantly more physical mass and inertia than a condenser's microscopic Mylar film YouTube.
The increased physical inertia radically slows the microphone's transient response, effectively acting as a natural, mechanical low-pass filter that struggles to reproduce ultra-fast, high-frequency transients The Self-Recording Band. Because they are less sensitive and do not aggressively trace the high-frequency waveforms, they naturally smooth out sibilance without the need for electronic equalization.
For highly sibilant singers, aggressive rock vocalists, or spoken-word broadcast voice actors, dynamic microphones are almost universally the preferred choice The Self-Recording Band. They exhibit a "gritty" midrange density, massive room noise rejection, and a smooth, rolled-off top end that naturally tames piercing sibilance Reddit. Industry-standard dynamic broadcast microphones—such as the Shure SM7B, Sennheiser MD421, Electro-Voice RE20, Shure SM57, and sE Electronics V7—are heavily utilized precisely because they actively reject high-frequency harshness. The RE20, for example, is noted for being incredibly dense and smooth on problematic vocals, vastly outperforming condenser microphones that cost twenty times as much Reddit. It must be noted, however, that because dynamic microphones possess much lower sensitivity, singers must typically stand much closer to the grille (closer than 8 inches), making off-axis positioning and the pencil trick absolutely mandatory to avoid massive proximity effect plosives URM Academy.

Ribbon Microphones: Extreme High-Frequency Roll-Off
Ribbon microphones represent the ultimate, final physical hardware solution for excessively harsh, bright, or unmanageably sibilant voices Sonicbids Blog. A ribbon transducer utilizes an ultra-thin piece of corrugated aluminum suspended under light tension between two powerful magnets. Like a dynamic mic, it uses electromagnetic induction, but the aluminum ribbon itself acts as both the acoustic diaphragm and the electrical voice coil simultaneously YouTube.
The acoustic signature of a ribbon microphone is characteristically mellow, intensely warm, and distinctly "dark," featuring a smooth, totally natural high-frequency roll-off that begins much earlier in the frequency spectrum than either condensers or dynamics Sonicbids Blog. Because the ribbon element is incredibly thin, it retains excellent transient accuracy without ever exhibiting the harsh, resonant presence peaks found in condenser capsules Sonicbids Blog. Ribbons also traditionally exhibit a true bipolar figure-8 polar pattern, which offers massive side-rejection of room reflections, capturing a deeply intimate sound YouTube.
For vocalists with naturally bright, sibilance-heavy ranges (such as bright sopranos), or for intimate acoustic tracking, a ribbon microphone acts as the ultimate natural acoustic de-esser. It captures the heavy, full body of the chest voice while elegantly masking and physically rejecting the piercing high-end 5 kHz+ frequencies Reddit. Legendary ribbon microphones—such as the Coles 4038, Beyerdynamic M160, modern AEA R44, or the vintage RCA 44BX—are heavily sought after for this exact purpose YouTube. For example, the incredibly smooth, intimate vocals on The Beatles' "Blackbird" were captured utilizing either a Neumann U48 (a figure-8 variant of the U47) or a dark ribbon microphone, providing a blueprint for achieving presence without sibilance Reddit.
Below is a structured comparison of transducer types and their inherent interaction with high-frequency sibilant energy:
Dynamic Signal Processing: The Algorithmic Evolution of De-Essing
Even with flawless microphone technique, off-axis placement, and ribbon transducer selection, modern mixing aesthetics—which heavily favor aggressively bright, upfront, and heavily compressed lead vocals—inevitably drag underlying sibilance to the forefront. When a vocal track is subjected to broadband dynamic compression (such as a classic Teletronix LA-2A or Tube-Tech CL-1B), the relatively low-amplitude fundamental frequencies of the vocal cords are violently brought up in volume, while the already loud, high-energy sibilant bursts hit the compressor threshold and are compressed, resulting in an unnatural flattening of the dynamic range that pushes the 's' directly into the listener's ear. This reality requires dedicated dynamic signal processing to control.
Traditional De-Essers: Wide-Band vs. Split-Band Architecture
A dedicated de-esser is essentially an audio compressor equipped with a highly specialized, isolated side-chain equalization circuit Sage Audio. The internal side-chain is programmed to listen exclusively to a narrow, high-frequency band where sibilance resides (typically between 4 kHz and 10 kHz). When the acoustic energy within this specific, narrow band crosses a predetermined amplitude threshold, the processor triggers the gain reduction circuit URM Academy. Traditional de-essers operate via two distinct, primary modes of attenuation:
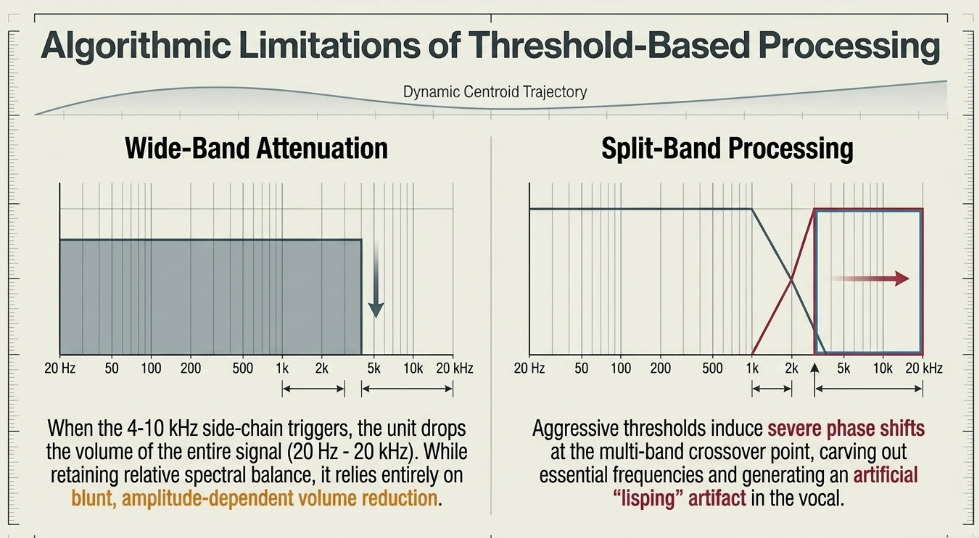
Wide-Band (Full-Range) Processing: When the high-frequency side-chain successfully detects a sibilant event crossing the threshold, the processor aggressively turns down the volume of the entire broadband audio signal, from 20 Hz to 20 kHz. Despite initially seeming counterintuitive, wide-band de-essing is often perceived by mastering engineers as the most transparent, natural-sounding method. Because it preserves the exact, relative spectral balance of the vocal while simply reducing its overall amplitude for the microscopic duration of the sibilance, it acts exactly like an impossibly fast studio fader automation. This architecture is heavily inspired by classic hardware processors such as the legendary DBX 902 Reddit.
Split-Band (Band-Specific / HF-Only) Processing: In this mode, the processor functions identically to a basic multi-band compressor. When triggered by the side-chain, the unit exclusively attenuates the high-frequency band, actively leaving the low and midrange fundamental frequencies entirely untouched. While highly effective at carving out a chunk of the harshness and preventing compressors further down the signal chain from reacting violently to the 's', split-band processing is fraught with technical peril. If the threshold is set too aggressively, it induces severe phase shifts at the crossover frequency, carving a massive, unnatural hole in the spectrum that instantly makes the vocalist sound as though they are speaking with a severe lisp URM Academy.
Standard operational parameters for deploying a traditional algorithmic de-esser (such as the Waves R De-Esser, Fabfilter Pro-DS, or Plugin Alliance SPL) involve setting the side-chain filter to aggressively target the exact offending frequency (e.g., 7 kHz), setting the range control to limit maximum gain reduction to roughly 5 to 10 dB to prevent lisping, and carefully adjusting the threshold until only the sibilant consonants trigger the attenuation URM Academy.
The Dynamic Equalization Advantage
While traditional side-chain de-essers are historically standard, they are severely limited by their archaic inability to target more than a single frequency band simultaneously. Because the centroid frequency of sibilance physically moves and sweeps dynamically PMC, and because complex harshness often manifests across multiple distinct frequency nodes concurrently, modern mix engineers are increasingly abandoning traditional de-essers in favor of Dynamic Equalization Bobby Owsinski Blog.
A dynamic EQ perfectly marries the surgical precision of parametric equalization with the threshold-dependent, time-based behavior of a compressor Puremix. Instead of relying on a single side-chain triggering a wideband duck, a dynamic EQ allows the engineer to create multiple, surgically narrow EQ nodes—each completely independent, possessing its own specific Q-width, center frequency, volume threshold, attack, and release parameters Bobby Owsinski Blog.
When treating highly complex, multi-layered sibilance, an engineer can deploy three distinct dynamic EQ bands to monitor and suppress specific problem areas simultaneously:
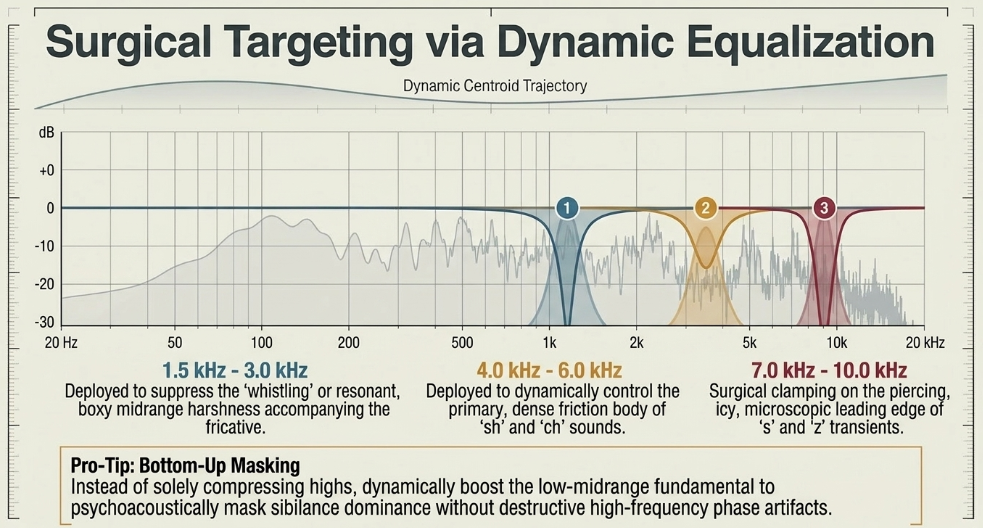
Lower Band (1.5 kHz to 3 kHz): Deployed to catch the "whistling" or resonant, boxy midrange harshness that often accompanies the fricative Bobby Owsinski Blog.
Mid-High Band (4 kHz to 6 kHz): Deployed to control the primary, dense body of the 'sh' and 'ch' friction noise Bobby Owsinski Blog.
Ultra-High Band (7 kHz to 10 kHz): Deployed to surgically clamp down on the piercing, icy, microscopic leading edge of the 's' and 'z' transients Bobby Owsinski Blog.
Dynamic EQs featuring real-time visual FFT spectrum analyzers (such as the Waves F6, FabFilter Pro-Q3, or iZotope Neutron) allow the engineer to visually identify the exact frequency spikes associated with specific consonants as they happen, dialing in the precise bandwidth (Q) required to diminish the sibilance without heavily taxing the CPU by cascading three separate de-esser plugins. Pro-tip implementation dictates setting the attack and release controls to their absolute fastest values to instantly clamp down on the rapid high-frequency transient, then slowly backing off the release until the vocal breathes naturally without pumping Bobby Owsinski Blog.
Furthermore, dynamic EQs can be utilized in an inverse methodology known as bottom-up EQing Puremix. Rather than dynamically suppressing the aggressive highs, an engineer can utilize an EQ to dynamically boost the lower midrange and fundamental frequencies of the vocal. This effectively masks the psychoacoustic dominance of the sibilance by thickening the body of the voice, avoiding the destructive phase artifacts of high-frequency compression entirely Puremix.
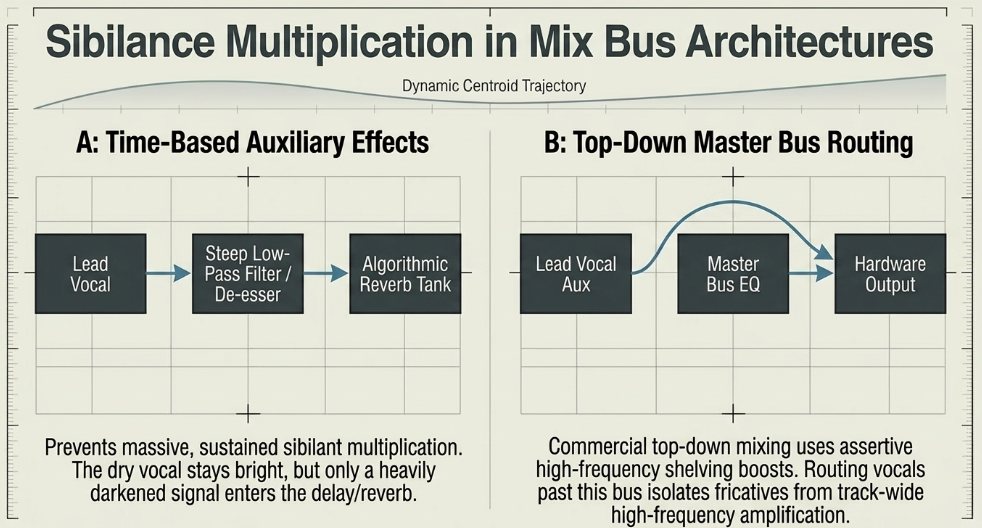
Strategic Routing and Mix Bus Architecture
Applying de-essers directly as inserts on the main vocal channel is only one dimension of the mixing equation. In complex, modern pop mix architectures involving dozens of backing vocals, double-tracking, and massive parallel processing, sibilance multiplies exponentially. If the 'esses' in layered backing parts are not perfectly, manually aligned, the transients smear across the stereo panorama, creating a sloppy, diffused, and unlistenable high-end.
Time-Based Auxiliary Effects: Routing a heavily sibilant vocal into dense algorithmic reverbs and long tape delays creates a catastrophic multiplication of high-frequency noise. The time-based effects catch the incredibly loud 's' transients, multiply them, and smear them over several seconds, drawing massive, sustained unwanted attention to the harshness. To combat this, master engineers utilize localized auxiliary de-essing by placing a dedicated de-esser or a steep low-pass filter directly on the auxiliary effects return channel, before the reverb or delay plugin. This vital routing ensures the "dry" lead vocal retains its natural brightness, but only a smoothed, heavily darkened signal is allowed to enter the reverb tank, preventing the 's' from ricocheting around the artificial room.
Master Bus Top-Down Routing: Engineers frequently apply top-down mixing techniques, involving broad, highly assertive high-frequency shelving boosts on the master stereo bus to add commercial "air" and radio-ready presence to the entire track. However, this uniformly amplifies the vocal sibilance alongside the cymbals and synths. A sophisticated workaround involves routing the lead vocal auxiliary bus directly to the hardware output, actively bypassing the master bus EQ entirely. This achieves a brilliantly bright instrumental mix while strictly isolating the vocal fricatives from further high-frequency amplification Sound On Sound.
Precision Control: Non-Linear Micro-Editing and Spectral Repair
Despite the immense power of dynamic EQs and multiband algorithms, any threshold-dependent digital processing is inherently, physically flawed. A de-esser relies absolutely on an attack time; it must first hear the sibilance cross the threshold, calculate the voltage change, and then engage the gain reduction circuit. This inescapable physiological and digital delay means the initial, microscopic transient—the first few violent milliseconds of the 's' sound—escapes entirely uncompressed, and is frequently psychoacoustically exaggerated when the body of the sound behind it is suddenly ducked Reddit. Look-ahead functions attempt to solve this by delaying the entire audio track to give the plugin time to react, but they frequently grab non-sibilant material, dulling the performance Reddit.
For absolute, artifact-free control, the highest tier of professional audio engineering utterly abandons real-time plugins in favor of manual, destructive micro-editing. This involves the engineer visually identifying every single sibilant waveform across a multi-minute track in the digital audio workstation (DAW) and manually altering its absolute amplitude, a process that can take hours of meticulous labor Orçun Ayata.
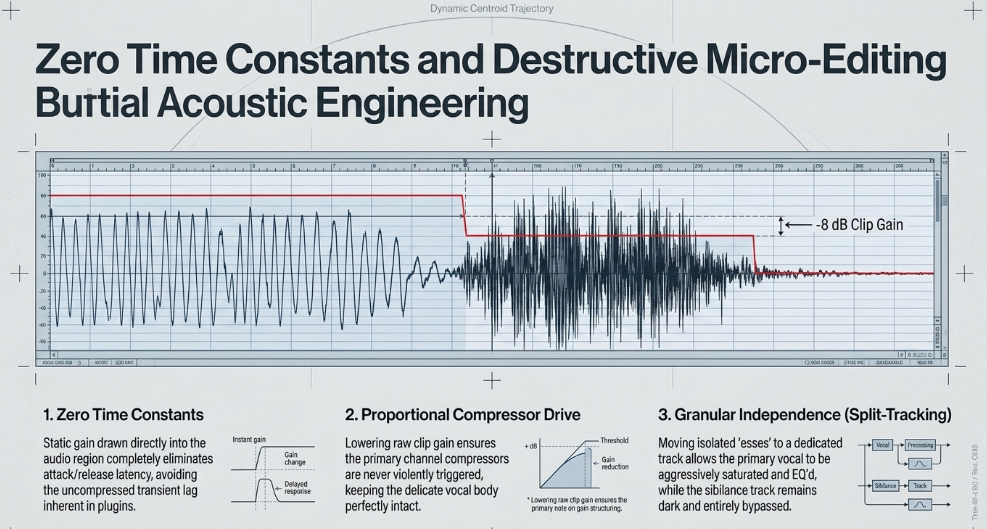
Clip Gain Automation and Zero Time-Constant Processing
Manual sibilant editing completely bypasses the inherent flaws of compressors. In highly zoomed visual waveform editors, sibilants appear as incredibly dense, high-frequency, chaotic, non-periodic "blobs" that look drastically, fundamentally different from the smooth, periodic sine-wave cycles of vowel fundamentals. By utilizing the DAW's slicing tools or pre-fader clip gain envelopes, the engineer manually lowers the pure volume of the specific sibilant artifact by 5 to 10 dB URM Academy.
This laborious method is objectively superior to algorithmic de-essing for several highly technical reasons:
Zero Time Constants: Because the exact gain reduction is totally static and drawn directly into the audio region file itself, there is absolutely no attack or release time Reddit. The transient is attenuated perfectly, immediately, and in phase, avoiding the unnatural pumping or lisping artifacts introduced by compressor lag Reddit.
Proportional Compressor Drive: Lowering the raw clip gain means significantly less electrical amplitude is fed into the subsequent processing chain. When the vocal hits the primary channel compressors, the sibilance is already too quiet to violently trigger aggressive threshold reduction YouTube. This allows the compressors to operate smoothly on the body of the vocal, preventing the quiet details of the vocal from "getting lost" behind a wall of squashed, compressed harshness YouTube.
Individual Phonetic Customization: Not all 's' sounds are created equal in intensity, duration, or frequency spread Reddit. Manual editing allows the engineer to make clinical decisions: applying a subtle 3 dB cut to a soft 'sh', and a massive 12 dB cut to a piercing 'z', a level of artistic discernment an automated static plugin threshold simply cannot achieve Reddit.
Modern DAWs provide extensive keystroke shortcuts to accelerate this grueling process. In Pro Tools, engineers can highlight the specific sibilant waveform and utilize keyboard shortcuts (e.g., separating the clip with the 'B' key, then holding Shift + Windows Key + Scroll Wheel) to instantly nudge the clip gain line up or down in precise microscopic decibel increments, seamlessly integrating the fix into the mixing prep workflow without ever touching a mouse YouTube.
Split-Track Routing and ARA Integration
An alternative manual technique involves an aggressive editing approach known as split-track de-essing. During the track preparation phase, the engineer meticulously physically cuts every individual sibilant, breath, and click out of the primary vocal track and moves them vertically to an entirely separate, dedicated audio channel. This split routing allows for radical, total independence in signal processing. The primary vocal channel can be heavily compressed, aggressively saturated with harmonic distortion, and EQ'd with massive 10 dB high-frequency boosts to achieve a hyper-modern, airy pop aesthetic. Meanwhile, the dedicated "sibilance track" completely bypasses these aggressive processors Sound On Sound. The isolated sibilance track can be aggressively low-pass filtered, volume automated via fader rides, and routed independently, ensuring the 'esses' remain incredibly soft, dark, and perfectly controlled while the fundamental vocal shines brilliantly.
For unparalleled granular repair, modern engineers utilize Audio Random Access (ARA) plugins and offline spectral processors. Tools like Celemony Melodyne 5 and Synchro Arts Revoice Pro possess algorithms capable of automatically identifying purely unpitched noise (sibilance) distinct from pitched fundamentals, allowing the engineer to visually drag the amplitude of the noise down independently within the pitch-correction window. Furthermore, standalone offline spectral editors, such as the industry-standard iZotope RX, offer highly advanced spectral repair modules. Unlike real-time plugins, offline spectral editors display audio as a heat map. This allows the engineer to highlight highly specific time-and-frequency coordinates (e.g., isolating a whistle specifically at exactly 6.8 kHz for 12 milliseconds) and attenuate only that exact microscopic resonant node, completely eliminating the piercing artifact without touching the surrounding fundamental audio frequencies Reddit.
Next-Generation Solutions: Artificial Intelligence and Spectral Phoneme Detection
The technological frontier of sibilance control is currently undergoing a massive, unprecedented paradigm shift, moving rapidly away from blunt, amplitude-dependent compressors toward highly sophisticated Artificial Intelligence (AI) and Machine Learning (ML) algorithms that evaluate audio based on complex phonetic context rather than mere volume thresholds sonible.
Phoneme Recognition vs. Threshold Ducking
As established, traditional de-essers are fundamentally "dumb" processors; they completely lack contextual awareness and cannot distinguish between a high-frequency synthesizer bleeding into a vocal mic, the crash of a drum cymbal, a squeaking chair, or a human actually saying the letter 's'. If the specific frequency crosses the voltage threshold, it is mercilessly compressed, often resulting in massive collateral damage to the mix sonible.
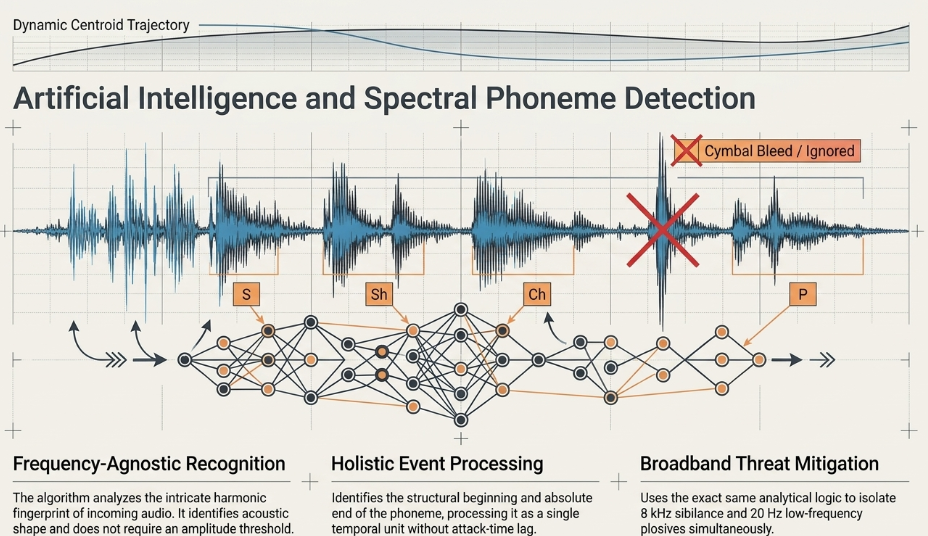
Next-generation AI-driven plugins (such as sonible's smart:deess or iZotope's advanced Velvet modules) utilize incredibly complex neural networks trained on vast, global datasets of human speech to perform real-time phoneme detection. These algorithms do not listen for volume; they analyze the intricate harmonic fingerprint of the incoming audio to identify specific linguistic phonetic structures. Because the AI is identifying the acoustic "shape" of the sound rather than its raw amplitude, it fundamentally does not require a threshold parameter. It can accurately, independently detect and isolate 'S', 'Z', 'Sh', 'Ch', 'K', 'T', and 'P' sounds regardless of how loudly or quietly they are spoken, and regardless of where they physically sit in the frequency spectrum sonible.
Because true phoneme detection is frequency-agnostic, these advanced tools can perform tasks impossible for traditional de-essers. They can simultaneously identify and remove low-frequency plosives (which occur violently between 20 Hz and 500 Hz) using the exact same analytical neural process utilized to remove 8 kHz high-frequency sibilance sonible. Furthermore, because the AI accurately detects the structural, temporal beginning and the absolute end of the phoneme, it processes the entire sibilant event holistically as a single unit, utterly avoiding the delayed attack-time artifacts inherent in threshold-based triggers sonible.
Micro-Band Spectral Processing Capabilities
Once the AI neural network successfully identifies the sibilant phoneme, it does not apply wide-band or broad split-band ducking. Instead, it applies highly advanced spectral processing. Spectral processing divides the audio signal into thousands of microscopic, individual frequency bands, analyzing the energy in each highly specific bin via complex Fast Fourier Transforms (FFT) sonible.
Unlike a traditional, analog-style de-esser that clumsily ducks an entire 4 kHz to 10 kHz range (inadvertently dragging down the crucial "air" and breath of the vowel), a spectral processor dynamically maps the exact, specific resonant spikes of the unique sibilance event and applies negative gain exclusively to those microscopic nodes, leaving the spaces between the spikes entirely untouched. Furthermore, each phonetic event is processed uniquely: an 'sh' phoneme will instantly trigger a completely different spectral attenuation map than a hard 's' sonible. This results in unprecedented, practically invisible transparency, completely removing the harshness without inducing lisping, phasing, or tonal darkening.
Critical Application to Synthetic and AI-Generated Voices
The rapid emergence of spectral AI tools is particularly critical for processing modern synthetic, AI-generated voices. AI voice models—frequently used in modern voiceovers, audiobooks, and multimedia—frequently generate audio that completely breaks the fundamental, physical assumptions of natural human speech dynamics Sonarworks Blog.
AI voices produce highly inconsistent sibilant detection patterns and generate highly problematic, piercing harshness across significantly wider and less predictable frequency spectrums than actual human vocal cords Sonarworks Blog. Traditional, threshold-based de-essers fail entirely when applied to AI voices because they are meticulously calibrated for the natural dynamic buildup and aerodynamic release of human breath Sonarworks Blog. AI-generated vocals maintain an unnaturally consistent, robotic amplitude that utterly confuses threshold-based compression algorithms, resulting in either zero gain reduction triggering, or complete signal destruction Sonarworks Blog. Advanced AI-driven spectral phoneme detectors bypass this critical limitation entirely by relying on complex pattern recognition rather than dynamic amplitude thresholds, ensuring synthetic sibilance is mitigated just as cleanly, effectively, and transparently as organic, human speech Sonarworks Blog.
Below is a structured comparison of algorithmic processing methodologies and their technical efficacy:











