
Introduction: The Neurocognitive Architecture of Speech Perception in Podcasts
Podcast post-production is fundamentally a cognitive intervention. The human brain is not a passive recording device, but an active, resource-constrained processor that continuously filters, parses, and reconstructs acoustic signals into linguistic and semantic meaning1. In the context of modern media consumption, where listening often occurs in noisy environments or during multitasking, the role of the audio engineer shifts from simple technical balancing to the preservation of cognitive bandwidth1.
When speech signals are degraded by background noise, room resonances, or harsh sibilance, the human auditory system must recruit secondary cognitive systems—including verbal working memory, attention-based performance monitoring, and the autonomic nervous system—to resolve phonemic ambiguities1. This recruitment of additional neural resources is defined as listening effort, a process that directly depletes finite cognitive capacity1.
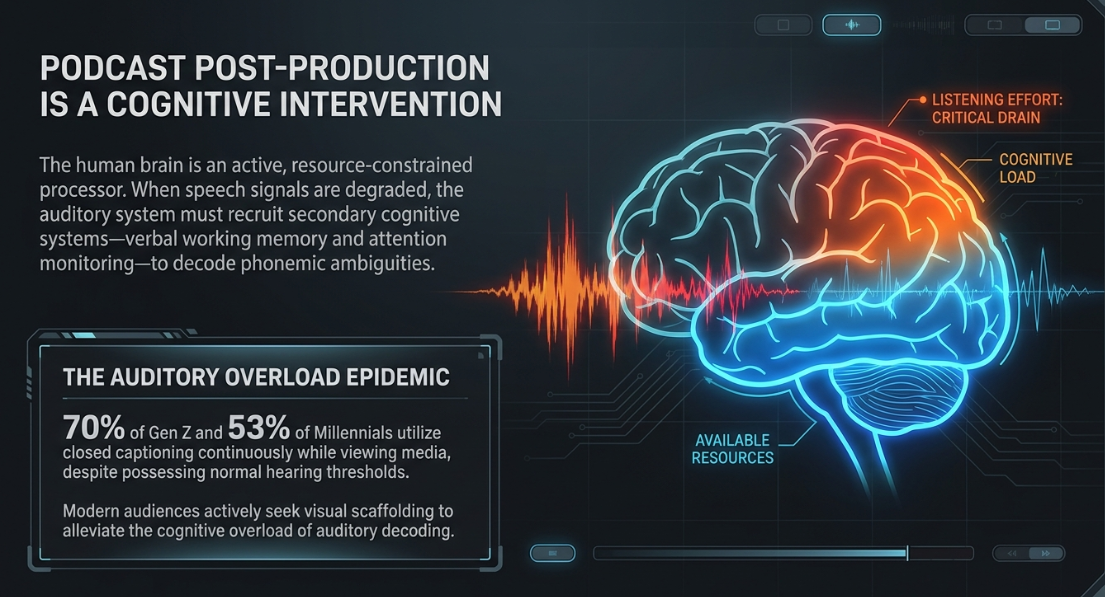
A notable societal shift corroborates this cognitive strain: recent surveys indicate that approximately 70% of Gen Z and 53% of Millennials utilize closed captioning features continuously while viewing media, despite possessing normal hearing thresholds7. This behavior signifies that modern listener demographics are actively seeking visual scaffolding to alleviate the cognitive overload of auditory decoding in everyday media consumption7. Understanding the neural mechanisms of auditory scene analysis, frequency masking, and spatial localization allows the engineer to design a mix that minimizes cognitive load, prevents listener fatigue, and maximizes retention8.
The FUEL Framework and the Neurophysiology of Auditory Fatigue
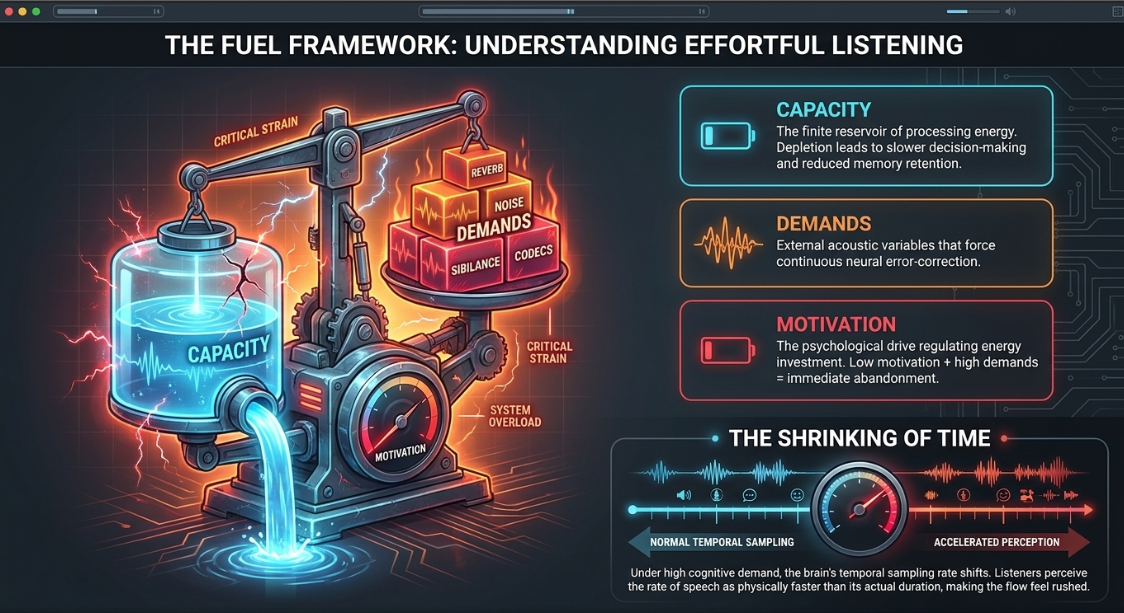
When speech is acoustically compromised, the cognitive load imposed on the listener increases exponentially, culminating in a physiological and psychological state known as listener fatigue1. The Framework for Understanding Effortful Listening (FUEL) maps the relationship between cognitive resources and auditory degradation through three core components: Capacity, Demands, and Motivation5.
The interaction of these factors determines the Quality of Experience (QoE) for speech listening6. Situational demands are heavily influenced by signal transmission factors—including accented speech, noise, reverberation, and message attributes such as vocabulary familiarity and semantic context5. Under high cognitive demand, the temporal sampling rate of the brain's sensory input shifts3. When processing speech under cognitive load, the brain perceives the rate of speech as being faster than its physical duration, a phenomenon termed the "shrinking of time"3. This systematic temporal distortion biases the listener's perception, making conversational flow feel rushed and raising the barrier to comprehension3.

Listener fatigue is accompanied by quantifiable physiological responses within the middle ear and the central nervous system10. When the ear canal is physically sealed by tightly fitting insert headphones, it behaves as a pressurized chamber, amplifying sound pressure waves and forcing the tympanic membrane to vibrate excessively14. The central nervous system reacts by triggering the stapedius acoustic reflex, which can dynamically attenuate acoustic transmission to the cochlea by up to in an attempt to protect delicate auditory structures14. However, because this reflex is a temporary coping mechanism, prolonged excessive acoustic pressure causes persistent muscular tension, leading to physical discomfort and headaches13.
Concurrently, prolonged exposure to elevated sound pressure levels or unmanaged high-frequency transients induces a temporary threshold shift13. Physiologically, the body reacts with vasoconstriction—reducing the oxygenated blood supply reaching the outer hair cells in the organ of Corti13. This metabolic exhaustion forces the inner hair cells to work under severe strain to process incoming signals, impairing the listener's sensitivity and frequency resolution over time13. High-frequency transients, harsh sibilance, and unbalanced spectral peaks trigger a mild fight-or-flight response in the autonomic nervous system4. This systemic stress response elevates laryngeal muscle tension in speakers and increases cardiovascular strain in listeners, making prolonged listening psychologically exhausting4.
The Psychoacoustic Underpinnings of Spectral and Spatial Auditory Scene Analysis
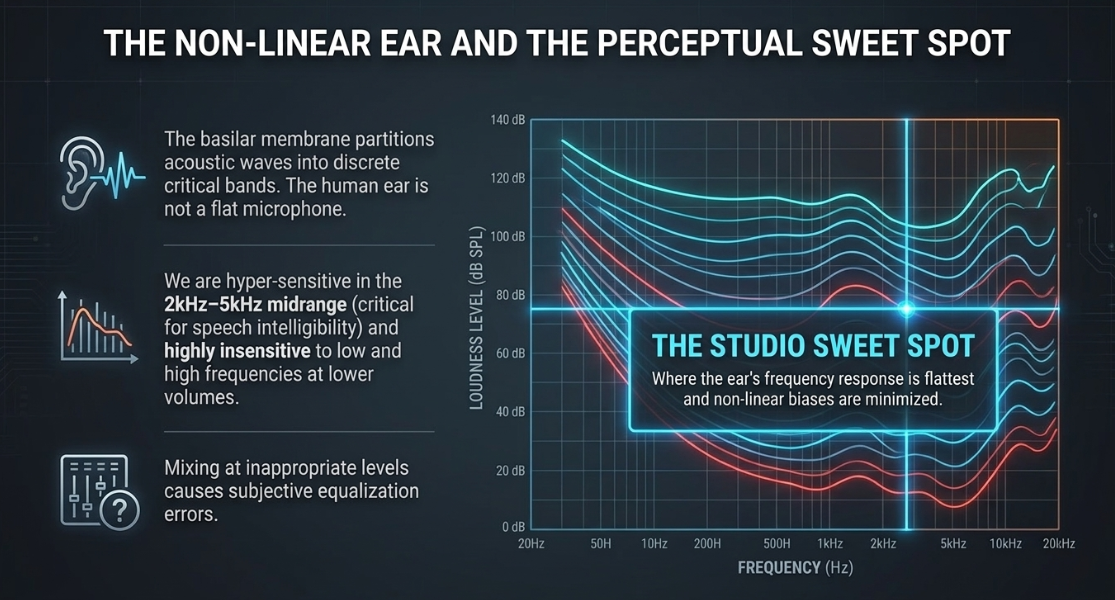
The human ear processes acoustic energy through a highly non-linear, adaptive physiological apparatus8. Rather than acting as a flat, objective measurement instrument, the ear-brain system introduces unique spectral and temporal distortions that must be managed during the post-production stage8.
The sensitivity of human hearing to sound pressure levels is heavily dependent on frequency8. Codified historically via the Fletcher-Munson curves, these equal loudness contours demonstrate that the human ear is highly sensitive in the midrange—specifically between and —which corresponds to the critical intelligibility bands of human speech16. Conversely, sensitivity to extreme low and high frequencies decreases significantly at lower listening volumes8.
Because of this non-linear response, mixing decisions made at inappropriate monitoring levels will fail to translate across consumer devices17. If a post-production engineer mixes at an excessively quiet level, they will naturally overcompensate by boosting the low and high frequencies, leading to a boomy and harsh mix when played back at a standard volume17. To minimize these subjective errors, industry practice dictates calibrating the mixing environment to a consistent reference level8. A sound pressure level of approximately to represents the perceptual "sweet spot," where the human ear's frequency response is relatively flat, and the impact of non-linear sensitivity is minimized17.
The basilar membrane in the cochlea acts as a biological real-time spectrum analyzer, partitioning incoming acoustic waves into discrete frequency regions known as critical bands8. When two distinct sound sources fall within the same critical band, they physically compete for the same neural pathways, causing auditory masking8. Masking is categorized into two primary mechanisms:
Energetic Masking: This occurs when a louder, physically overlapping sound obscures a quieter sound within the same critical band8. In podcast production, this manifests when low-frequency microphone rumble, room hum, or music beds share the to region with the fundamental resonance of a voice, clouding speech clarity24.
Informational Masking: This occurs at a higher cognitive level where, despite minimal spectral overlap, the listener's brain is unable to segregate the target speech from competing acoustic elements due to cognitive confusion23.
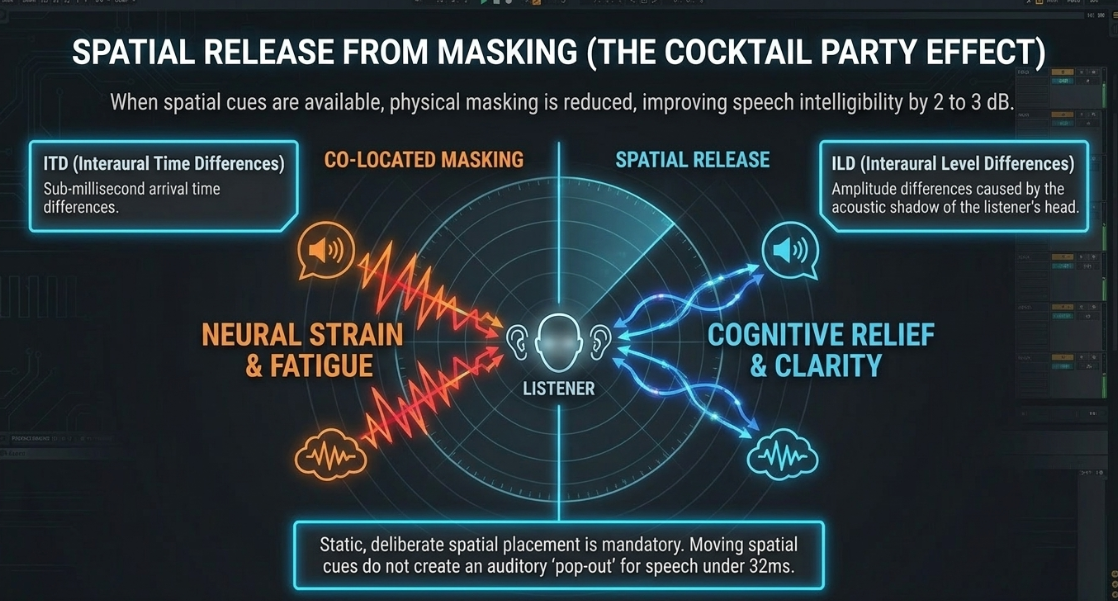
A powerful neural mechanism for reducing cognitive load in complex environments is Spatial Release from Masking (SRM)23. The "cocktail party effect" describes the brain's ability to focus on a single target talker while successfully ignoring competing background noises and other voices27. This neurocognitive segregation relies heavily on spatial hearing mechanisms29. When a target voice and a masking noise are co-located, originating from the same physical coordinate in space, the listener's brain must rely entirely on spectral differences to separate them, resulting in high cognitive effort and elevated speech reception thresholds27.
However, when the target voice and maskers are spatially separated, the brain leverages two primary interaural cues: Interaural Time Differences (ITD), representing the sub-millisecond arrival time difference of a sound wave between the left and right ear (dominant below ), and Interaural Level Differences (ILD), representing the amplitude differences of high-frequency waves caused by the acoustic shadow cast by the listener's head8. When spatial cues are available, physical masking is reduced, yielding a spatial release that can improve speech intelligibility by to or more, depending on the environment23.
Experimental testing indicates that even small spatial separations of to provide a significant release from informational masking23. Interestingly, research shows that while stationary spatial separation dramatically improves speech intelligibility, introducing moving target stimuli via active amplitude panning does not create an auditory "pop-out" effect for short-duration speech segments of less than 32. This implies that static, deliberate spatial placement is far more effective for speech clarity than dynamic panning32.
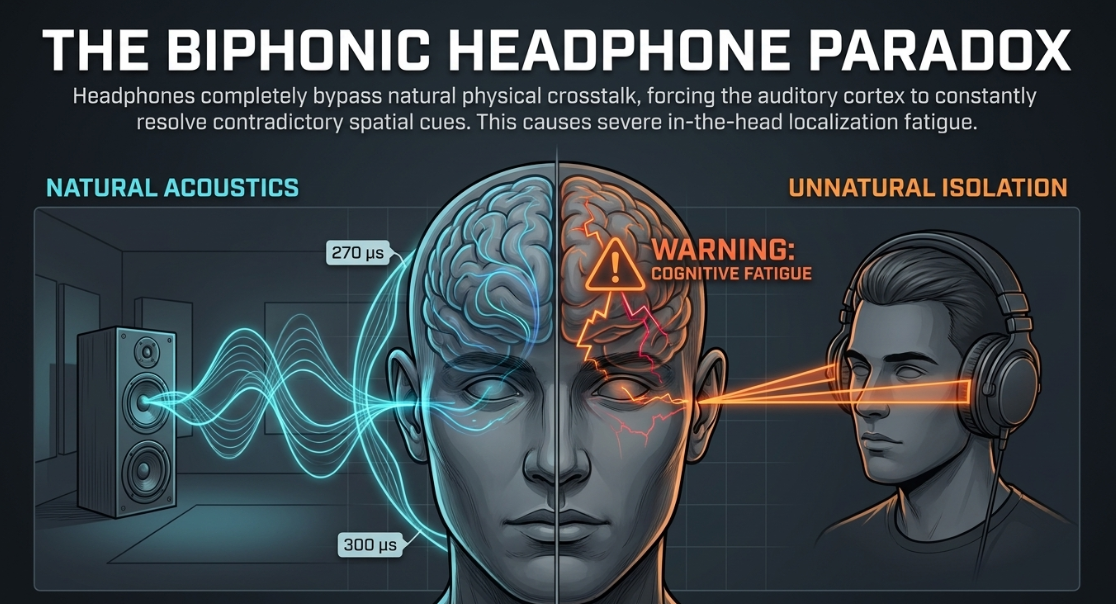
While panning voiceovers or background music beds left and right can mimic spatial separation, headphones create an unnatural acoustic environment19. In a physical acoustic space, sound waves from a left loudspeaker diffract around the head, reaching the right ear approximately to later, with a high-frequency attenuation of to due to the head shadow22. Headphones bypass this physical crosstalk entirely: the left channel goes strictly to the left ear, and the right channel to the right19. This complete channel isolation is an unnatural state33.
The lack of natural interaural crosstalk prevents the brain from accurately localizing sound sources, forcing the auditory cortex to work continuously to resolve contradictory spatial cues19. After approximately two hours of headphone listening, this cognitive struggle results in severe brain fatigue and a distinct loss of spatial perception19.
Post-Production Techniques for Pseudo-Stereo Imaging and Spatial Optimization
To bridge the headphone-to-speaker translation gap and optimize the spatial layout of mono vocal tracks, post-production engineers can implement several targeted spatialization strategies8.
A standard mono-to-stereo post-production technique involves duplicating the mono track, panning the resulting tracks equally and oppositely, and then applying a clean, non-destructive equalizer to slightly amplify high-frequency regions on only one of the channels to induce a pseudo-stereo spectral image35. Alternatively, the Precedence (Haas) effect can be exploited by introducing a short time delay of to on one of the panned channels8. While this technique generates an impression of stereo width, excessive delay or severe gain imbalance can render the center vocal image hollow, unstable, or prone to severe comb filtering during mono downmixing34.

To address channel isolation systematically, engineers utilize digital crossfeed processing to simulate natural acoustic crosstalk22. This simulation is modeled mathematically to calculate the left and right headphone outputs:
Where represents the ipsilateral gain (typically or to maintain decorrelation), represents the contralateral gain (typically or to emulate head shadow attenuation), and represents a discrete digital delay corresponding to a physical travel time of to 22.
This ensures that low-frequency interaural level and time differences are restored, simulating closely located nearfield monitors and preventing the brain from experiencing the "in-the-head" localization fatigue associated with unprocessed biphonic headphone playback33.
The Acoustics of Reverberation and the Speaking Clear Burden
Reverberation is a major acoustic contributor to listening effort and speech degradation37. In podcast mixing, excessive room reflections—often caused by recording in untreated domestic environments—interfere directly with phonemic decoding39.
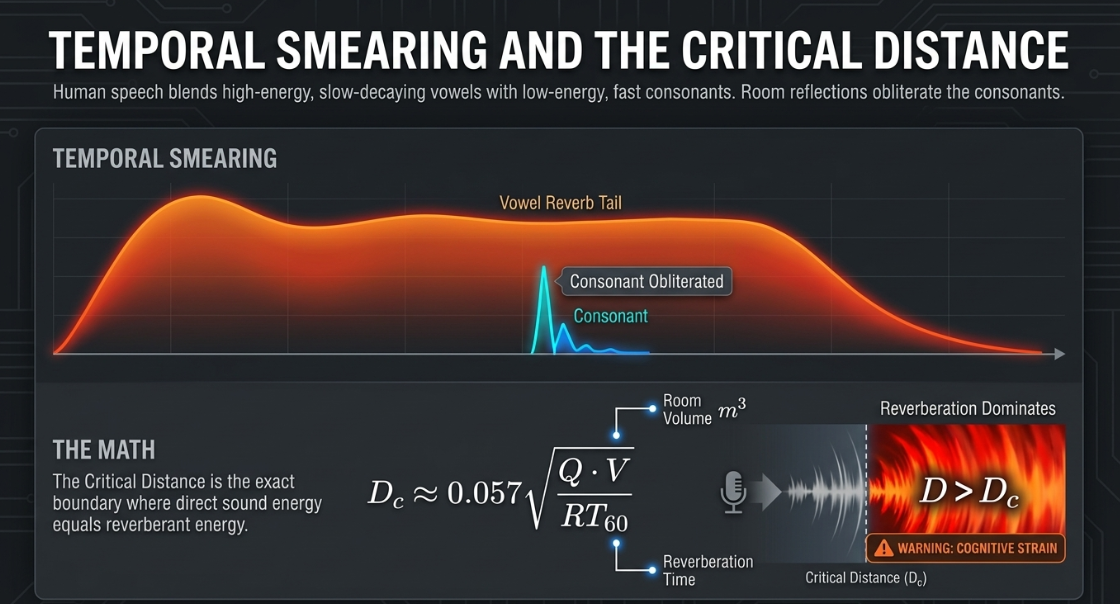
Human speech is composed of low-frequency, high-energy vowels and high-frequency, low-energy consonants40. Consonants contain the essential transient information required for word recognition and linguistic distinction37. When a voice is recorded in a highly reverberant room, the acoustic reflections from room boundaries travel along indirect paths, arriving at the microphone at varying delays relative to the direct signal11.
This delay creates a temporal smearing effect37. The high-energy, slowly decaying reverberation tail of a preceding vowel stretches out across time, filling in the natural silent gaps in speech and completely masking the quiet, high-frequency transients of subsequent consonants37. This temporal smearing reduces the Speech Transmission Index (STI), leading to word identification errors and a massive increase in listening effort1.
To understand the interaction between the physical environment and the speaker, the physical distance of the microphone must be evaluated relative to the room's critical distance ()11. The critical distance represents the spatial coordinate where the direct sound energy () exactly equals the reverberant energy ()11. This boundary is calculated using the Sabine equation:
Where is the directivity factor of the source, is the room volume in cubic meters (), and is the reverberation time in seconds11.
If the microphone is placed beyond this critical boundary (), the reverberant field dominates, causing a severe drop in the STI and rendering speech highly unintelligible11.
This degradation forces the speaker to adapt dynamically, often by employing clear speech or triggering the Lombard effect—a physiological response where the talker automatically increases vocal intensity, pitch, and duration in the presence of noise or reverberation37.
Remarkably, pupillometric data published in Scientific Reports demonstrates that speaking in a highly clear, enunciated style—often recommended as a low-effort strategy to combat environmental noise—imposes an autonomic and mental demand on the speaker comparable to speaking in a room with highly reflective, long reverberation times ( to )37. This challenges the traditional assumption that clear speech is a low-resource strategy39.
Consequently, ensuring high acoustic absorption at the source is critical not only for the listener's comprehension but also to prevent vocal fatigue and cognitive strain on the speaker37.
For listeners with sensorineural hearing loss or non-native speakers, the distortive effects of reverberation are significantly more pronounced9.
Non-native listeners lack the robust internal semantic and linguistic models required to intuitively "fill in" masked speech fragments, resulting in rapid cognitive exhaustion and auditory withdrawal when exposed to untreated reverberant recordings6.
To mitigate this, dynamic processing tools such as Wide Dynamic Range Compression (WDRC) with long release times can be utilized to stabilize the temporal envelope of speech, reducing envelope distortion and improving consonant clarity in highly reverberant environments43.
Surgical and Dynamic Spectral Engineering: Vocal Equalization and De-essing
In close-miked recording environments (where the speaker is positioned within centimeters of the microphone capsule), the proximity effect exaggerates low-frequency energy26. Consonants such as sibilants and plosives are amplified abnormally compared to natural, face-to-face conversational distances47.
To prevent physical air blasts from hitting the capsule, engineers recommend utilizing the off-axis recording technique—positioning the microphone relative to the speaker's face and angling the capsule back toward the mouth, allowing the breath to blow past the microphone while preserving high-frequency response41.
The Off-Axis Microphone Technique
[ Speaker's Mouth ]
|
| (Direct Speech Path)
v
\ |
\ (45 Degrees) |
[ Mic Capsule ] | (Plosive Blast Path)
v
During post-production, subtractive equalization serves as the primary tool to restore natural tonal balance and remove masking frequencies49. This workflow is detailed in the cheat sheet below:
To manage sibilance dynamically without altering the overall vocal character, engineers utilize de-essers47.
A de-esser functions as a dynamic processor whose sidechain detection circuit is filtered to isolate sibilant frequencies ( to for male voices; to for female voices)41.
When sibilant energy exceeds the threshold, the processor applies ultra-fast gain reduction to only the high-frequency band42.
For optimal transparency, a dual-stage sibilance reduction workflow is recommended: apply manual clip-gain attenuation to the harshest visual "esses" in the DAW waveform before the signal reaches the main compressor, followed by a gentle split-band or spectral de-esser post-compression to catch any sibilant peaks amplified by the leveling stage41.
In addition, resolving spectral conflicts between speech and background music beds is critical24.

While traditional sidechain compression ducks the entire volume of a music track when speech is present, it introduces a highly audible pumping effect24.
A more transparent solution is sidechain dynamic equalization, where the vocal signal triggers a dynamic EQ band on the music track24.
This selectively attenuates only the overlapping frequencies ( to ) in the music track when dialogue occurs, leaving the low-end energy and high-frequency air of the music bed untouched24.
While sidechain dynamic EQ provides excellent spectral isolation, physical analysis reveals that the rapid modulation of EQ filter coefficients is not mathematically silent58.
Depending on the digital filter design, rapid coefficient updates introduce inharmonic distortion and high-frequency digital noise that is completely uncorrelated with the source audio58.
The post-production engineer must therefore evaluate this noise floor tradeoff against the pumping artifacts of traditional broadband compression, selecting the tool that preserves the ultimate clarity of the program material58.
Loudness Engineering and Standardized Distribution: AES TD1008 and AES77-2023
To prevent listener annoyance caused by fluctuating volume levels between different podcasts, channels, and advertisements, the industry has established strict loudness standardization standards59.
The primary guidelines are outlined in the Audio Engineering Society's Technical Document AES TD1008 and the Recommended Practice standard AES77-202360.
Loudness is quantified using Loudness Units relative to Full Scale (), which incorporates K-weighting filters to approximate the human ear's frequency-dependent sensitivity59.
The biquad filtering structure used in K-weighting meters is represented mathematically as:
This filter cascades a high-shelving pre-filter (to simulate head-shadow acoustics) with a high-pass filter (to simulate low-frequency roll-off), ensuring that low-frequency rumble does not bias the perceived loudness measurement59.
AES TD1008 provides specific target recommendations for streaming and on-demand distribution channels61:
The difference in targets between speech () and music () addresses a fundamental psychoacoustic mismatch: when speech and music are normalized to the exact same integrated value, human listeners perceive the speech as being to louder than the music due to the concentration of speech energy in the ear’s most sensitive midrange bands63.
By maintaining a offset, streaming networks achieve a seamless, perceptually balanced transition between spoken podcasts and musical tracks63.
During the mastering stage of podcast production, engineers must conform to these distribution targets62.

To achieve standard compliance without introducing transient distortion, a high-quality brickwall limiter must be configured at the end of the master signal chain66.
The limiter’s output ceiling must be set to (Decibels True Peak) for standard speech content, and lowered to if the content undergoes highly aggressive processing or high-frequency saturation66.
This safety margin provides sufficient headroom for lossy audio codecs (such as or ) to compress and encode the file for distribution without introducing inter-sample clipping and audible digital distortion, ensuring a high-quality, fatigue-free listening experience8.
Works cited
Listening Effort: How the Cognitive Consequences of Acoustic Challenge Are Reflected in Brain and Behavior - PMC, https://pmc.ncbi.nlm.nih.gov/articles/PMC5821557/
The cognitive load of listening activities of a cognitive-based listening instruction - Semantic Scholar, https://pdfs.semanticscholar.org/533a/a9351877d6cfafaac6baef83ab7bf50fbf7b.pdf
Cognitive load makes speech sound fast, but does not modulate acoustic context effects, https://www.mpi.nl/publications/item2368295/cognitive-load-makes-speech-sound-fast-does-not-modulate-acoustic-context
Changes in Relative Fundamental Frequency Under Increased Cognitive Load in Individuals With Healthy Voices - PMC, https://pmc.ncbi.nlm.nih.gov/articles/PMC8608166/
Enhancing patient care: A framework for understanding effortful listening - Audiology Blog, https://audiologyblog.phonakpro.com/enhancing-patient-care-a-framework-for-understanding-effortful-listening/
Listening Effort Informed Quality of Experience Evaluation - Frontiers, https://www.frontiersin.org/journals/psychology/articles/10.3389/fpsyg.2021.767840/pdf
20Q: Hearing Loss and Listening-related Fatigue - Clinical Assessment - Article 29547 - Audiology Online, https://www.audiologyonline.com/articles/20q-hearing-loss-and-listening-29547
Psychoacoustics for the Practical Engineer: Leveraging Auditory Perception for Superior Mixes - solidskillsy., https://solidskillsy.com/2025/08/19/psychoacoustics-for-the-practical-engineer-leveraging-auditory-perception-for-superior-mixes/
Listening fatigue: how bad audio quality burns out your audience, https://www.wpfastestcache.com/blog/listening-fatigue-how-bad-audio-quality-burns-out-your-audience/
What is Listening Fatigue? - Audibel, https://www.audibel.com/hearing-loss-treatment/what-is-listening-fatigue/
Effects of Critical Distance and Reverberation on Listening Effort in Adults - ASHA Journals, https://pubs.asha.org/doi/10.1044/2022_JSLHR-22-00109
The effects of noise and reverberation on listening effort for adults with normal hearing, https://pmc.ncbi.nlm.nih.gov/articles/PMC4684471/
Listener fatigue - Wikipedia, https://en.wikipedia.org/wiki/Listener_fatigue
Is Listening Fatigue Real? | Hearing Loss San Jose, CA - HearBright, https://hearbright.com/is-listening-fatigue-real/
The Effects of Auditory Fatigue on Hearing and Listening - Knox Audiology, https://knoxhearing.com.au/audiology/the-effects-of-auditory-fatigue-on-hearing-and-listening/
Psychoacoustics in Music Production: How Perception Shapes Sound - LALAL.AI, https://www.lalal.ai/blog/psychoacoustics-in-music-production/
Psychoacoustics Part 1. An Introduction | by Myk Eff - Sound & Design, https://soundand.design/psychoacoustics-part-1-f12098134d26
Psychoacoustics Enhances Music Production by Shaping Sound Perception - Future School of Performing Arts, https://future-school.in/blogs/psychoacoustics-enriches-the-music-production/
A Mix That Doesn't Translate: The Sound Engineer's Biggest Headache and the Hidden Reasons Behind It - dSONIQ Realphones, https://www.dsoniq.com/blog/mix_doesnt_translate
Psychoacoustics: how perception influences music production - iZotope, https://www.izotope.com/community/blog/psychoacoustics-how-perception-influences-music-production
How to Avoid Ear Fatigue while Mixing | Blog - Waves Audio, https://www.waves.com/how-to-avoid-ear-fatigue-while-mixing
Mixing with Headphones: Make Mixes Translate on Speakers - Sonarworks Blog, https://www.sonarworks.com/blog/learn/mixing-headphones-speaker-translation
Weighting of Spatial and Spectro-Temporal Cues for Auditory Scene Analysis by Human Listeners | PLOS One - Research journals, https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0059815
5 Ways to Use Dynamic EQ with Sidechain - iZotope, https://www.izotope.com/community/blog/5-ways-to-use-dynamic-eq-with-sidechain
EQ Frequencies - Songstuff, https://www.songstuff.com/recording/article/eq-frequencies/
How to EQ Vocals: Essential Tips for Clarity & Presence - Avid, https://www.avid.com/resource-center/how-to-eq-vocals
SPATIAL RELEASE FROM MASKING - Acoustics Today, https://acousticstoday.org/wp-content/uploads/2019/09/SPATIAL-RELEASE-FROM-MASKING-Ruth-Y.-Litovsky.pdf
Spatial release from masking and listening effort: differences between binaural and free-field presentation - European Acoustics Association, https://dael.euracoustics.org/confs/fa2025/data/articles/000813.pdf
The Relationship Between Spatial Release From Masking and Listening Effort Among Cochlear Implant Users With Single-Sided Deafness - Binaural Hearing and Speech Lab, https://bhsl.waisman.wisc.edu/wp-content/uploads/sites/114/2025/10/the_relationship_between_spatial_release_from.8.pdf
Spatial Release from Masking with Simulated Electric–Acoustic and Cochlear Implant Speech - MDPI, https://www.mdpi.com/2504-463X/7/1/15
Normative Data for a Rapid, Automated Test of Spatial Release From Masking - PMC, https://pmc.ncbi.nlm.nih.gov/articles/PMC6436452/
Spatial Release from Masking with a Moving Target - Frontiers, https://www.frontiersin.org/journals/psychology/articles/10.3389/fpsyg.2017.02238/full
The Psychoacoustics of Headphone Listening. - HeadWize Memorial - WordPress.com, https://headwizememorial.wordpress.com/2018/03/15/the-psychoacoustics-of-headphone-listening/
5 Best Psychoacoustic Tricks to Make Your Headphones Sound More Expensive for Free, https://www.headphonesty.com/2025/07/best-psychoacoustic-tricks-headphones/
How to Mix Your Music Using Psychoacoustics - Sage Audio, https://www.sageaudio.com/articles/how-to-mix-your-music-using-psychoacoustics
(PDF) Nearfield Crosstalk Increases Listener Preferences for Headphone-Reproduced Stereophonic Imagery - ResearchGate, https://www.researchgate.net/publication/277562537_Nearfield_Crosstalk_Increases_Listener_Preferences_for_Headphone-Reproduced_Stereophonic_Imagery
Cognitive load associated with speaking clearly in reverberant rooms - PMC, https://pmc.ncbi.nlm.nih.gov/articles/PMC11362551/
Effects of reverberation on speech intelligibility in noise for hearing-impaired listeners - Wikimedia Commons, https://upload.wikimedia.org/wikipedia/commons/c/c0/Effects_of_reverberation_on_speech_intelligibility_in_noise_for_hearing-impaired_listeners.pdf
(PDF) Cognitive load associated with speaking clearly in reverberant rooms - ResearchGate, https://www.researchgate.net/publication/383530503_Cognitive_load_associated_with_speaking_clearly_in_reverberant_rooms
So why does reverberation affect speech intelligibility? - MC Squared System Design Group, https://www.mcsquared.com/classic/y-reverb.htm
How to Use a De-Esser in Audacity to Fix Harsh Sibilance (Step-by-Step) - Hollyland, https://www.hollyland.com/blog/topics/use-a-de-esser-in-audacity
De-essing - Wikipedia, https://en.wikipedia.org/wiki/De-essing
Intelligibility and Clarity of Reverberant Speech: Effects of Wide Dynamic Range Compression Release Time and Working Memory - PMC, https://pmc.ncbi.nlm.nih.gov/articles/PMC5399768/
Listening effort and speech intelligibility in listening situations affected by noise and reverberation | Request PDF - ResearchGate, https://www.researchgate.net/publication/267982774_Listening_effort_and_speech_intelligibility_in_listening_situations_affected_by_noise_and_reverberation
Cognitive load associated with speaking clearly in reverberant rooms - PubMed, https://pubmed.ncbi.nlm.nih.gov/39209957/
The impact of speech type on listening effort and intelligibility for native and non-native listeners - Frontiers, https://www.frontiersin.org/journals/neuroscience/articles/10.3389/fnins.2023.1235911/full
Why Do We Even Need to De-ess? - Sonible, https://www.sonible.com/blog/why-de-essing/
How to De-Ess Vocals without Dulling the Mix | Blog - Waves Audio, https://www.waves.com/how-to-de-ess-vocals
Vocal EQ Cheat Sheet for Every Mix - Orphiq, https://orphiq.com/resources/vocal-eq-cheat-sheet
Mix Like a Pro: The Art of Subtractive EQ - Drake Stafford, https://www.drakestafford.com/post/mix-like-a-pro-the-art-of-subtractive-eq
Subtractive EQ vs Additive EQ: The Secret to Clean Mixes - Making A Scene!, https://www.makingascene.org/subtractive-eq-vs-additive-eq-the-secret-to-clean-mixes/
How to EQ Vocals - Sage Audio, https://www.sageaudio.com/articles/how-to-eq-vocals
What is de-essing? The dos and don'ts of using a de-esser - iZotope, https://www.izotope.com/community/blog/the-dos-and-donts-of-de-essing
De-essing Vocals: Control Sibilance in a Clean Mix - ACE Studio, https://acestudio.ai/blog/de-essing-in-audio-production/
Sound Quality Saturday: What Is Side-Chain Compression (Ducking) & How Do You Use It? : r/podcasting - Reddit, https://www.reddit.com/r/podcasting/comments/ntacv6/sound_quality_saturday_what_is_sidechain/
Sidechain Compression Vs Sidechain EQ - Which is Better - Music Guy Mixing, https://www.musicguymixing.com/sidechain-compression-vs-sidechain-eq/
Difference between sidechaining with EQ vs Compressor? - Logic Pro Help, https://www.logicprohelp.com/forums/topic/152514-difference-between-sidechaining-with-eq-vs-compressor/
Sidechain Better with dynamic EQ sidechaining - Admiral Bumblebee, https://www.admiralbumblebee.com/music/2018/08/09/sidechain-better-with-dynamic-eq-sidechaining
Loudness Basics - AES - Audio Engineering Society, https://aes.org/resources/audio-topics/loudness-project/loudness-basics/
Fix Common Problems in Audio Streaming - Radio World, https://www.radioworld.com/tech-and-gear/tech-tips/fix-common-problems-in-audio-streaming
AESTD1008: Recommendations for Loudness of Internet Audio Streaming and On-Demand Distribution - AES, https://aes.org/community/technical-council/technical-document-aestd1008/
Streaming Audio Loudness Guidelines Explained - Radio World, https://www.radioworld.com/tech-and-gear/tech-tips/streaming-audio-loudness-guidelines-explained
Recommendations for Loudness of Internet Audio Streaming and On-Demand File Playback, https://www.aesmelbourne.org.au/wp-content/uploads/2022/12/Melbourne-AES-loudness-presentation-final.pdf
Streaming Loudness - AES Recommendations 2021, and why you should care, https://productionadvice.co.uk/td1008/
Meeting Report: December 2022 – John Kean on Loudness for Streaming Audio, https://aesmelbourne.org.au/mtg-rpt-dec2022/
Spotify States -14 LUFS and -1.0 dB True Peak for Mastering - Is anyone really doing this though? : r/edmproduction - Reddit, https://www.reddit.com/r/edmproduction/comments/klr4ax/spotify_states_14_lufs_and_10_db_true_peak_for/











