
The Structural Hierarchy and Technical Imperatives of Spoken-Word Post-Production
In the modern commercial landscape, podcasting has undergone a rapid transition from a rustic, democratized medium of casual voice recordings into a highly sophisticated, multi-layered auditory discipline1. As audience expectations mature and global distribution platforms proliferate, the technical standards for podcast audio quality have risen to rival those of professional music production and traditional broadcast television2. Audio engineering in the post-production stage is not merely a corrective or mechanical process2. It is an active creative and psychological discipline that directly shapes narrative impact, ensures listener retention, lowers cognitive load, and establishes a brand’s sonic identity2.
The post-production editing and mixing pipeline serves as the critical bridge between raw audio capture and the final consumer experience2. The boundaries of what can be accomplished during post-production are inexorably defined by the quality of the initial raw recordings2. This fundamental limitation is summarized by the immutable adage: "garbage in, garbage out"2. Post-production signal processing cannot fabricate pristine high-frequency fidelity or low-frequency authority that was never originally captured2. The quality of the microphones, preamplifiers, and the physical acoustic environment dictates the absolute boundaries of the mix2. However, when high-quality source material is provided, the mix is responsible for establishing spatial balance, ensuring absolute vocal intelligibility, and guaranteeing that the audio translates consistently across a vast array of consumer playback systems, ranging from premium studio monitors to low-grade smartphone speakers2.
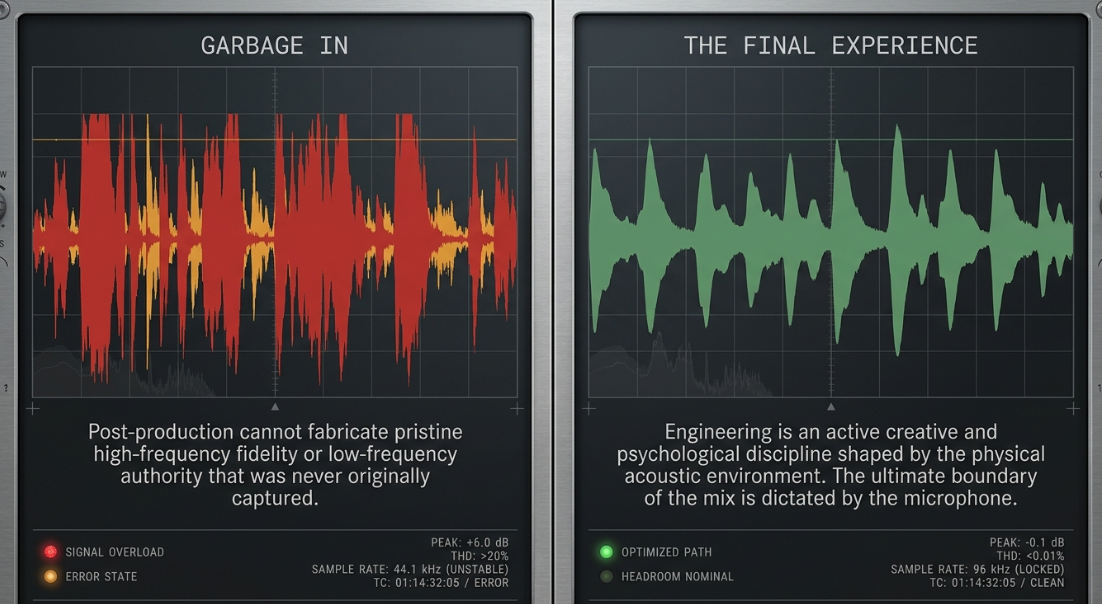
The ultimate benchmark of this process is the "perfect mix"2. In professional audio engineering circles, the perfect mix is recognized as an largely unattainable theoretical ideal rather than a concrete destination2. It represents a state where technical precision—characterized by the absolute absence of frequency masking, optimal phase coherence, and pristine noise reduction—coexists with profound emotional resonance2. Because audio evaluation is highly subjective and vulnerable to sensory drift, engineers strive instead for a "stable" and "appealing" mix2. This realistic target successfully directs the listener's attention precisely where the narrative demands it, minimizing cognitive fatigue and ensuring a seamless, immersive experience2.
To construct a stable mix, engineers must adhere to rigorous digital audio baseline standards before applying creative processing6. The parameters of digital tracking, bit resolution, and file formats dictate the theoretical limits of dynamic range and spectral integrity6.
When an engineer relies on compressed formats such as MP3 during the active mixing stage, the file is subjected to destructive, lossy compression6. The MP3 algorithm utilizes psychoacoustic modeling to identify and permanently discard data that the human auditory system is biologically incapable of perceiving, such as simultaneous masking where a quiet sound is drowned out by a louder sound occurring at the same frequency6. If a producer records an MP3, imports it into a digital audio workstation (DAW) for processing, and then exports it again as a new MP3, the file undergoes cascading generations of psychoacoustic deletion, resulting in distinct digital artifacts, phase shift, and a significant loss of clarity6. Thus, all tracking, editing, and dynamic processing must occur within a lossless WAV ecosystem, leaving lossy compression strictly as a final delivery codec6.

Psychoacoustic Axioms and the Structural Mechanics of Sound
The Louder is Better Phenomenon and Quiet Monitoring
A foundational axiom of audio engineering is that the human auditory system inherently perceives louder audio as subjectively superior2. This psychological bias is governed by the physics of the Fletcher-Munson equal-loudness curves, which demonstrate that human hearing sensitivity is highly non-linear across the frequency spectrum2. The human ear is biologically optimized for mid-range frequencies associated with speech intelligibility5. However, as the overall sound pressure level increases, the ear's frequency response flattens5. Mathematically, an increase in amplitude results in a heightened perception of low-frequency warmth and high-frequency crispness2.
Consequently, untrained listeners will almost universally select a louder mix as the "better" mix, even if its dynamic integrity has been severely compromised by over-compression2. To circumvent this psychoacoustic bias, professional mixing engineers enforce strict level-matching protocols during A/B testing2. Level-matching ensures that processing decisions genuinely improve the tonal character of the audio rather than merely increasing the amplitude2.
Furthermore, pedagogical frameworks, such as those established by Roey Izhaki, advise engineers to conduct the majority of their mixing at low, quiet monitoring levels5. Because the ear is most sensitive to mid-range frequencies at lower amplitudes, a mix whose mid-range is perfectly balanced at quiet levels will translate cleanly and retain its balance across all playback devices and monitoring volumes5.

The Dynamic Behavior of Sound Weight
In the spatial architecture of a mix, sonic "weight" is determined not by the peak transient energy of a sound wave, but by its duration and sustain2. This physical behavior is summarized by the axiom "percussives weigh less"2. Percussive sounds, such as sharp vocal plosives (consonants like "P" or "B") or immediate acoustic impacts, exhibit immense peak amplitude but decay within milliseconds2. This leaves the surrounding temporal space empty and results in very little perceived weight2.
Conversely, sustained sounds—such as continuous background room tone, musical synth pads, or elongated vocal vowels—carry continuous energy over time2. These sustained elements occupy massive spectral real estate and heavily dictate the perceived density and loudness of the mix2. In podcast post-production, applying aggressive compression to a voice reduces its transient peaks while elevating its tail, which mathematically increases its sustain2. This increases the overall sonic weight of the voice, causing it to consume more space in the mix and establishing a commanding broadcast presence2.
Dialogue Supremacy and the Musicality of Speech
The structural hierarchy of a spoken-word mix requires dialogue to maintain absolute supremacy across all domains2. Every mixing decision—from equalizing a music bed to adjusting the pre-delay of a reverberation tail—must support and highlight the central vocal narrative2. Spoken dialogue is not merely a vehicle for linguistic data; it possesses inherent rhythm, tempo, dynamic range, and tonal frequencies2. The cadence of human speech establishes a melodic flow that dictates the emotional narrative2. The orchestration of these dialogue stems, coupled with ambient soundscapes and musical transitions, forms a complex sonic landscape that subliminally guides the listener’s psychological state2.
Paradoxically, achieving a "natural" and intimate vocal sound in commercial podcasting relies heavily on artificial processing—such as spectral shaping, dynamic leveling, and noise reduction—to build an idealized version of reality2. The goal is to construct a hyper-realistic, dry, and direct sound profile that fosters a parasocial relationship between the host and the listener1.
The Pedagogy of Learning and the Analytical Framework of Mixing
The Master Class Persona and the Continuous Loop of Creative Mixing
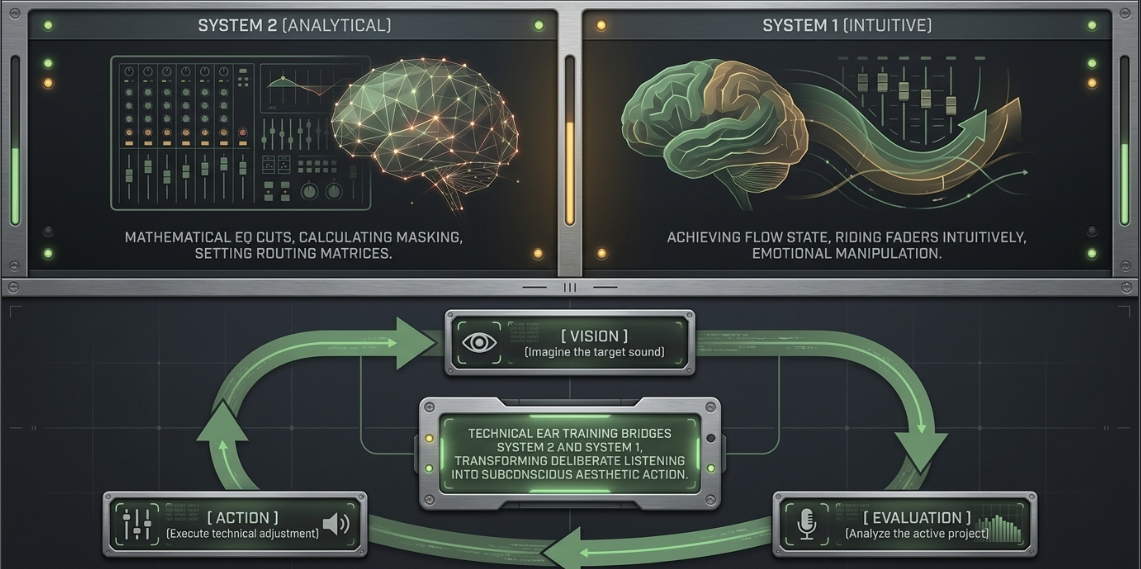
A professional mixing engineer represents a combination of technical mastery, acoustic physics knowledge, and refined interpersonal skills2. To excel in this field, an engineer must develop a clear "mixing vision," which involves imagining the target sound of the mix in one's mind before a single fader is adjusted5. This methodology is structured as a continuous loop of evaluation and action5.
[ VISION ]
│
▼
[ EVALUATION ] ◄───┐
│ │
▼ │
[ ACTION ] ──────┘
Within this loop, the engineer constantly asks critical questions about the current state of the mix5. The technical adjustments made during the Action phase are driven entirely by the comparative assessment of the active project against the imagined Vision5. This prevents the common amateur pitfall of turning knobs blindly in search of a pleasing accident5.
Technical Ear Training and Analytical Dissection
The acquisition of mixing skills requires a multi-faceted approach2. While reading theoretical texts provides the necessary vocabulary and understanding of signal flow, auditory training is the most critical component of professional development2. The methodology of "technical ear training" involves daily exercises, practicing the rapid identification of specific frequency bands, compression levels, and stereo width variations2. Tools like pink noise generators and specialized software aid in bridging the gap between theoretical knowledge and instant auditory recognition2.
Complementing this training is mixing analysis, which moves the listener from passive consumption to active, analytical dissection2. By actively analyzing top-tier podcasts, an engineer can reverse-engineer the decisions made regarding vocal equalization, ambient sound layering, and dynamic consistency2. This analytical mindset is reinforced by the use of reference tracks—professionally mastered commercial releases imported directly into the DAW alongside the active project2. By rapidly A/B testing between the active mix and the reference track, the engineer can recalibrate their ears to a known standard of excellence, circumventing the acoustic anomalies of their specific mixing room and preventing their subjective perception from drifting2.
In the commercial landscape, the ability to work fast is as critical as sonic fidelity2. Speed demonstrates a deep internalization of the toolset, allowing the engineer's subconscious intuition to guide macro-adjustments without being bogged down by analytical paralysis2. Speed also prevents ear fatigue, ensuring that the engineer's perspective remains fresh throughout the critical evaluation phases2.
Cognitive Processing: Mixing and the Brain
The cognitive mechanisms of audio mixing are explained by Dual Process Theory, which posits that human thought is governed by two distinct systems: System 1 (fast, intuitive, and unconscious processing) and System 2 (slow, deliberate, and analytical reasoning)2.
When an engineer relies on System 2, they engage in deliberate problem-solving, such as identifying a masking issue at and mathematically calculating a subtractive equalizer cut2. However, the most profound aesthetic decisions are driven by System 12. Technical ear training serves to bridge the gap between these two systems, converting slow, analytical listening into rapid, intuitive responses2. Achieving a "flow state" in mixing requires a seamless oscillation between these modes—utilizing System 2 to set up complex routing matrices, and System 1 to intuitively ride faders and balance the emotional impact of a dialogue exchange2.
The power of the unconscious allows seasoned professionals to make rapid, holistic judgments regarding spatial depth, emotional weight, and narrative pacing without active deliberation2. Highly developed technical ear training enables the engineer to intuitively make micro and macro level-adjustments, keeping their mental workspace clean and efficient2.
This intuitive speed is vital because audio mixing is ultimately an exercise in emotional manipulation2. The tone of a voice, shaped by harmonic saturation and equalization, inherently dictates how the listener perceives the speaker's authority, intimacy, and sincerity2. Furthermore, the human brain is wired to notice change; a stagnant mix will rapidly lose the listener's attention2. Therefore, the engineer must introduce subtle creative changes—altering the density of the reverb, shifting the panning of environmental sounds, or automating volume swells—to maintain continuous narrative interest2.

The Four Architectural Domains and Post-Production Objectives
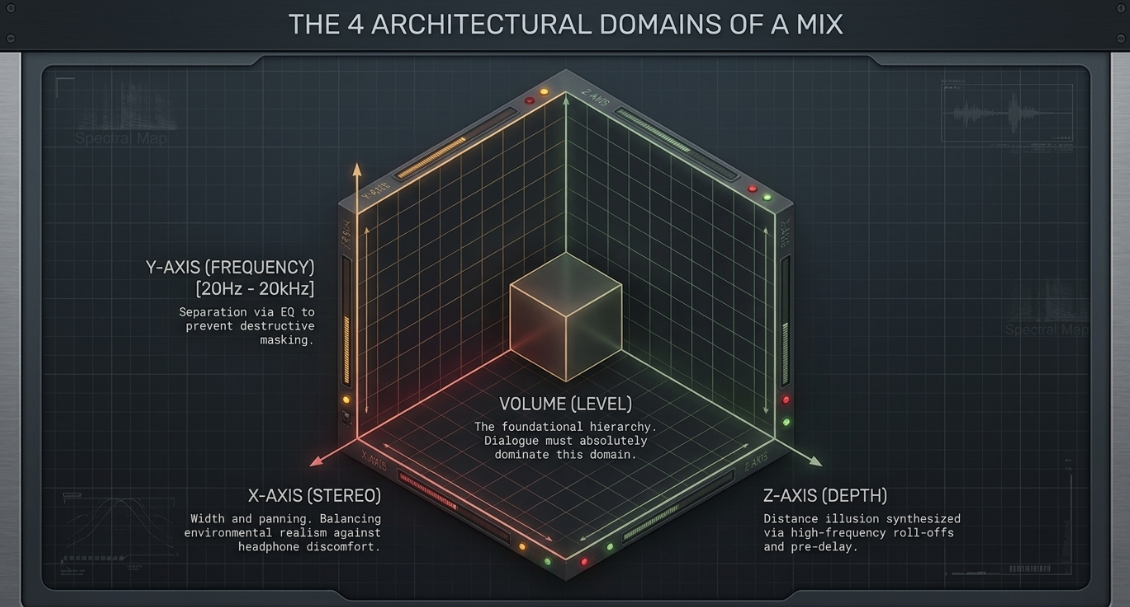
The primary objective of a podcast mix is absolute definition—ensuring that every syllable is intelligible and that individual sonic elements can be easily distinguished without cognitive strain2. A mix must also generate interest; while ambient or background music is designed to be ignorable, a podcast narrative demands active engagement, requiring dynamic movement and spatial contrast to prevent auditory monotony2. These objectives are achieved by balancing four distinct dimensions, or "domains," of audio2.
[ FREQUENCY ]
(Separation)
▲
│
[ STEREO ] ◄────────────┼────────────► [ DEPTH ]
(Panning/Width) │ (Reverb/Distance)
▼
[ LEVEL ]
(Hierarchy)
1. The Frequency Domain
Often considered the most difficult aspect to master, the frequency domain concerns the vertical axis of sound, spanning the limits of human hearing from to 2. The goal in this domain is separation—ensuring that no two elements occupy the exact same spectral space to the point of destructive masking2. For podcasts utilizing sequenced or synthesized music beds, the engineer must ensure that the instrumentation does not clash with the fundamental frequencies of the human voice, which often involves applying aggressive high-pass filters or utilizing dynamic equalization to carve out a spectral pocket for the dialogue2.
2. The Level Domain
The foundational axis of mixing, the level domain is controlled primarily via faders and dynamic processors2. Level dictates the absolute hierarchy of elements2. In podcasting, the vocal dialogue must maintain unyielding supremacy in the level domain2. The level domain is managed closely via faders, automated volume riders, and compressors to ensure that speech remains consistent and legible without demanding active volume adjustments from the listener7.
3. The Stereo Domain
The horizontal axis of the mix is manipulated via panning controls2. While traditional interview podcasts anchor voices strictly to the phantom center to ensure maximum coherence, narrative podcasts exploit the stereo domain to create immense width and environmental realism through sound design2. Panning controls must be used strategically to balance the stereo field, ensuring that the listener's head is not pulled awkwardly to one side, which causes rapid physiological discomfort when wearing headphones2.
4. The Depth Domain
The front-to-back axis of the mix represents an auditory illusion synthesized through a combination of level manipulation, frequency attenuation, and reverberation2. High frequencies are naturally absorbed by air over long distances due to friction losses; thus, applying a high-shelf EQ cut mimics physical distance2. Adjusting the pre-delay of a reverb tail further pushes elements backward or pulls them forward in the psychoacoustic space, allowing the engineer to construct a three-dimensional soundscape that supports the narrative2.
Monitoring and the Physical Listening Environment
Selecting and positioning studio monitors is an intensely personal and mathematically precise decision for an engineer, governed by budget and physical space constraints2. The history of studio monitoring represents a constant pursuit of "flat" or uncolored frequency response, progressing from rudimentary single-driver loudspeakers to highly complex, active crossover nearfield systems designed to provide the engineer with absolute clinical truth regarding their audio2. High-quality nearfield monitors are designed to be placed closely to the listener (typically within 1 to 2 meters) to maximize the ratio of direct sound to reflected room sound2.
Monitors are highly susceptible to the "room factor"2. Untreated acoustic spaces introduce comb filtering, early reflections, and standing waves (room modes) that severely color the frequency response2. For instance, if a room naturally amplifies due to its physical dimensions, the engineer will incorrectly cut in the mix, resulting in a thin, weak podcast when played on other systems2. Correct positioning involves creating an equilateral triangle between the two monitors and the listener's ears, with the tweeters aligned at ear level to ensure precise stereo imaging and frequency translation2.
Diagnostic Remediation and Advanced Signal Processing Chains
Forensic Equalization for Thin or Deficient Source Material
A common challenge in modern post-production is repairing voice tracks that suffer from poor environmental acoustics or improper microphone usage, which manifest as a hollow or "tinny" sound19. This issue is rarely the result of a single hardware failure; rather, it is the cumulative symptom of suboptimal practices distributed across the entire acoustic and digital signal chain19.
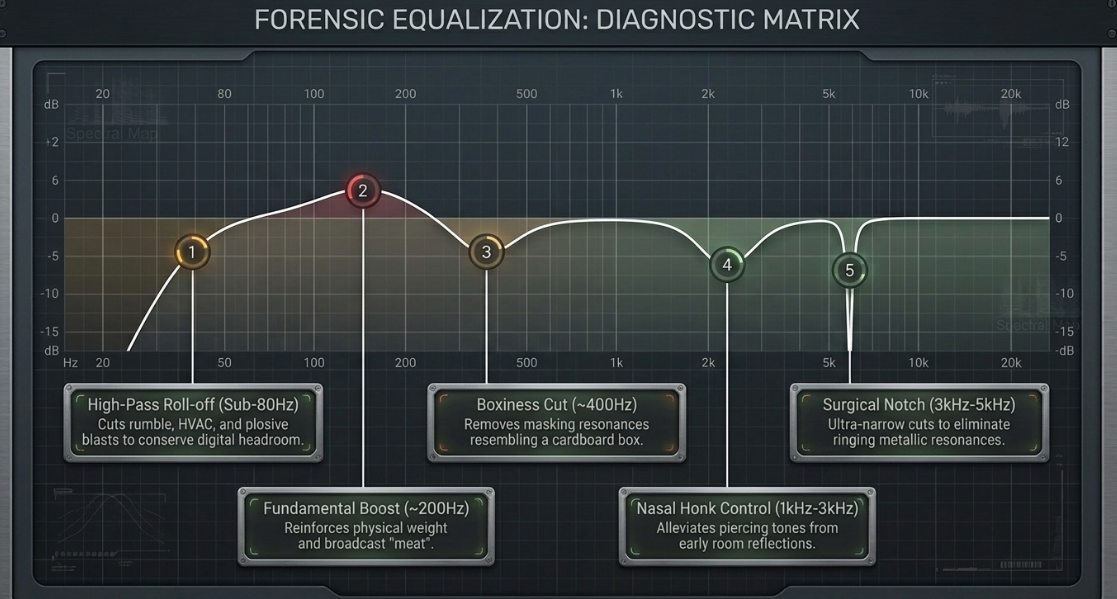
When a host records too far from a directional microphone, the signal loses the low-end warmth provided by the physical proximity effect19. Simultaneously, the room's reflective boundaries—such as drywall or windows—bounce high-mid and high frequencies back into the microphone capsule, causing comb filtering and a piercing echo19. To remediate these deficiencies, engineers deploy a precise, sequential parametric equalization protocol19.
Phase Cancellation Diagnostics and Multi-Mic Bleed Control
Phase cancellation occurs when multiple microphones capture the same sound source, or when a primary vocal track is contaminated by late-arriving acoustic reflections19. Because sound travels through air at a finite speed, the time delay between the direct arrival and the reflected or bleed arrival causes the waveforms to fall out of step19. Certain frequencies are mathematically reinforced through constructive interference, while others are entirely nullified through destructive interference19. This creates severe comb filtering, leaving the vocal sounding thin, hollow, and washed out19.
Engineers utilize three standard technical workflows to diagnose and correct phase cancellation:
Mono Summing Verification: The stereo mix is temporarily summed to a monaural configuration19. If the vocal suddenly drops in amplitude, loses its low-frequency fundamental body, or sounds hollow, active phase cancellation is confirmed19.
Phase Polarity () Testing: The engineer applies a phase-invert tool to one of the conflicting tracks19. If flipping the polarity mathematically reverses the peaks and troughs of the waveform and immediately restores the thickness and low-end of the vocal, destructive interference was actively occurring19.
Visual Correlation Metering: Digital tools, such as the Voxengo Correlometer or ADPTR Metric AB, analyze the phase relationship across the frequency spectrum19. A correlation reading of indicates perfect in-phase coherence, indicates a wide, uncorrelated stereo field, and values moving toward indicate out-of-phase signals that will cancel out upon mono playback19.
In a multi-host studio setup, "bleed" or "cross-talk" occurs when one speaker's voice is captured by an adjacent host's microphone6. This introduces comb filtering and distracting ambient noises into the primary vocal track6. The physical mitigation of bleed begins at the tracking stage, using dynamic microphones with tight cardioid or supercardioid polar patterns6.
When physical isolation is insufficient, digital restoration is required7. Traditional noise gates can cut out background noise when a host is silent, but they often sound abrupt and cut off initial syllables7. Modern workflows favor advanced spectral de-bleeding tools26. Machine-learning-based software, such as iZotope RX, can analyze the spectral signature of bleed and remove it from the target track in real time, bypassing the need for a separate reference track26.
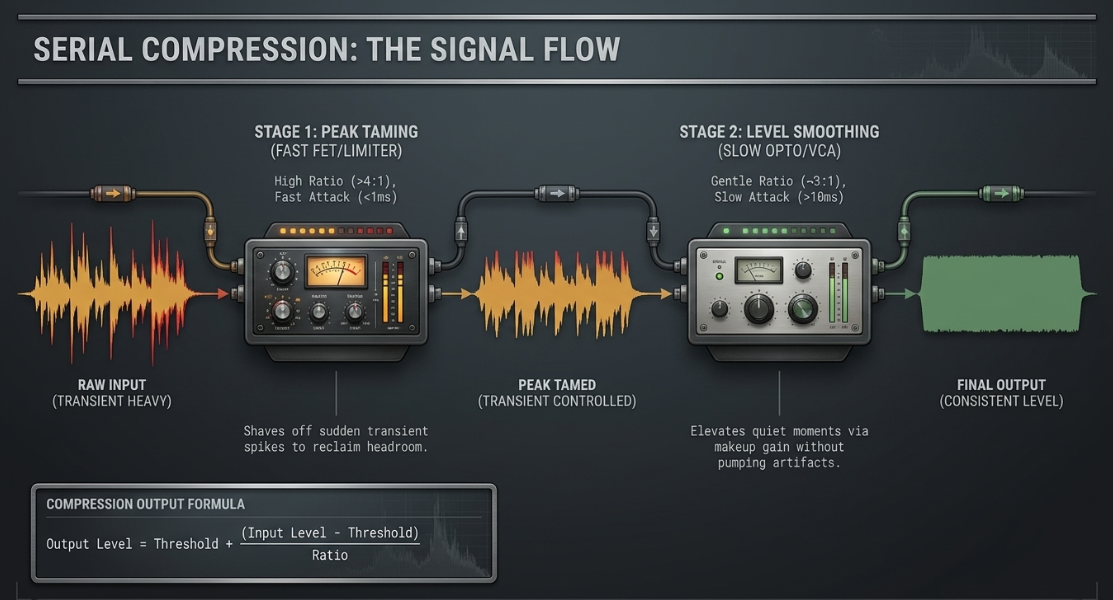
Dynamics Control: Core Parameters and Serial Processing
Managing the dynamic range of speech is a critical step in podcast post-production, ensuring that the dialogue remains perfectly audible and consistent over time7. This is accomplished primarily through compression, which automatically attenuates the loudest passages of an audio signal when they exceed a defined threshold, allowing the entire signal to be elevated using makeup gain2.
The fundamental parameters of a compressor are mathematically defined and operate in unison to shape the dynamic envelope of the voice2:
Threshold: The specific decibel level at which the compressor engages (). Signals falling below this threshold pass entirely unaffected2.
Ratio: The severity of the gain reduction applied to signals that cross the threshold. A ratio of dictates that for every the input signal exceeds the threshold, only is allowed to pass to the output2. The mathematical calculation of output level is defined by:
Attack: The time, measured in milliseconds, that the compressor takes to apply full gain reduction once the input signal crosses the threshold2. Slower attack times () let the initial punch of speech consonants pass through unaffected, maintaining natural intelligibility and transients17.
Release: The time, measured in milliseconds, that the compressor takes to cease gain reduction and return to unity gain once the signal drops back below the threshold2. A moderate release time () ensures that the compression fades out smoothly between words without causing audible pumping17.
Makeup Gain: The static amplification applied to the compressed signal to restore the overall level lost during the peak reduction process, effectively raising the average volume of quieter passages2.
To achieve a highly consistent, polished vocal level without introducing audible pumping or distortion, engineers utilize serial compression17. This technique cascades two or more compressors in a row with gentle settings, rather than forcing a single compressor to do all the heavy lifting17.
Multi-Sensory Convergence and Hybrid Video-Audio Engineering
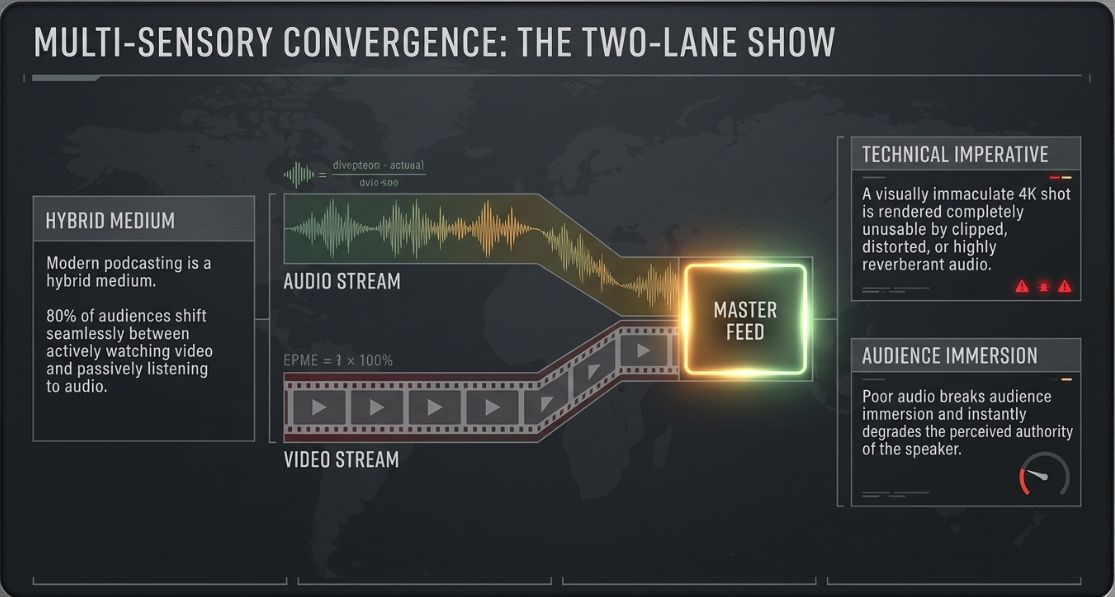
The "Two-Lane" Show Strategy
Modern professional podcasting has evolved into a hybrid "two-lane" medium3. Because an estimated 80% of audiences seamlessly shift between actively watching a video stream and passively listening to an audio track depending on their immediate environment, the production strategy must satisfy both the visual requirements of video platform algorithms and the passive accessibility of traditional audio RSS feeds9. Success in this ecosystem requires a unified approach to video and audio engineering, as poor audio quality will ruin even the most pristine visual footage3. Distorted, clipped, or heavily reverberant audio breaks audience immersion and degrades the perceived authority of the speaker, rendering visually immaculate takes unusable3.

Chronological Stages of the Multi-Camera Post-Production Pipeline
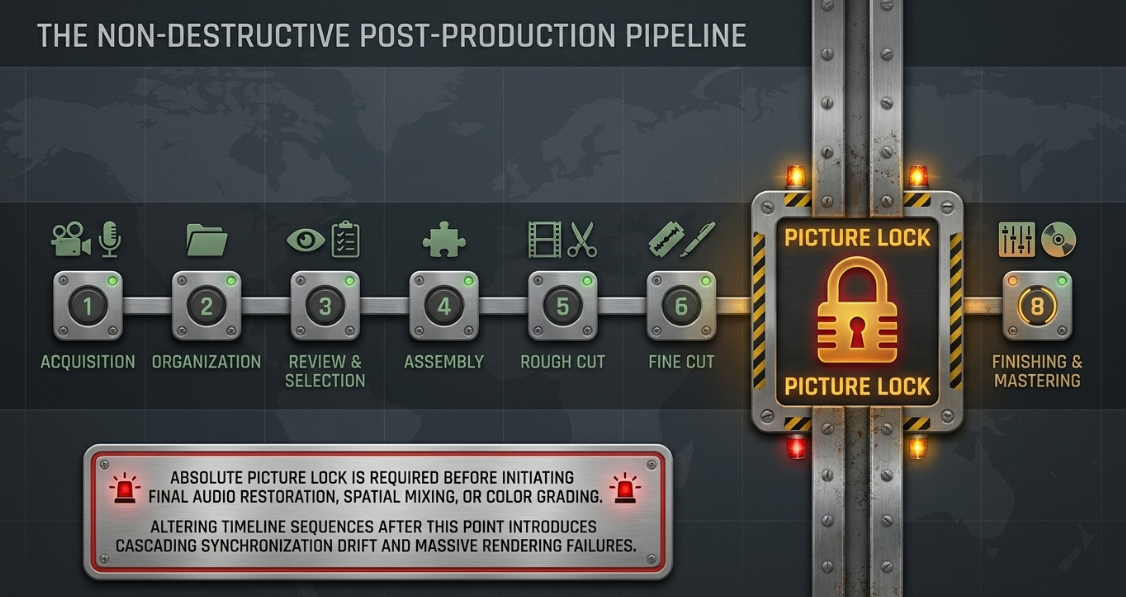
Integrating multi-camera video workflows with multi-track audio requires a strict, non-destructive editing pipeline to manage complexity and prevent synchronization failure3. Any breakdown in the early stages of this pipeline introduces cascading inefficiencies and synchronization drift, which routinely become the most significant recurring financial drain for ongoing productions3.
┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ Acquisition │───►│ Organization │───►│ Review & Sel.│───►│ Assembly │
└──────────────┘ └──────────────┘ └──────────────┘ └──────────────┘
│
┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ▼
│ Finishing │◄───│ PICTURE LOCK │◄───│ Fine Cut │◄───┌──────────────┐
│ & Mastering │ └──────────────┘ └──────────────┘ │ Rough Cut │
└──────────────┘ └──────────────┘
Within this chronological progression, each stage has specific technical demands3:
Acquisition: The ingestion of all recorded media, encompassing multi-camera video files, external audio recordings, and graphics3.
Organization: The meticulous logging, tagging, and structuring of raw data. Without rigorous metadata management and sensible file-naming conventions (such as ISO 8601 formatting), the efficiency of the entire pipeline degrades3.
Review and Selection: The critical evaluation of all footage to isolate optimal takes, identify errors, and pull stringouts3.
Assembly: The preliminary arrangement of selected clips into a chronological sequence, forming the skeletal structure of the narrative3.
Rough Cut: A refined version of the assembly where pacing is established, redundant material ("visual fat") is excised, and the narrative flow is tested3.
Fine Cut: A highly polished iteration where micro-adjustments to frame timing are made, ensuring seamless transitions, visual cuts on action, and emotional beats3.
Picture Lock: The critical milestone where no further alterations to the sequence timing or clip duration will occur3. This is an absolute prerequisite before initiating color grading or audio mixing to prevent synchronization failure3.
Finishing, Mastering, and Delivery: The finalization of visual effects, color correction, and audio mastering, followed by exporting the media into optimized codecs for various distribution platforms3.
Color-Grading Contrast Manipulation: Y'CbCr versus RGB Luma Spaces
During the finishing stage, color grading is performed to establish a polished, cinematic look3. The approach to managing contrast highlights a key technical parallel to audio processing3:
Y'CbCr Space Adjustments: Operating within the Y'CbCr space completely decouples the luminance (Y) channel from the chroma (Cb, Cr) channels3. Adjusting contrast here manipulates pure brightness without inducing aggressive, unintended saturation shifts, making it highly effective for normalizing exposure while maintaining clinical color neutrality3.
RGB Luma Space Adjustments: Modifying contrast in the RGB color space simultaneously affects the red, green, and blue channels3. Pushing the RGB channels higher to increase brightness inherently drives saturation and chromaticity upward, which can be creatively beneficial but is dangerous for maintaining clinical neutrality3.
Technical Loudness Standards and Platform Compliance
The final stage of the post-production process is mastering, where the integrated loudness of the program is measured and normalized in accordance with the ITU-R BS.1770-4 standard31. This standard defines the Loudness Unit relative to Full Scale (LUFS), which approximates how human hearing perceives sound pressure level over time, incorporating K-frequency weighting and dual-threshold gating to ensure subjective consistency across different program types31.

The measurement algorithm defined by ITU-R BS.1770-4 operates over a specified integration interval34. The mathematical formula for integrated loudness is defined by:
where represents the set of active channels, is the channel-weighting coefficient, and is the mean square of the K-weighted filtered signal in channel 34.
To prevent lossy attenuation, downward leveling, or peak clipping on major streaming networks, engineers must target platform-specific integrated loudness levels and True Peak limits9.
Definitive Engineering Recommendations
To ensure absolute signal integrity, consistent translation across playback systems, and compliance with modern distribution specifications, the following technical protocols must be strictly enforced:
Conduct All Tracking and Processing at 24-bit Lossless Resolution: All recording, editing, and dynamic processing must occur using uncompressed WAV files at a sample rate of and a bit depth of 6. Bouncing heavily processed tracks down to new WAV files should be used strategically to relieve CPU loads and prevent real-time DSP playback stuttering6.
Enforce Rigid Level-Matching Protocols: To bypass the psychoacoustic bias of the "louder is better" phenomenon, engineers must level-match processed and unprocessed signals during all mixing evaluations2. Reference tracks of known excellence must be imported directly into the DAW to recalibrate the engineer's ears, circumventing the acoustic anomalies of the mixing room and preventing subjective drift2.
Execute a Structured Equalization and Compression Chain: Vocal dialogue should undergo low-end high-pass filtering ( with a slope) to preserve headroom, followed by a wide bell-curve boost at to establish broadcast weight19. Surgical notches should be applied between to eliminate boxiness19. Dynamics should be managed using a serial compression workflow—utilizing a fast-acting compressor to catch transient peaks, followed by a slow-acting compressor to smooth out average levels17.
Target Integrated Loudness Standards for Final Export: The master output must be calibrated to meet platform-specific integrated loudness standards calculated in accordance with the ITU-R BS.1770-4 specification33. For spoken-word podcasts, the final mix must target with a True Peak maximum of 9, exported as a monaural MP3 at a Constant Bit Rate of 6.
Freeze the Editorial Timeline Prior to Mastering: In hybrid video-audio workflows, the editing timeline must achieve absolute Picture Lock before initiating final audio restoration, spatial mixing, or color grading3. This protects the project from synchronization drift and prevents rendering failures3.
Works cited
Podcast Marketing for a Professional Show - Finchley Studios, https://www.finchley.co.uk/finchley-learning/visual-podcast/podcast-marketing-for-a-professional-show
Audio Engineering in a Professional Podcast Post-Production - Finchley Studios, https://www.finchley.co.uk/finchley-learning/visual-podcast/audio-engineering-in-a-professional-podcast-post-production
Video Engineering in a Professional Podcast Post-Production - Finchley Studios, https://www.finchley.co.uk/finchley-learning/visual-podcast/video-engineering-in-a-professional-podcast-post-production
What Is a Podcast Studio and Why Does It Matter for Audio Quality? - Finchley Studios, https://www.finchley.co.uk/finchley-learning/visual-podcast/what-is-a-podcast-studio-and-why-does-it-matter-for-audio-quality
Roey Izhaki Mixing Audio | Book Review | Chapters 1 to 3, https://williamssoundstudio.com/pages/mixing-audio-book-review-ch1-3.php
Audio Execution for a Professional Podcast - Finchley Studios, https://www.finchley.co.uk/finchley-learning/visual-podcast/audio-execution-for-a-professional-podcast
Post-Production Fixes for Bad Remote Audio: What Is (and Isn't) Possible - Finchley Studios, https://www.finchley.co.uk/finchley-learning/visual-podcast/post-production-fixes-for-bad-remote-audio-what-is-and-isnt-possible
Strategic Pre-Production for a Professional Podcast - Finchley Studios, https://www.finchley.co.uk/finchley-learning/visual-podcast/strategic-pre-production-for-a-professional-podcast
Video Execution of a Professional Podcast - Finchley Studios, https://www.finchley.co.uk/finchley-learning/visual-podcast/video-execution-of-a-professional-podcast
Mixing Audio; Concepts, Practices, and Tools; 4, https://api.pageplace.de/preview/DT0400.9781000883978_A46030541/preview-9781000883978_A46030541.pdf
Step-by-step Mixing Audio Concepts Practices and Tools 4th Edition Izhaki Roey complete guide | PDF | Sound Production - Scribd, https://www.scribd.com/document/1021286093/Step-by-step-Mixing-Audio-Concepts-Practices-and-Tools-4th-Edition-Izhaki-Roey-complete-guide
Mixing Audio, https://api.pageplace.de/preview/DT0400.9781317508519_A31470162/preview-9781317508519_A31470162.pdf
Mixing Audio 9781138859784 - eBay, https://www.ebay.com/itm/398031215404
Mixing Audio by Roey Izhaki | Concepts, Practices, and Tools | 9781032219448 | Booktopia, https://www.booktopia.com.au/mixing-audio-roey-izhaki/book/9781032219448.html
Mixing Audio: Concepts, Practices, and Tools - Roey Izhaki - Google Books, https://books.google.com/books/about/Mixing_Audio.html?id=8v3BEAAAQBAJ
Mixing Audio Concepts Practices and Tools 4th Edition Izhaki Roey Ebook Direct Download, https://www.scribd.com/document/1006104557/Mixing-Audio-Concepts-Practices-and-Tools-4th-Edition-Izhaki-Roey-ebook-direct-download
7 Advanced Voice Over Sound Effects Tips for Pro Audio in 2026 | SFX Engine, https://sfxengine.com/blog/voice-over-sound-effects-tips
4 Dynamics Processing Techniques for Better Vocals - Waves Audio | Blog, https://www.waves.com/dynamics-processing-techniques-for-better-vocals
The Etiology and Remediation of "Tinny" Audio in Podcast Production - Finchley Studios, https://www.finchley.co.uk/finchley-learning/visual-podcast/the-etiology-and-remediation-of-tinny-audio-in-podcast-production
The Future of Podcasting: An Exciting Audio Revolution - Finchley Studios, https://www.finchley.co.uk/finchley-learning/the-future-of-podcasting-an-exciting-audio-revolution
Reducing Microphone Artefacts in Live Sound - QMRO Home, https://qmro.qmul.ac.uk/xmlui/bitstream/handle/123456789/8383/Clifford_A_PhD_Final.pdf?sequence=1&isAllowed=y
The Physics and Perception of Reverberation and Echo: A Comprehensive Acoustical Analysis - Finchley Studios, https://www.finchley.co.uk/finchley-learning/visual-podcast/the-physics-and-perception-of-reverberation-and-echo-a-comprehensive-acoustical-analysis
When should a noise gate be applied? - Sound Design Stack Exchange, https://sound.stackexchange.com/questions/37675/when-should-a-noise-gate-be-applied
Essential Equipment for Video Podcasting - Finchley Studios, https://www.finchley.co.uk/finchley-learning/essential-equipment-for-video-podcasting
Izotope RX 12 Advanced - Plug-ins | Woodbrass, https://www.woodbrass.com/en-gb/plug-ins-izotope-rx-12-advanced-p433429.html
The Ultimate Guide to Compression | Black Ghost Audio, https://www.blackghostaudio.com/blog/the-ultimate-guide-to-compression
How and Why to Use Serial Compression | Blog - Waves Audio, https://www.waves.com/how-and-why-to-use-serial-compression
Advanced Overcomplication -OR- Compression Madness | Going to 11, https://www.goingto11.com/advanced-overcomplication-or-compression-madness/
Podcast Video Episodes: Leveling Up Content Using “Adobe Video Editing”, https://www.finchley.co.uk/finchley-learning/podcast-video-episodes-leveling-up-content-using-adobe-video-editing
LUFS Loudness Normalizer Online — Free Podcast Normalizer - Notevibes, https://notevibes.com/audio-loudness-normalizer
Loudness metering – MiRA, https://doc.flux.audio/mira/Metering_Loudness.html
Optimizing Podcast Audio: Achieving -16 LUFS Without Distortion - Music Radio Creative, https://hub.mrc.fm/c/podcasting-tips/optimizing-podcast-audio-achieving-16-lufs-without-distortion
RECOMMENDATION ITU-R BS.1770-3* - Algorithms to measure audio programme loudness and true-peak audio level, https://www.itu.int/dms_pubrec/itu-r/rec/bs/R-REC-BS.1770-3-201208-S!!PDF-E.pdf
Streaming Audio Loudness Guidelines Explained - Radio World, https://www.radioworld.com/tech-and-gear/tech-tips/streaming-audio-loudness-guidelines-explained
Loudness, RMS, and Peak, Oh My! - Alison Pitt, https://www.alisonpitt.com/blog/2017/11/22/loudness-rms-and-peak-oh-my











