
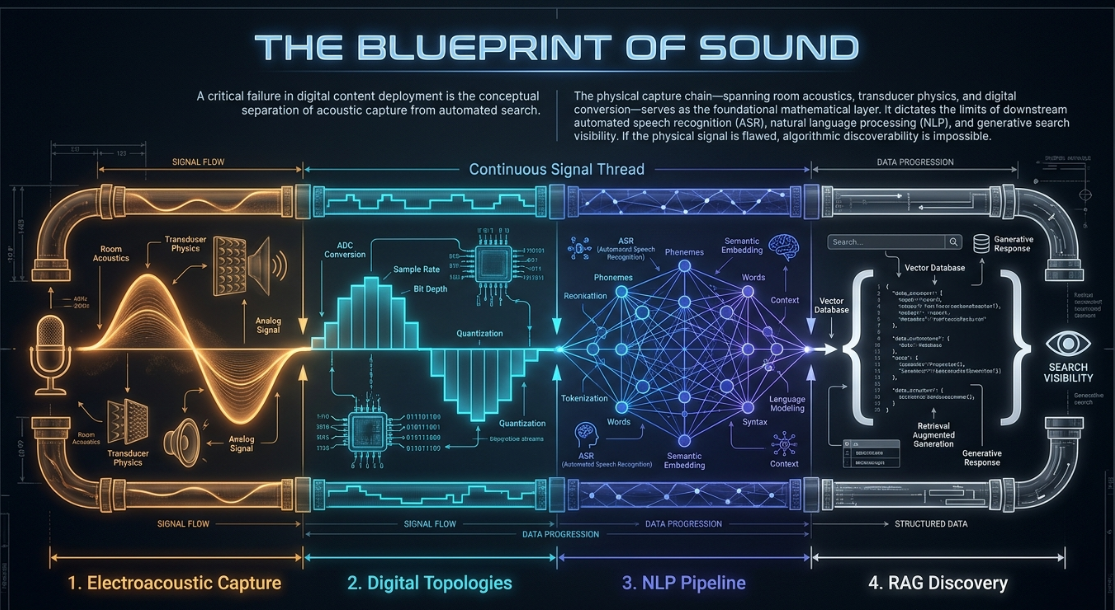
The optimization of a modern podcast requires a holistic systems-engineering approach that connects physical electroacoustic design directly to downstream computational linguistic indexing. A common point of failure in digital content deployment is the conceptual separation of acoustic capture from automated search and generative indexing systems. In practice, the physical capture chain—spanning room acoustics, transducer physics, analog-to-digital conversion, and spatial synchronization—serves as the foundational layer that determines the mathematical limits of downstream automated speech recognition (ASR), natural language processing (NLP), and semantic search visibility.
Structural Electroacoustics and Environmental Isolation Systems
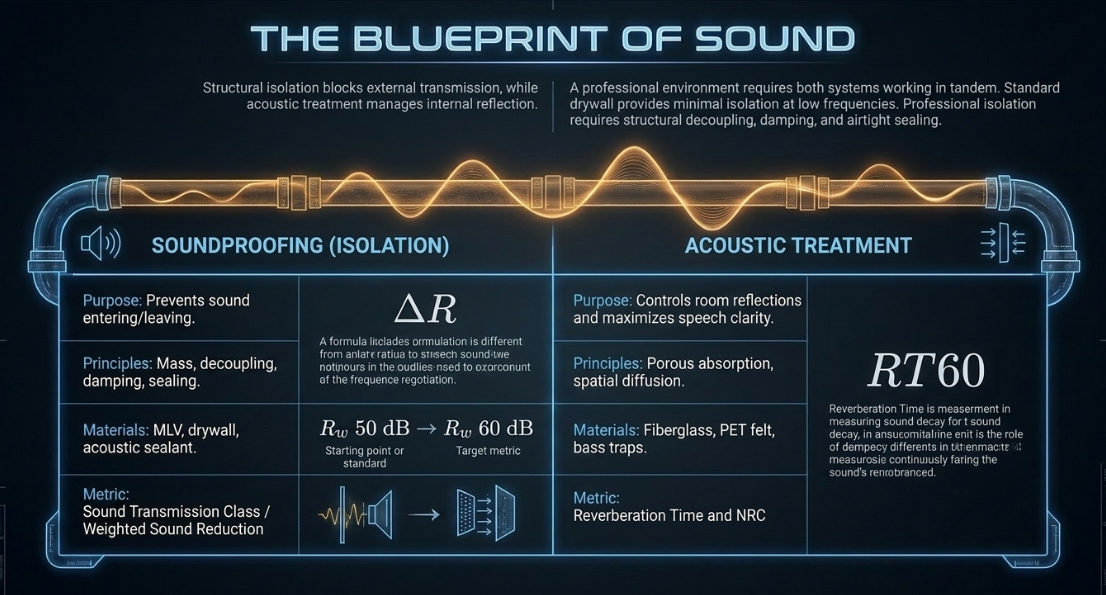
Designing a professional recording environment requires a clear distinction between soundproofing and acoustic treatment1. Soundproofing is an isolation mechanism designed to block sound transmission between the interior recording space and the external environment2. Conversely, acoustic treatment manages the reflection, absorption, and diffusion of sound waves within the room itself to optimize speech clarity and tonal balance2.
Structural Soundproofing and Transmission Loss
Soundproofing is governed by the physical principles of mass, decoupling, damping, and sealing2. Airborne sound waves transfer energy into structural partitions, turning walls, ceilings, and floors into physical transmitters of vibration3. To attenuate these vibrations, one must apply the mass law, which states that the transmission loss of a monolithic partition is proportional to its surface mass and the frequency of the sound. The change in transmission loss () when altering partition mass can be mathematically modeled by:
This relationship shows that doubling the surface mass of a partition yields a theoretical increase of approximately in transmission loss1. In practice, standard single-layer drywall partitions (with a surface weight of approximately ) offer minimal isolation at low frequencies, providing a nominal of reduction at , at , and only at 1.
To achieve professional isolation ratings, typically ranging between weighted sound reduction indexes of to , structural decoupling is required5. Decoupling breaks the physical connection between structural faces (such as double-stud frames or resilient channels), interrupting the path of vibration2. This structural isolation must be combined with high-density damping layers, such as Mass Loaded Vinyl (MLV) or dense mineral wool, and complete airtight sealing using acoustic caulk, as even a minor air gap can degrade the isolation class of a partition2.
Acoustic Treatment and Reverberation Control
Once a space is isolated, internal acoustic energy must be managed to prevent reverberation and standing waves2. When a speaker projects voice energy, the sound waves strike hard surfaces (such as drywall, glass, and wood) and reflect back into the room, creating flutter echoes and room modes that muddy the recording2.
Acoustic treatment uses porous absorption to manage mid-to-high frequencies2. Materials like fiberglass or dense rock wool feature tiny, interconnected air channels7. When sound waves enter these pores, friction converts the acoustic kinetic energy into thermal energy7. The effectiveness of an absorbing material is rated by its Noise Reduction Coefficient (NRC), on a scale from (total reflection) to (total absorption)6. Professional studios target specific reverberation decay times, measured as (the time required for sound pressure to drop by from its initial level)5.
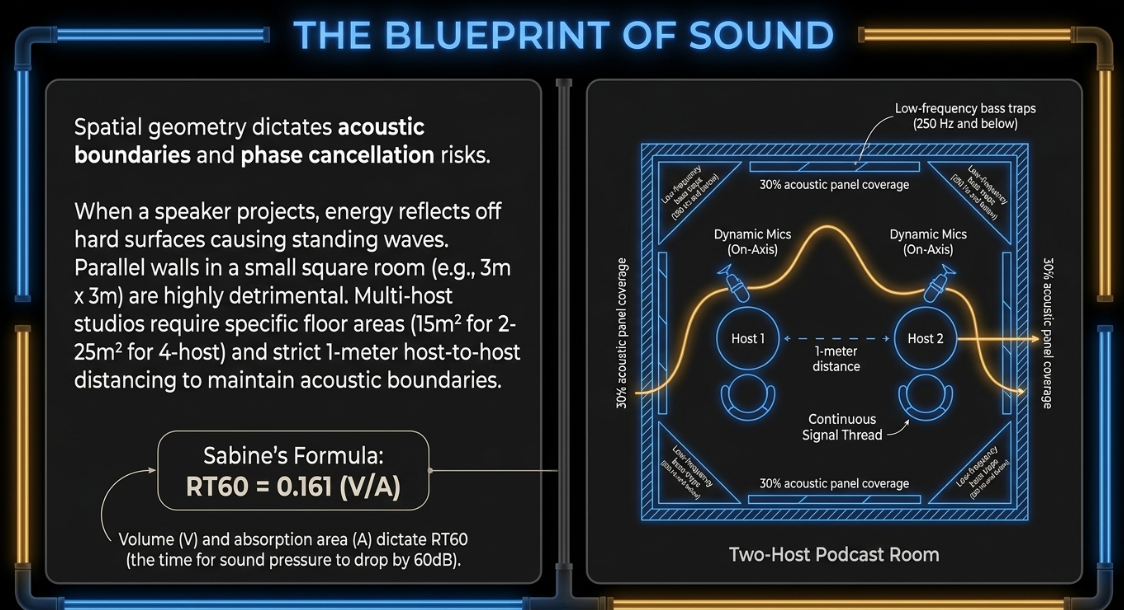
In this equation, represents the room volume in cubic meters, and represents the total equivalent absorption area in Sabins. For podcasting and spoken-word capture, the room must remain acoustically controlled yet tonally natural5. Too much high-frequency absorption without low-end control creates an artificial "boomy" space3, whereas untreated rooms introduce reflections that degrade phonetic clarity7.
Parallel walls in a small square room (such as ) cause severe standing waves and flutter echoes5. A rectangular layout (such as ) distributes acoustic reflections more evenly, providing a better baseline for internal treatment5. For professional B2B or corporate podcasting, studios require a minimum floor area of for basic solo booths9. For multi-host layouts, a two-host room typically requires , while a four-person roundtable needs to maintain appropriate acoustic boundaries5.
To prevent phase cancellation and uneven signal levels, physical seating layouts must maintain a minimum host-to-host distance of 5. When designing multi-camera video podcasts, the layout must position cameras at eye level to frame speakers naturally, using wide and close-up angles5. If remote participants are visible on screen, monitoring displays must be placed along the primary camera sightlines to prevent the host from turning away from the microphone5. Lighting setups must follow a three-point model, incorporating a key light at a angle slightly above eye level, a dimmer fill light opposite to soften shadows, and a back hair light to separate the subject from the background9.
Acoustic and Spatial Layout (Top View)
[ Acoustic Panel 30% Wall Coverage ]
+-------------------[H2/H3]-------------------+
| |
| [Host 1] [Host 2] |
| Dynamic Mic Dynamic Mic |
| O O |
[Bass Trap] | \ / | [Bass Trap]
Corner Mount | \ <--- 1 Meter ----> / | Corner Mount
| \ / |
| O O |
| Camera 1 Camera 2 |
| Close-up Close-up |
| |
| Camera 3 |
| Wide-angle |
+---------------------------------------------+
[ Acoustic Diffuser ]
Low-frequency management is critical because low frequencies build up in room corners where boundaries meet2. Standard porous panels are too thin to absorb low-end wavelengths2. To resolve this, tuned bass traps or thick corner-mounted absorbers are required to attenuate low-end mud, typically around and below2.
Electroacoustic Transducer Dynamics and Analog Capture Chains
The selection of the microphone transducer and the design of the analog preamplification stage establish the base signal-to-noise ratio of the capture chain11.
Transducer Architectures
Microphones convert acoustic pressure waves into electrical voltage using distinct electromagnetic or electrostatic mechanisms13.
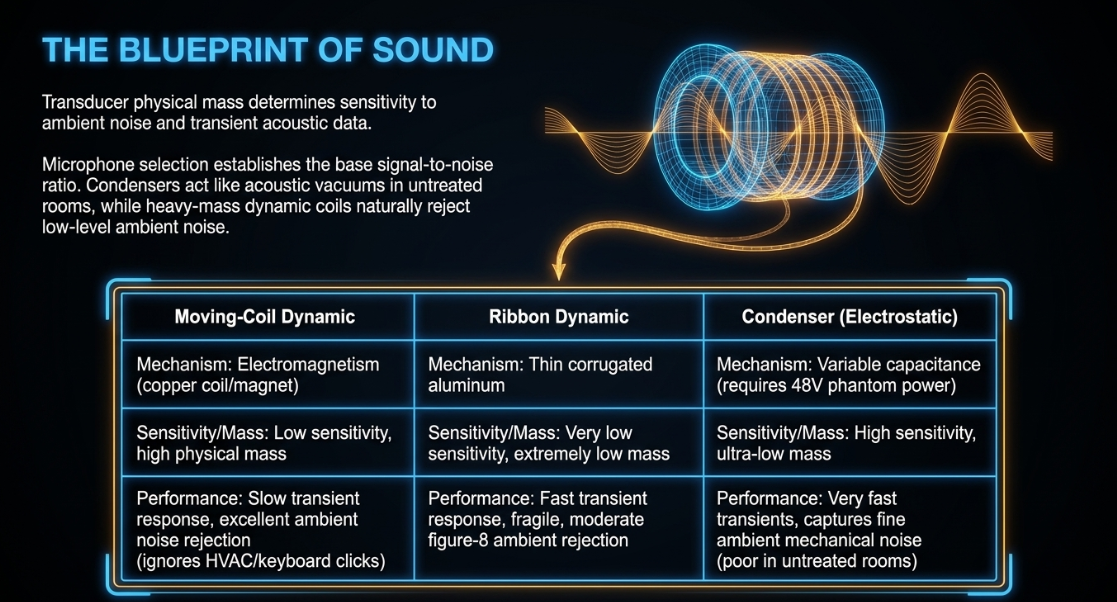
Moving-Coil Dynamic Microphones: These transducers use electromagnetism13. A lightweight diaphragm is attached to a fine copper voice coil suspended inside a permanent magnetic field13. As sound waves move the diaphragm, the coil vibrates within the magnetic field, generating an electrical signal13. Because of the physical mass of the coil, dynamic microphones have higher inertia, resulting in lower sensitivity and a slower transient response13. This physical limitation is advantageous in untreated home recording environments16. They require higher sound pressure levels (SPL) to actuate, making them naturally ignore low-level ambient room reflections, mechanical keyboard clicks, and heating ventilation air conditioning (HVAC) hiss15. Professional standard models include the Shure SM7B, Electro-Voice RE20, Shure SM58, and the Audio-Technica ATR2100x-USB9.
Ribbon Dynamic Microphones: A variation on electromagnetic induction, these microphones use an extremely thin corrugated aluminum ribbon suspended between magnetic poles14. The ribbon acts as both the diaphragm and the electrical conductor14. Because the ribbon has very low mass, it reacts quickly to rapid acoustic transients, providing a warm, linear frequency response14. However, their ribbon element is fragile and can easily deform from physical shock or strong blasts of air14.
Condenser (Electrostatic) Microphones: These microphones use variable capacitance13. The transducer capsule consists of an ultra-thin gold-sputtered diaphragm mounted parallel to a solid, charged metal backplate13. This system acts as a capacitor, storing electrical charge13. Physical vibration of the diaphragm alters the distance between the plate and the diaphragm, changing the capacitance and producing a proportional voltage variation13. This electrostatic design requires constant external power, typically phantom power, to polarize the capsule and run the internal impedance-converting preamplifier13. Condenser microphones have very low moving mass, enabling high sensitivity, rapid transient response, and a wide frequency range14. Standard models include the Audio-Technica AT2020 and AT203516. However, this sensitivity makes them less forgiving in noisy or reflective rooms, as they capture the entire acoustic environment along with the speaker’s voice15.
Polar Pattern Performance
The physical design of the microphone capsule determines its spatial sensitivity, mapped as polar patterns19.
Cardioid (120° Angle) Supercardioid (100° Angle) Figure-8 (Front/Rear)
[ 0° ] [ 0° ] [ 0° ]
.---^- ---. .- -^- -. .---^- ---.
/ \ / \ / \
| (Pickup) | | (Pickup) | | (Pickup) |
90° - - - - 270° 90° - - - - 270° 90° - - - - 270°
| | \ / \ / | |
\ Null / '--' '--' \ (Pickup) /
'---v-----' [ 180° ] '---v-----'
[180°] (Rear Lobe) [180°]
Cardioid: This pattern features a heart-shaped directional pickup with maximum sensitivity at on-axis () and a deep null at off-axis ()14. It rejects about two-thirds of ambient sound compared to an omnidirectional pattern, making it standard for speech capture14. It has a nominal acceptance angle of 16.
Supercardioid and Hypercardioid: These directional patterns offer a narrower on-axis acceptance angle ( for hypercardioid)16. They provide greater side rejection than cardioids but introduce a rear sensitivity lobe at 19. To maintain isolation, any ambient noise sources (like computer fans or street-facing windows) must be placed at the pattern's null points (typically around for supercardioids and for hypercardioids)19.
Figure-8 (Bidirectional): This pattern is equally sensitive at and , with complete nulls at and 19. It is useful for face-to-face interviews where speakers are positioned in the front and rear lobes, as it rejects side-wall reflections19.
Omnidirectional: This pattern has equal sensitivity across a full field14. While it lacks proximity effect and has a natural bass response, it captures excessive room ambience14. Consequently, it is rarely used outside of professionally treated acoustic spaces14.
Preamplification, Gain Staging, and Equivalent Input Noise (EIN)
Gain staging is the process of optimizing signal levels through each amplification step to maximize the signal-to-noise ratio while preventing clipping12. This process is critical when using low-output dynamic microphones21.
The Shure SM7B is a gain-hungry dynamic microphone with a low sensitivity of 21. Under typical speech levels at a distance of three inches (producing an acoustic pressure of approximately ), the microphone outputs a signal of 22. To bring this microphone signal up to a standard digital operating line level (approximately ), the preamplifier must supply at least of clean analog gain21.
Legacy or entry-level audio interfaces often feature low-cost preamplifier chips that max out at to of gain22. When pushed to their limits, these preamplifiers introduce significant thermal self-noise, resulting in an audible hiss21. To evaluate this self-noise, one must examine the Equivalent Input Noise (EIN) specification of the preamplifier21. EIN measures the noise floor added by a preamplifier, expressed in decibels relative to () with the input terminated by a resistor to simulate a standard microphone load23.
In practice, high-performance preamplifiers achieve EIN ratings of to 21. If an interface has a noisy preamplifier (with an EIN of or worse), applying the of gain required for a dynamic microphone will amplify the noise floor along with the voice signal21.
Historically, this issue required using inline preamplifiers (such as the Cloudlifter, FetHead, or sE Dynamite)21. These active, phantom-powered devices provide to of clean analog boost before the signal reaches the audio interface21. This allows the interface's built-in preamplifier to operate at a lower, cleaner gain setting21. Shure integrated this active circuitry directly into the SM7dB, which offers switchable or internal gains22.
Modern fourth-generation audio interfaces, such as the Focusrite Scarlett 4th Gen or the Antelope Audio Zen Quadro, feature high-performance analog preamplifiers that deliver up to of clean gain with EIN values of 21. These interfaces eliminate the need for external inline boosters, providing clean analog headroom directly through a simplified signal path21.
To accurately diagnose ambient and hardware noise contributions, engineers utilize the National Institute of Standards and Technology (NIST) Speech Quality Assurance (SPQA) tool27. The NIST SPQA tool calculates Root Mean Square (RMS) power levels within a sliding 20ms window, building a power histogram that isolates continuous noise from transient speech27.
Furthermore, aggregate SNR metrics often fail to predict true transcription degradation because they average high-frequency noise bands27. The AVG11 metric, which averages the signal-to-noise ratio of the first eleven frequency bins below , serves as a more reliable predictor27. Low-frequency bands are critical for phonetic speech recognition; when these bands are degraded by hum or HVAC rumble, the Word Error Rate increases sharply even if the overall broadband SNR appears acceptable27.
Digital Sampling Architectures and Synchronization Metrics
Once a signal is acoustically captured and amplified, it must be digitized9. This stage requires selecting the appropriate bit depth, sample rate, and synchronization protocol5.
Analog-to-Digital Conversion: 24-Bit Integer vs. 32-Bit Floating-Point
Bit depth determines the dynamic range and quantization noise floor of a digital audio file12. The maximum signal-to-noise ratio (SNR) for a linear fixed-point integer system is calculated using:
Here, represents the bit depth30.
24-Bit Fixed-Point (Integer) Conversion: This format provides of theoretical dynamic range30. In a standard recording workflow, the audio signal is mapped to a fixed linear scale where the maximum voltage corresponds to (Decibels Full Scale)28. If the input analog voltage exceeds the maximum range of the analog-to-digital converter (ADC), the waveform clips at 28. This digital clipping shears off the peaks of the audio waveform, creating harmonic distortion that cannot be corrected in post-production28. To avoid this, recording engineers must set conservative input gain levels, leaving adequate "headroom" (typically to ) to absorb sudden verbal peaks31.
32-Bit Floating-Point Conversion: This format uses a binary scientific notation format defined by the IEEE 754 standard32. The are split into , an , and a 32. This floating-point architecture allows the scale to adjust dynamically32. It provides a theoretical dynamic range of approximately to 31. Because the maximum limit of this format is far beyond any physical sound pressure level, digital clipping is virtually impossible within the digital container31.
24-Bit Integer vs. 32-Bit Float ADC Topologies
[ 24-Bit Integer (Single ADC Stage) ]
Analog Input ----> [ Gain Preamp ] ----> [ Single ADC ] ----> Clipped if > 0 dBFS
[ 32-Bit Float (Dual ADC Stage) ]
+--> [ Low-Gain ADC (Optimized for High Peaks) ] ----+
| |
Analog Input ------+ +---> [ Digital Combiner ] ---> 32-Bit Float
| | (No Clipping)
+--> [ High-Gain ADC (Optimized for Noise Floor) ] ---+
32-bit floating-point recorders use a dual-ADC architecture to capture this wide dynamic range31. The analog signal is split and sent to two converters in parallel: a low-gain ADC optimized for loud peaks, and a high-gain ADC optimized for quiet details31. A digital signal processor monitors the input levels and seamlessly blends the data streams into a single 32-bit floating-point file32.
This technology is helpful for capturing unpredictable dynamic peaks without relying on analog limiters31. If a speaker screams and exceeds , the waveform is not clipped at the converter stage31. The operator can simply lower the gain in their digital audio workstation (DAW) to restore the unclipped waveform31.
However, 32-bit float is not a cure-all for poor audio practices32. If the acoustic input level exceeds the physical limits of the microphone capsule or analog preamplifier, the signal will distort before it ever reaches the ADC28. For controlled, in-studio speech sessions, a properly gain-staged 24-bit fixed-point setup remains highly efficient and avoids the increase in file size associated with 32-bit float files32. At a professional sample rate, one hour of mono 32-bit float audio requires of bandwidth, generating a file size of approximately per track, whereas a mixed multi-track poly-WAV file requires roughly of storage per hour of raw recording32.

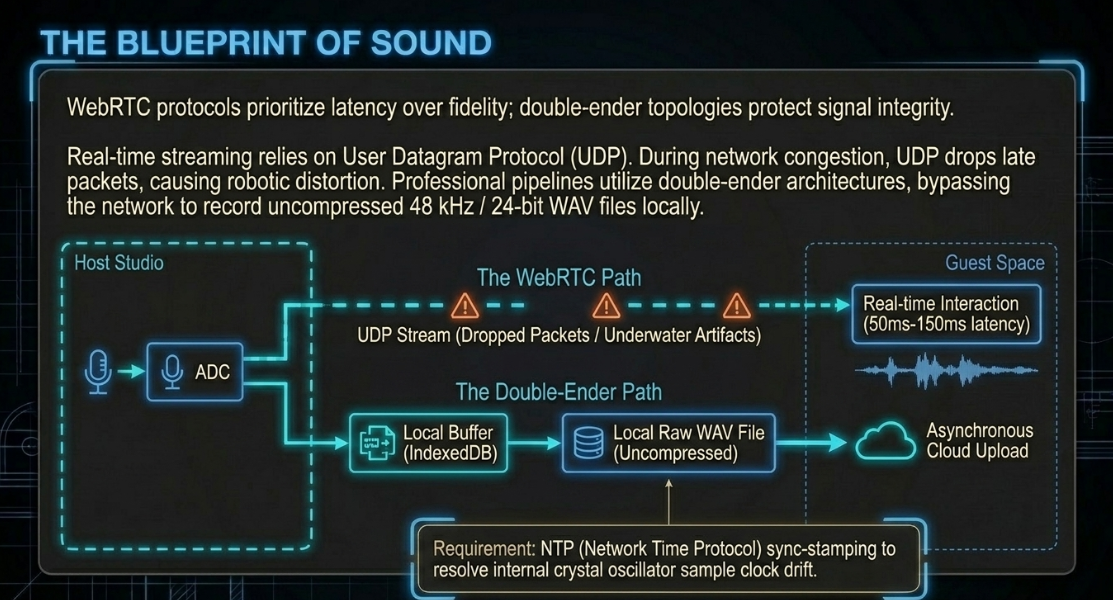
Remote Space Optimization: Double-Ender Capture vs. WebRTC Streaming
Modern remote podcasting relies on Web Real-Time Communication (WebRTC) for live interaction29. WebRTC prioritizes low latency (targeting sub-500ms delays) over audio quality29. To maintain this real-time speed over unpredictable internet connections, WebRTC protocols default to the User Datagram Protocol (UDP)29.
Unlike the Transmission Control Protocol (TCP), which guarantees the delivery of every data packet through retransmission loops, UDP prioritizes speed29. If network congestion occurs, UDP drops the late packets29. To the listener, these lost packets manifest as robotic distortion, digital clicks, or "underwater" audio artifacts29.
To bypass network limitations, remote platforms use a "double-ender" recording architecture29. Instead of recording the compressed audio stream transmitted over the internet, each participant’s browser records their microphone signal locally35. This local capture is saved as uncompressed, full-bandwidth WAV files (typically ) directly onto the user's local storage device29. Once the session ends, these high-fidelity tracks are asynchronously uploaded to the cloud for post-production assembly29.
Double-Ender Session Signal Topology
[ Host Studio ] [ Guest Space ]
Dynamic Mic Condenser Mic
| |
Analog Preamp Analog Preamp
| |
[ ADC ] [ ADC ]
| |
+---> [ WebRTC / UDP Stream ] ---> (Real-time Interaction) <--+
| |
|---(Local Buffer)--> [ Raw WAV File ] [ Raw WAV File ] <--+
| |
+---> (Asynchronous Post-Upload)
Remote recording is managed by dedicated software suites such as Riverside, StreamYard, SquadCast, and VDO.Ninja29. For professional video pipelines, platforms capture local video at bitrates of (approximately five times the bitrate of typical video conferencing streams)37. To optimize bandwidth and storage, advanced architectures implement the AV1 codec on compatible devices, reducing required transmission speeds by compared to standard H.264 profiles37.
To protect recordings from browser or system crashes during a session, modern double-ender platforms write temporary audio chunks into the browser's local IndexedDB database37. If a user accidentally refreshes their browser tab, the platform can recover the cached chunks and resume recording without losing data37.
Using separate physical recorders introduces the challenge of sample clock drift36. The internal crystal oscillators in consumer computers fluctuate slightly based on temperature and manufacturing tolerances29. Over an hour-long recording, these timing differences can cause tracks to drift out of sync by several seconds36. Professional remote platforms resolve this by sync-stamping local files with Network Time Protocol (NTP) clocks, allowing automated alignment during post-production37.
Additionally, remote recording introduces latency that affects conversational flow29. In-person interactions have an average turn-taking latency of (including cognitive processing time)38. Remote calls over standard platforms introduce delays of to over , with Zoom sessions averaging of total round-trip latency29. This delay increases cognitive load and can disrupt fast-paced, collaborative formats like comedy or debates29.

The Speech-to-Text Pipeline: Physical Signal to Digital Vocabulary
The physical quality of the captured audio directly determines the performance of automated speech recognition (ASR) systems11.
ASR Architectures and Voice Activity Detection
Modern production-grade ASR systems have transitioned from complex pipelines of separate acoustic, pronunciation, and language models to end-to-end neural networks41. These transformer-based models directly map input audio waveforms to text sequences41. Large-scale models, such as Whisper, are trained on hundreds of thousands of hours of weakly supervised web audio, providing robust out-of-distribution generalization across various acoustic environments and accents42.
Processing long-form audio files (exceeding 15 minutes) using standard sliding-window attention mechanisms can cause attention degradation, leading to repetition and hallucinations42. To resolve this, systems use Voice Activity Detection (VAD) algorithms, such as WhisperX's "Cut & Merge" strategy42. VAD segments continuous audio into smaller, sentence-level chunks based on silent intervals42. This pre-segmentation keeps processing within the model's optimal context window, reducing hallucinations and speeding up processing times to faster than real-time11.
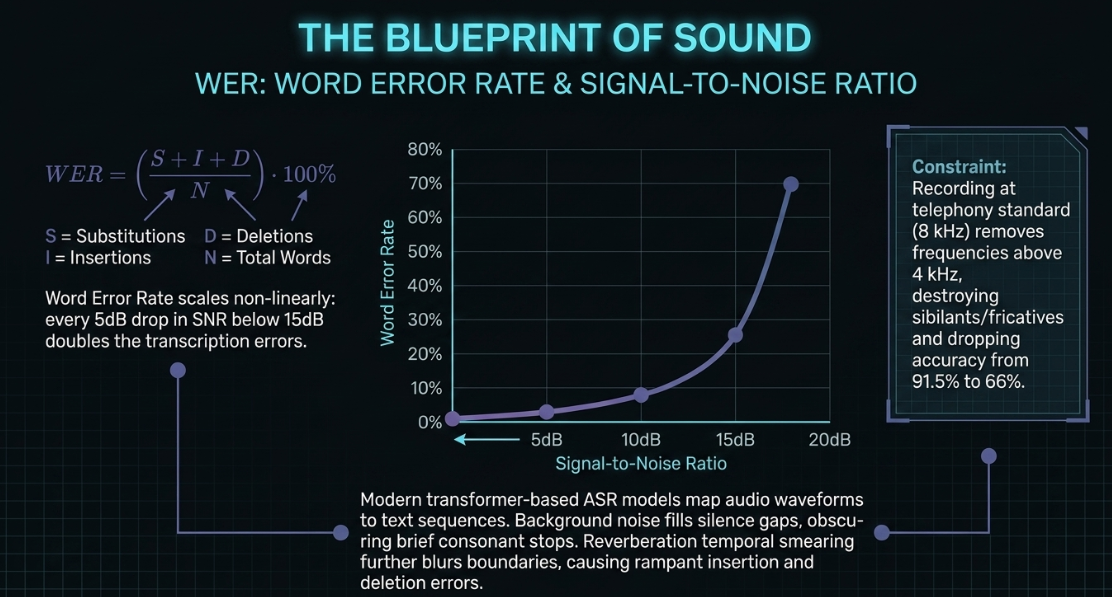
Quantifying Acoustic Degradation on Word Error Rate (WER)
The standard metric for evaluating ASR transcript accuracy is the Word Error Rate (WER)11. Based on the Levenshtein distance, WER measures the edit distance between an ASR hypothesis and a human-verified ground-truth reference transcript11. It is calculated using the following formula:
In this equation:
represents the number of word substitutions (e.g., transcribing "sit" instead of "sat")11,
represents the number of word insertions (adding words not present in the audio)11,
represents the number of word deletions (omitting spoken words)11,
is the total word count in the reference transcript8.
Because insertions add words to the transcript, WER can theoretically exceed 27. Under ideal laboratory conditions, modern ASR models can achieve single-digit WERs45. However, real-world field conditions—characterized by ambient noise, reverberation, and compression—can degrade performance significantly11.
When the Signal-to-Noise Ratio (SNR) drops, ASR performance scales non-linearly39. A general rule of thumb is that every drop in SNR below approximately doubles the Word Error Rate39.
ASR Word Error Rate vs. Signal-to-Noise Ratio
80% +------------------------------------------------------------*
| /
70% | /
W 60% | /
E | /
R 50% | /
40% | /
R 30% | *
a | /
t 20% | /
e 10% | *------------*
| *-------------*
0% +----------------------^-------------^-------------^---------^
20 dB 15 dB 10 dB 5 dB
Signal-to-Noise Ratio
This performance drop occurs because background noise fills the silence gaps in the audio27. This obscures the subtle frequency transitions and brief consonant stops that ASR models use to differentiate phonemes11.
Furthermore, high reverberation () causes late reflections to overlap with direct speech8. This temporal smearing blurs word boundaries, leading to deletion and insertion errors8.
Low sample rates also limit the high-frequency information available to the model11. Recording at telephony standards () removes frequencies above , which are essential for recognizing sibilants and fricative consonants (like /s/, /f/, and /th/)11.
Additionally, lossy compression codecs (such as low-bitrate MP3 or AAC) remove subtle acoustic details, introducing digital artifacts that the neural network can misinterpret as speech8.
These acoustic challenges are compounded by speaker variations, such as accents and regional dialects8. If an ASR model is trained primarily on standard broadcast American English, its accuracy will drop when processing regional or non-native accents8.
ASR accuracy is also affected by conversation length and speaker demographics40. Short utterances (ranging from four to eight words) typically yield higher error rates (averaging ) than longer, structured sentences47. Shorter utterances provide less contextual data for the system's language model to resolve acoustic ambiguities47.
Furthermore, historical training sets can introduce algorithmic bias40. A landmark 2020 study published in the Proceedings of the National Academy of Sciences (PNAS) revealed that major commercial ASR systems had nearly double the error rates for African American speakers () compared to Caucasian speakers ()40.
Conversely, downstream tasks like automated speaker attribution (identifying speakers by their voice profiles) are highly resilient to transcription errors48. Speaker attribution models rely on structural patterns such as utterance length and stylistic choices rather than exact word accuracy48. Even on heavily degraded transcripts with error rates exceeding , these models can identify speakers with high accuracy48.

Downstream Natural Language Processing and Semantic Error Rate
While Word Error Rate is the industry standard for evaluating transcription quality, it is a lexical metric that does not account for semantic meaning11. For example, if a speaker says "The medication is approved," and the ASR system transcribes it as:
"The medication is a proved," or
"The medication is not approved."
In both cases, the ASR transcript has a single-word substitution error, resulting in an identical calculated WER11. However, the second substitution completely reverses the semantic meaning of the sentence, dropping its semantic accuracy to zero11.
To address this limitation, system designers utilize the Semantic Error Rate ()49. This metric evaluates whether a transcript preserves the speaker's original intent49. To compute semantic error, both the ground-truth reference and the ASR transcript are converted into normalized vectors using pre-trained sentence transformer models49. The semantic similarity is then calculated using cosine similarity49:
Here, and represent the high-dimensional vector embeddings of the reference and hypothesis sentences49. The Semantic Error Rate is derived from this similarity score49.
When transcription errors affect key nouns, proper names, or negations, they propagate downstream into Natural Language Understanding (NLU) pipelines11.
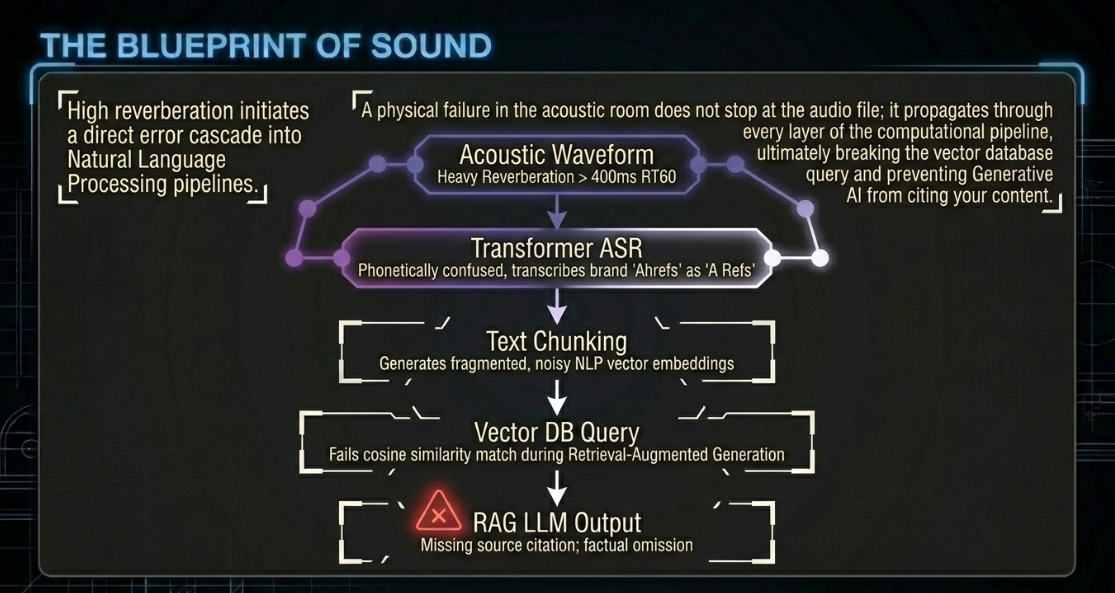
Downstream NLP Error Propagation
[ Acoustic Waveform ] --------> Heavy Reverberation (RT60 > 400ms)
|
[ Transformer ASR ] ----------> Transcribes "Ahrefs" as "A Refs"
|
[ Text Chunking ] ------------> Generates fragmented, noisy embeddings
|
[ Vector DB Query ] ----------> Fails cosine similarity match
|
[ RAG LLM Output ] -----------> Missing source citation; factual omission
These error cascades can degrade downstream performance:
Entity Extraction: If a technical term is transcribed incorrectly (e.g., transcribing the SEO tool "Ahrefs" as "A Refs"53), name-entity recognition models will fail to detect it11.
Vector Database Retrieval: In Retrieval-Augmented Generation (RAG) pipelines, noisy transcripts produce distorted vector embeddings49. When queried, these chunks fail cosine similarity matches, preventing the retrieval system from identifying relevant content49.
Code and Syntax Processing: In specialized domains, minor transcription errors can completely break downstream tasks52. A single substituted symbol or incorrect letter in an acronym can prevent code understanding and API execution models from functioning52.
To evaluate performance across different platforms, developers utilize benchmarks like the Open ASR Leaderboard or the Artificial Analysis composite index, which test systems against real-world business datasets42. These evaluations show that while underlying model weights are identical, latency and processing costs can vary up to ten times across different cloud hosting providers42.
Strategic Search Engine and Generative Answer Optimization
As search behavior shifts from keyword matching to AI-driven answer engine optimization (AEO), structuring and formatting transcribed podcast content has become critical for organic visibility51.
Platform-Specific Search Algorithms
Traditional podcast directories operate on distinct, platform-specific indexing and ranking signals57.
Apple Podcasts: Apple's directory relies on metadata fields (such as show titles, episode titles, author fields, and category tags) to build its index58. To improve visibility, keywords should be placed at the front of these text fields58. Apple Podcasts also natively transcribes audio files to power its in-app search58. Consequently, speaking clearly and using natural key terms during a recording directly improves discoverability58. User actions, such as subscription velocity (how quickly a show gains new followers in its first eight weeks) and review volume, also influence the platform's ranking algorithms57.
Spotify: Spotify's recommendation engine relies heavily on user behavioral metrics, such as completion rate (especially hook retention within the first 60 seconds of an episode)57. For search, Spotify indexes episode titles, show titles, and episode descriptions58. It uses collaborative filtering to suggest episodes based on a user's listening history and genre preferences58.
Google / YouTube Music: Since the closure of Google Podcasts, Google uses YouTube Music as its primary audio destination57. Google can index audio transcripts to surface episodes for long-tail search queries55. Episodes backed by detailed show summaries, timestamped navigation, and clean web transcripts receive higher organic indexing priority55.
Platform-Specific Indexing Paradigms
[ Apple Podcasts ] ------> Metadata-centric; index-driven via titles and authors
[ Spotify ] -------------> Engagement-driven; prioritizes completion and hook rates
[ Google / YouTube ] ----> Hybrid text indexing; processes transcriptions and transcripts
Retrieval-Augmented Generation (RAG) and Generative Search Visibility
Generative AI platforms (such as ChatGPT, Perplexity, and Google Gemini) do not rank web pages using traditional authority signals like PageRank54. Instead, they use Retrieval-Augmented Generation (RAG) to find and synthesize answers51.
When a user asks a question, the RAG system vectorizes the query and performs a hybrid search51. This hybrid approach combines semantic vector searches (using cosine similarity to capture meaning) with lexical keyword matching (using algorithms like BM25 to locate precise proper nouns and technical terms)54. This hybrid method improves retrieval accuracy by up to compared to single-method searches61.
Once the most relevant text chunks are retrieved, they are fed into a Large Language Model (LLM) as context, which synthesizes a response and cites its sources51. To ensure transcribed podcast content is selected and cited by these generative answer engines, it must be optimized for machine readability51.
One metric used to evaluate content for generative retrieval is the Information Density () formula56:
In this formula:
represents the count of unique named entities (such as brands, product names, or technical terms)56,
represents the number of specific, verifiable factual claims56,
represents the total word count of the text chunk56.
Raw, unedited ASR transcripts often contain repetitive filler words, false starts, and grammatical loops53. This conversational noise inflates the total word count () without adding new entities () or facts (), diluting the information density51.
Additionally, unformatted transcripts present as massive walls of continuous text without paragraph breaks or structural markers53. This lack of structure makes it difficult for chunking algorithms to extract coherent segments51.
To optimize transcriptions for generative search engines, one must apply structural optimization strategies:
Hierarchical Markdown Formatting: Use descriptive, keyword-rich H2 and H3 subheadings to segment the transcript51. These headers act as signposts for chunking algorithms, ensuring the retrieved text blocks maintain semantic context51.
Concise Paragraph Chunking: Keep discussion topics within focused, self-contained paragraphs of approximately to words56. These concise blocks are easier to embed accurately and fit cleanly within an LLM's context window51.
Entity-Rich Language: Use specific proper nouns and technical terms rather than generic pronouns (e.g., repeating the brand or product name instead of using "it" or "they") to improve the vector database's retrieval accuracy56.
AI platforms also display distinct behavior when citing web sources56. In Google’s search ecosystem, there is a correlation between top organic search results and Google AI Overview citations56. However, only of these cited URLs directly match the absolute first position in the organic listings56.
Additionally, search bots prioritize fresh, up-to-date content56. Analytics show that of AI crawler hits target content published within the past year, while target material updated within the last two years56.
Structured Metadata Implementation (Schema.org JSON-LD)
To help search engines index podcast content, one should implement structured data using Schema.org vocabulary expressed via JSON-LD (JavaScript Object Notation for Linked Data)62. This code should be embedded within the HTML of the episode's web page, typically inside the <head> or just before the closing </body> tag63.
By defining the explicit relationships between the podcast series, host, guest, and audio assets, structured schema markup creates clear connections that generative search engines can parse63.
Below is an annotated, production-ready JSON-LD template illustrating the implementation of PodcastSeries, PodcastEpisode, and nested AudioObject schemas:
HTML
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@graph": [
{
"@type": "PodcastSeries",
"@id": "https://example.com/podcast/#series",
"name": "The Strategic Marketing Ecosystem",
"description": "An industry analyst's look at podcast production, audio engineering, and search discovery architectures.",
"url": "https://example.com/podcast/",
"image": "https://example.com/assets/artwork-3000.jpg",
"inLanguage": "en-US",
"publisher": {
"@type": "Organization",
"name": "Audio Engineering Media Group",
"logo": "https://example.com/assets/logo.jpg"
}
},
{
"@type": "PodcastEpisode",
"@id": "https://example.com/podcast/episode-47/#episode",
"partOfSeries": {
"@id": "https://example.com/podcast/#series"
},
"episodeNumber": "47",
"name": "Electroacoustics and ASR Pipeline Mechanics",
"description": "An analysis of Equivalent Input Noise, structural acoustic isolation, and the impact of signal degradation on Word Error Rate.",
"datePublished": "2026-03-30T08:00:00Z",
"timeRequired": "PT42M15S",
"url": "https://example.com/podcast/episode-47",
"associatedMedia": {
"@type": "AudioObject",
"contentUrl": "https://example.com/audio/episode-47.mp3",
"encodingFormat": "audio/mpeg",
"contentSize": "60840000"
},
"actor": [
{
"@type": "Person",
"name": "Dr. Arlan Vance",
"jobTitle": "Lead Acoustic Systems Architect"
}
],
"keywords": [
"Equivalent Input Noise",
"Acoustic Treatment",
"Word Error Rate",
"32-Bit Float",
"Search Engine Optimization"
],
"transcript": "https://example.com/podcast/episode-47#transcript"
}
]
}
</script>
Unified Production and Discovery Architecture Blueprints
To achieve maximum organic visibility, podcast production must be treated as a single continuous workflow11. Physical recording choices directly affect the mathematical performance of downstream search algorithms and AI engines11. By optimizing every stage of the capture and distribution pipeline, creators can improve transcript quality, enhance machine readability, and secure a higher volume of generative citations39.
Unified Production and Discovery Chain
[ Physical Room ] --------> Attenuates ambient noise to maximize SNR [cite: 2, 8]
|
[ Low-Noise Preamp ] ------> Lowers EIN to prevent analog hiss
|
[ Local Wav Capture ] -----> Prevents WebRTC packet loss and compression
|
[ VAD Segmented ASR ] ----> Produces high-accuracy, low-WER transcripts [cite: 11, 42]
|
[ Structured Formatting ] -> Optimizes Information Density for RAG
|
[ JSON-LD Schema ] --------> Feeds structured metadata to AI crawlers [cite: 63, 64]
High-Fidelity Capture Chain Specifications
Environmental Targets: Prioritize structural mass and decoupling to keep the noise floor low2. The target should be between and to prevent late reflections from muddying the recording5.
Transducer Selection: Use directional moving-coil dynamic microphones in non-ideal or untreated rooms to naturally isolate the voice and block off-axis ambient noise15.
Preamplification and Conversion: Pair low-sensitivity microphones with preamplifiers that feature an Equivalent Input Noise (EIN) of or lower21. This ensures clean analog headroom without introducing thermal hiss21. Record in WAV format to maintain uncompressed signal integrity throughout the editing process11.
Remote Space Integration
Double-Ender Topologies: Avoid capturing compressed VOIP or WebRTC streams directly29. Use remote platforms that record uncompressed WAV audio locally on each participant's device, bypassing network jitter and packet loss29.
System Redundancy: Run a secondary, independent backup recorder (such as a dedicated hardware recorder or a local mobile app) on the guest's end29. This protects the session from data loss in the event of browser crashes or system hangs29.
Downstream Post-Processing and AI Engine Integration
ASR Optimization: Use ASR engines that feature Voice Activity Detection (VAD) pre-segmentation to process long files efficiently and prevent sliding-window hallucinations42. Maintain a localized dictionary of proper nouns, technical terms, and acronyms to improve name and entity recognition11.
Semantic Content Architecture: Transform raw transcripts into structured, reader-friendly content53. Break long transcripts into logical, self-contained paragraphs () separated by clear, hierarchical Markdown headers51. This structural optimization improves the information density of the text, making it easier for RAG pipelines to retrieve and cite51.
Structured Schema Deployment: Validate all pages using schema testing tools to ensure Google and other search engines can map the connections between the series, hosts, guests, and media assets63. Use JSON-LD PodcastEpisode and PodcastSeries markup to help search engine crawlers find and index the content63.
Works cited
Soundproofing vs Acoustic Treatment: 3 Costly Mistakes, https://www.acousticsinsider.com/blog/home-studio-soundproofing-3-big-mistakes-to-avoid
The Difference Between Sound Treatment and Soundproofing - WhisperRoom, https://www.whisperroom.com/blog/the-difference-between-sound-treatment-and-soundproofing
Soundproofing vs Acoustic Treatment: Key Differences - Mindz Connect, https://mindzconnect.com/difference-soundproofing-and-acoustic-treatment/
Soundproofing vs. Sound Absorption - Primacoustic - Polar UK, https://polar.uk.com/news/integrated-solutions/soundproofing-vs-sound-absorption
Podcast Studio Design Guide: Plan It Properly | Sound Zero, https://sound-zero.com/podcast-studio-design-guide/
Soundproofing vs Acoustic Treatment | Sound Zero, https://sound-zero.com/soundproofing-acoustic-treatment-difference/
Soundproofing and Acoustic Treatments for Your Podcast | Audimute, https://www.audimute.com/blog/soundproofing-and-acoustic-treatments-for-podcast/
Transcription Error Rates: Finding the Right Accuracy Balance for Your Organisation, https://discoveryalert.com.au/transcription-accuracy-standards-error-rates-2026/
How To Build a Podcast Studio - Setup For Every Budget - Saspod, https://saspod.com/blog/post/podcast-studio
Podcast Room Setup: The Ultimate Guide for B2B Brands - Goldcast, https://www.goldcast.io/blog-post/podcast-room-setup
Factors affecting the accuracy of speech-to-text transcripts - Gladia, https://www.gladia.io/blog/factors-affecting-the-accuracy-of-speech-to-text-transcripts
Understanding and Reducing Noise Floor for Recording and Live Sound - Gearnews.com, https://www.gearnews.com/understanding-and-reducing-noise-floor-studio-live/
What is the Difference Between Dynamic and Condenser Microphones? - Sweetwater, https://www.sweetwater.com/sweetcare/articles/what-difference-between-dynamic-condenser-microphones/
Mic Basics: Transducers, Polar Patterns, & Frequency Response - Shure United Kingdom, https://www.shure.com/en-GB/insights/microphone-basics-transducers-polar-patterns-frequency-response
Condenser vs Dynamic Microphone: Which Is Better for Gaming and Streaming?, https://www.turtlebeach.com/blog/condenser-vs-dynamic-microphone-gaming-streaming
Audio Solutions Question of the Week: How Do I Determine Which Podcasting/Streaming Microphone Will Work Best for Me?, https://www.audio-technica.com/en-us/support/audio-solutions-question-of-the-week-how-do-i-determine-which-podcasting-streaming-microphone-will-work-best-for-me
Dynamic vs Condenser Microphones: Which Is Best for Streaming and Podcasting? - Maplin, https://www.maplin.co.uk/blogs/expert-advice/dynamic-vs-condenser-microphones-which-is-best-for-streaming-and-podcasting
The Ultimate Guide to Podcast Studio Setup for Beginners - SF Cable, https://www.sfcable.com/blog/ultimate-guide-to-podcast-studio-setup-for-beginners
Microphone polar patterns - LEWITT Audio, https://www.lewitt-audio.com/blog/polar-patterns
The ultimate podcast equipment guide for creators, https://creators.spotify.com/resources/grow/podcast-equipment-guide
Best Audio Interface for SM7B — No Cloudlifter Needed (2026), https://proaudioreserve.com/blogs/news/best-audio-interface-for-sm7b-without-cloudlifter
Knowledge: SM7B Output Level and Preamp Gain Specifications - Shure, https://service.shure.com/articles/en_US/Knowledge/sm7-output-level-and-preamp-gain-specifications
Need an Audio Interface? For Shure SM7B, not sure what that means... - Reddit, https://www.reddit.com/r/podcasting/comments/wpzvw8/need_an_audio_interface_for_shure_sm7b_not_sure/
Best interface with enough gain for the SM7B and 4 inputs? : r/audio - Reddit, https://www.reddit.com/r/audio/comments/1dyy759/best_interface_with_enough_gain_for_the_sm7b_and/
SM7DB audio hiss, I am a bit concerned & need guidance - SOS FORUM, https://www.soundonsound.com/forum/viewtopic.php?t=91460
-70db noise floor - decent? - SOS FORUM, https://www.soundonsound.com/forum/viewtopic.php?t=78823
Using Audio Quality to Predict Word Error Rate in an Automatic Speech Recognition System - MITRE, https://www.mitre.org/sites/default/files/pdf/06_1154.pdf
32-Bit Conversion Explained - SSL Audio Interfaces, https://support.solidstatelogic.com/hc/en-gb/articles/18980367820061-32-Bit-Conversion-Explained-SSL-Audio-Interfaces
Remote Recording Platforms vs. In-Studio Sessions: A Technical Latency Analysis in London - Finchley Studios, https://www.finchley.co.uk/finchley-learning/visual-podcast/remote-recording-platforms-vs-in-studio-sessions-a-technical-latency-analysis-in-london
32-bit float recording depth vs. 24-bit: Complete Beginner Guide - Page 2 of 2, https://www.audiorecording.me/32-bit-float-recording-bit-depth-vs-24-bit-complete-beginner-guide.html/2
What is 32-bit Float Resolution? - Tascam Europe | Audio Recording Devices for Professionals and Hobbyists, https://www.tascam.eu/en/what-is-32-bit-float-resolution
Demystifying 32-Bit Float Audio: How It Works, and When It Doesn't | BOOM Library, https://www.boomlibrary.com/blog/demystifying-32-bit-float-audio/
32-bit float vs 24-bit for Recording [Archive] - Cockos Incorporated Forums, https://forum.cockos.com/archive/index.php/t-295284.html
Studio 2 – Podcast Guide, https://www.umt.edu/library/tech-spaces/studios/podcast-studio-2-guide.pdf
7 Top Video Interview Tools for YouTube - OfferGenie, https://offergenie.ai/blog/7-top-video-interview-tools-for-youtube
A Great App for Recording Podcasts - Allen Pike, https://allenpike.com/2014/podcast-recording/
Speed Space: Streamlining Remote Video Production for Distributed Teams (Tech Stack & Workflow, 2026) - Fora Soft, https://www.forasoft.com/blog/article/remote-video-production-speed-space
Remote Recording Platforms vs. In-Studio Sessions: A Technical Latency Analysis and London Studio Ecosystem Report - Finchley Studios, https://www.finchley.co.uk/finchley-learning/visual-podcast/remote-recording-platforms-vs-in-studio-sessions-a-technical-latency-analysis-and-london-studio-ecosystem-report
Speech Recognition Accuracy: Production Metrics & Optimization 2025 - Deepgram, https://deepgram.com/learn/speech-recognition-accuracy-production-metrics
Automatic Speech Recognition: The 2024 Comprehensive Guide - GoTranscript, https://gotranscript.com/en/blog/automatic-speech-recognition
What Is ASR? Automatic Speech Recognition Guide, https://www.camb.ai/blog-post/what-is-automatic-speech-recognition
AI Transcription Accuracy Research - BrassTranscripts, https://brasstranscripts.com/research/transcription-accuracy
Evaluation metrics for ASR - Hugging Face, https://huggingface.co/learn/audio-course/chapter5/evaluation
Word error rate is broken: How to actually evaluate speech-to-text in 2026 - AssemblyAI, https://www.assemblyai.com/blog/word-error-rate-is-broken
Word Error Rates (WER) for AI Transcription: What Do They Tell Us?, https://universitytranscriptions.co.uk/word-error-rates-wer-for-ai-transcription-what-do-they-tell-us/
How accurate is speech-to-text in 2026? - AssemblyAI, https://www.assemblyai.com/blog/how-accurate-speech-to-text
Evaluating the Accuracy of Automatic Speech Recognition Systems in Home Healthcare Settings - PMC, https://pmc.ncbi.nlm.nih.gov/articles/PMC12763410/
The Impact of Automatic Speech Transcription on Speaker Attribution - arXiv, https://arxiv.org/html/2507.08660v2
Semantic Error Rate: The Next ASR Accuracy Metric for Platform Builders - Deepgram, https://deepgram.com/learn/semantic-error-rate-asr-accuracy-metric
Evaluation of Automatic Speech Recognition Using Generative Large Language Models, https://arxiv.org/html/2604.21928v1
How AI Systems Decide What to Cite: The Technical Mechanics of LLM Content Retrieval, https://discoveredlabs.com/blog/how-ai-systems-decide-what-to-cite-the-technical-mechanics-of-llm-content-retrieval
Lost in Transcription: How Speech-to-Text Errors Derail Code Understanding - arXiv, https://arxiv.org/html/2601.15339v1
Why AI Transcripts Hurt Your Podcast SEO (And What To Do Instead) | Blog - Speechpad, https://www.speechpad.com/blog/ai-transcripts-hurt-podcast-seo
How LLMs and RAG Systems Retrieve, Rank, and Cite Content - Visively, https://visively.com/kb/ai/llm-rag-retrieval-ranking
What do y'all do with your episode transcripts in order to help SEO? : r/podcasting - Reddit, https://www.reddit.com/r/podcasting/comments/1t06o5y/what_do_yall_do_with_your_episode_transcripts_in/
LLM Citation Tracking: How AI Systems Choose Sources (2026 Research) | Ekamoira Blog, https://www.ekamoira.com/blog/ai-citations-llm-sources
Podcast SEO: How to Rank #1 on Spotify, Google & Apple Podcasts in 2026, https://www.jigsawkraft.com/post/podcast-seo-how-to-rank-1-on-spotify-google-apple-podcasts-in-2026
Mastering the Apple Podcasts and Spotify Algorithms to Maximize Your Visibility - Ausha, https://www.ausha.co/academy/podcast-search-optimization/apple-spotify-algorithms/
How to Rank Highly for Podcasts on Apple Podcasts and Spotify - Lemongrass Marketing, https://www.lemongrassmarketing.com/insights/how-to-rank-podcasts-spotify-apple-podcasts
Podcast SEO: How AI-Generated Transcripts Boost Your Search Rankings | SparkPod, https://sparkpod.ai/blog/podcast-seo-ai-transcripts
2025 AI Visibility Report: How LLMs Choose What Sources to Mention - The Digital Bloom, https://thedigitalbloom.com/learn/2025-ai-citation-llm-visibility-report/
Metadata: JSON-LD - Parse.ly Documentation, https://docs.parse.ly/installation-resources/parsely-integration/metadata/metadata-jsonld/
Podcast / Episode Schema Generator - Content Powered, https://www.contentpowered.com/tools/podcast-schema-generator/
Annotated JSON-LD Structured Data Examples - nystudio107, https://nystudio107.com/blog/annotated-json-ld-structured-data-examples
How to Use Schema Markup for Your Podcast - Outcast AI, https://outcast.ai/blog/how-to-use-schema-markup-for-your-podcast/
Implementing JSON-LD Structured Data with Next.js | Agility Docs, https://agilitycms.com/docs/nextjs/implementing-json-ld-structured-data-with-next-js
Podcast SEO: The Ultimate Guide to Making Audio Content Discoverable Across Search Engines & Apps | Hashmeta, https://hashmeta.com/blog/podcast-seo-the-ultimate-guide-to-making-audio-content-discoverable-across-search-engines-apps/











