
The Physics of Acoustic Capture and Pre-Processing Preparation
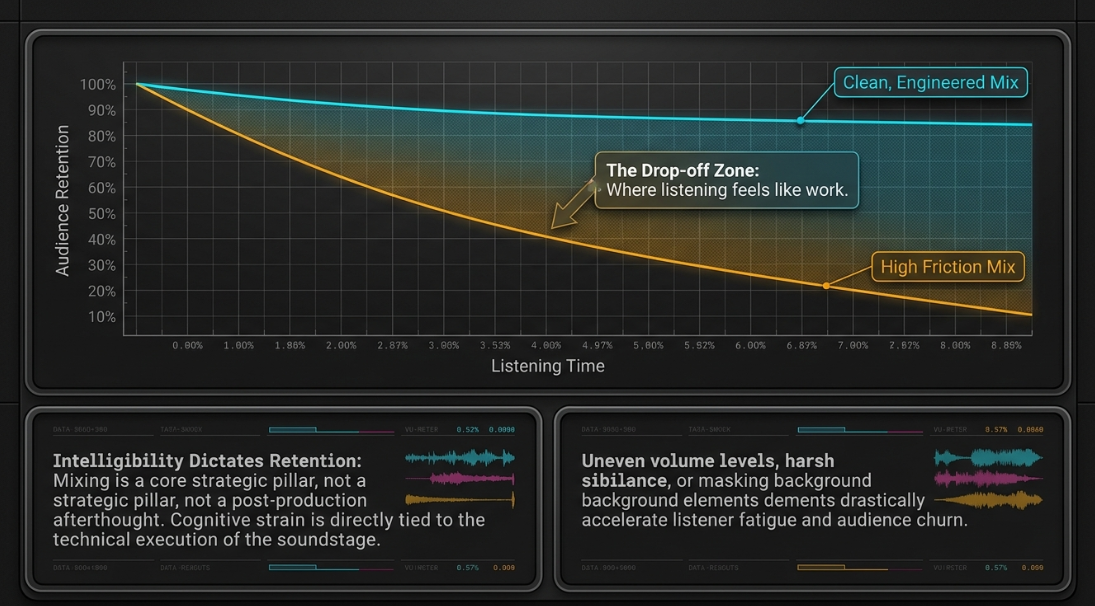
Professional podcast mixing is a core strategic pillar for brand identification and listener retention, rather than a cosmetic polish applied at the end of a production cycle1. The cognitive strain experienced by a listener is directly tied to the technical execution of the mix; if listening feels like work due to uneven volume levels, harsh sibilance, or competing background elements, audience retention rates inevitably decline1. Consequently, clean upstream capture acts as a critical prerequisite for downstream success1.
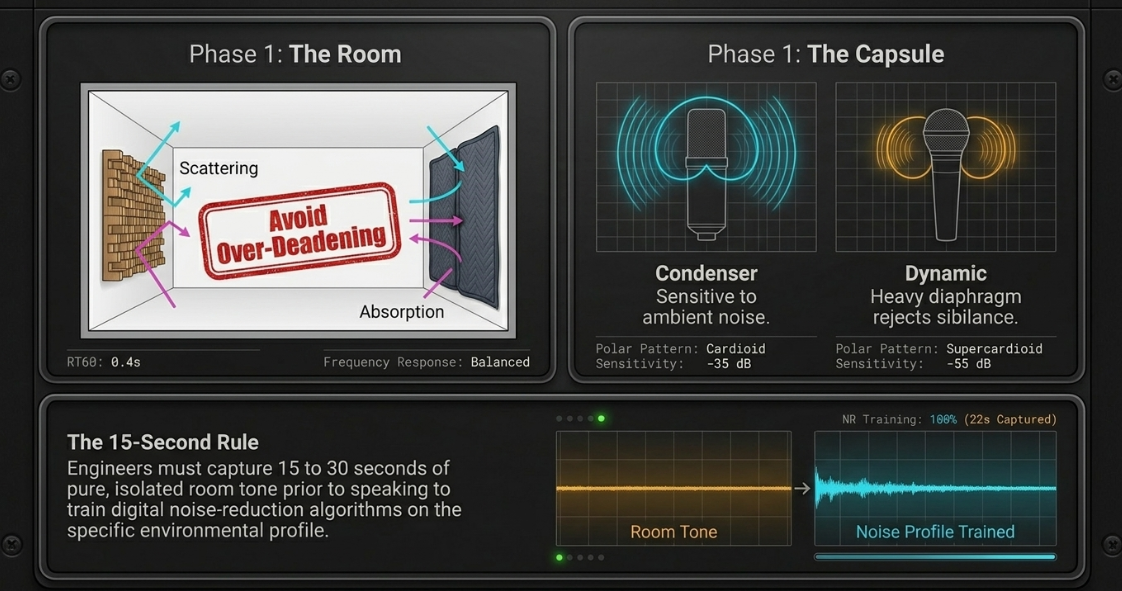
To establish a solid foundation, the acoustical environment of the recording space must be managed. Modern residential structures, characterized by parallel drywall surfaces, reflect sound wave energy, resulting in bright, flutter-echo reverb tails that degrade the intelligibility of the recording2. While commercial studios invest heavily in tailored acoustics, independent or remote productions can achieve substantial improvements through strategic, budget-conscious absorption2. Thick moving blankets placed across highly reflective parallel walls can reduce room reflections significantly, whereas specialized acoustic foam absorbs high-frequency reflections, and wood diffusers scatter sound waves to preserve a natural, non-reverberant room feel2. Over-treating a space can lead to a completely "dead" room, which sounds unnatural and fatiguing over long listening durations2.
The selection and deployment of capture hardware are equally critical4. Large-diaphragm capacitor (condenser) microphones provide extensive high-frequency detail and "air," but their highly sensitive diaphragms and low noise floors require a quiet environment to avoid capturing unwanted ambient noise4. Alternatively, dynamic microphones such as the Shure SM7B and Electro-Voice RE-20 are widely utilized in broadcast and podcasting due to their heavier diaphragms, which reduce lip noise and sibilance, while providing a rounded, classic radio tone4. When dynamic microphones are placed further from the talker, inline signal boosters (such as the Triton Audio FetHead or Cloudlifter) can provide clean, transparent gain prior to the audio interface’s preamplifier, preventing the introduction of electronic self-noise4. Position-wise, miking slightly above mouth height and angling downward reduces sibilance, which is typically worst along a horizontal plane at lip height4.
A critical component of the pre-processing stage is calibrating noise reduction algorithms4. The character of ambient noise in any given space varies continuously throughout the day based on external traffic patterns, HVAC cycles, and atmospheric conditions4. Professional engineers prioritize capturing some of the ambient background noise in isolation—ideally for fifteen to thirty seconds prior to the start of speech—so that the noise-reduction algorithm can be trained on a pure, uncorrupted noise profile representing the specific time of recording4.
Before initiating any processing, professional workflows demand rigorous session organization1. Audio engineers split hosts, guests, music beds, advertisements, pickups, and sound effects into dedicated, clearly labeled tracks1. Prior to applying dynamic processors or equalizers, a stable "static mix" must be established, where basic volume levels and stereo balances are set to reveal any fundamental frequency clashes, ensuring that dialogue remains the prominent, central anchor of the program6. Furthermore, mixing decisions should be made at low-to-moderate monitoring levels8. This approach mimics stepping back from a large canvas, allowing the engineer to evaluate the mix as a cohesive whole, accurately gauge the volume relationship between spoken voice and background music, and protect long-term auditory health8.

Dialogue Restoration, Spectral Repairs, and Vocal Channel Signal Flow
Dialogue processing in professional podcasting is designed to prioritize vocal intelligibility and natural dynamics while minimizing distracting sonic artifacts3. Modern post-production operations often contend with messy multitrack captures, field recordings, or uncompressed, overlapping speakers on single-track files11. In these scenarios, advanced stem-separation technologies (such as AudioShake's dialogue isolation algorithms) are deployed to split mixed voice files into clean, independent dialogue stems11. When field recordings capture unpredictable transient noises (such as an ambulance siren), these tools allow the mixing engineer to isolate the voice and manually attenuate the background stem11. This adjustment ensures that the ambient context is preserved and understood without drowning out the spoken content or compromising transcription accuracy11.
Once the raw tracks are prepared, they are routed through a structured vocal channel signal strip9. A highly standard corrective signal chain begins with subtractive equalisation, followed by sibilance control, gentle dynamic compression, and finally, additive tonal shaping9.
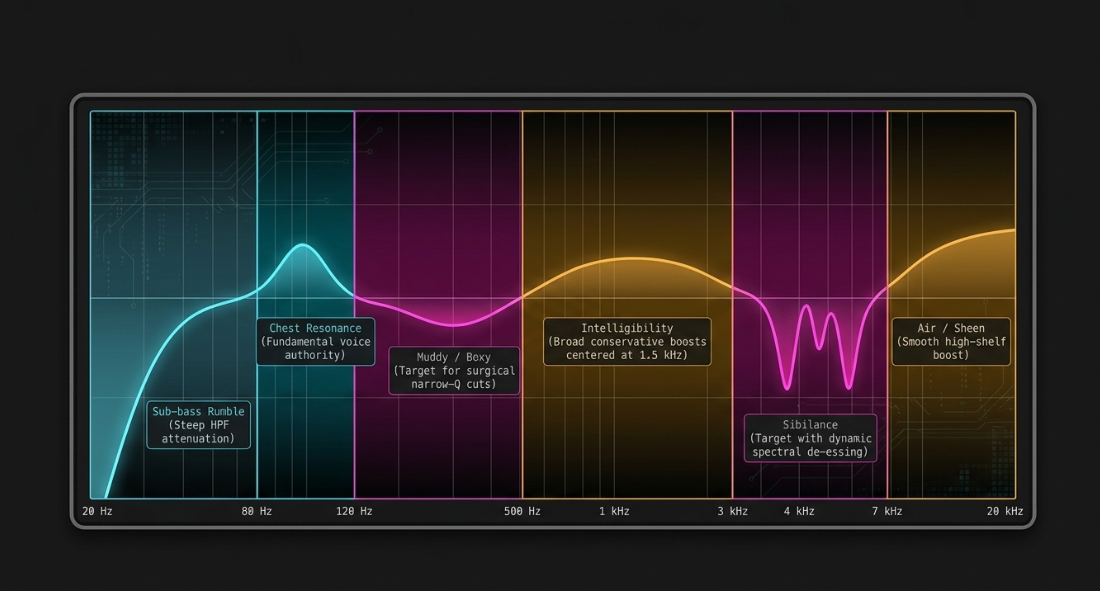
The high-pass filter (HPF) is first deployed to roll off frequencies below 80 Hz to 120 Hz10. This range contains low-frequency mechanical rumble, traffic noise, and plosive thumps, which carry no useful vocal information and can cause downstream compressors to react unpredictably9. The basic transfer function of a first-order high-pass filter can be modeled mathematically as:
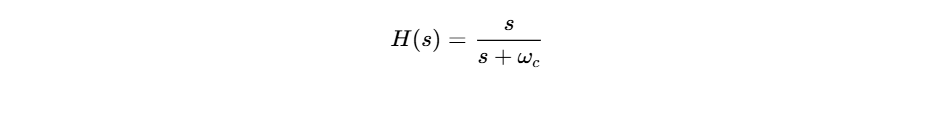
where 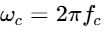
Once the low-end rumble is managed, engineers target boxy or muddy resonances, which typically build up between 120 Hz and 500 Hz due to room acoustics or the proximity effect15. This correction is often performed using the "sweep" technique: a narrow parametric band is boosted significantly and swept through the low-mid frequency range until the muddy or resonant frequencies are identified, at which point the band is cut by 1 to 5 dB using a highly surgical Q-factor to preserve vocal warmth15. Professional podcasters focus on cutting offending frequencies rather than boosting desirable ones; boosting frequencies often raises the ambient noise floor and highlights room reflections, whereas subtractive EQ reveals the natural clarity of the voice16.
When mixing multiple speakers, particularly those with similar tonal registers, subtle complementary EQ adjustments are applied1. The mixing engineer separates their tonal centers slightly (for example, by carving a broad, gentle dip at 1.5 kHz on one track while boosting the same region slightly on the other) to enhance spatial separation and ensure both voices read clearly in a combined mix1.
Sibilance control is addressed next in the signal path9. Harsh consonant sounds typically reside between 4 kHz and 7 kHz14. While manual level attenuation of sibilant clips yields the most transparent results, it is highly labor-intensive14. Digital de-essers resolve this efficiently14. Standard broadband de-essers apply gain reduction across the entire signal when a sibilant frequency is detected, which can lead to unnatural lisping artifacts19. In contrast, spectral de-essers operate symmetrically with dynamic EQs, reducing energy only within the specific high-frequency band where the sibilant energy exceeds the threshold, thereby maintaining the natural high-frequency sheen of the voice14.
Vocal dynamics are then balanced using moderate, transparent compression1. Professional podcast mixing avoids heavy-handed, single-stage compression, which limits transient life and accelerates listener fatigue1. Instead, engineers apply mild compression with low ratios (e.g., 1.5:1 to 3:1), a moderately fast attack time (~20 ms) to capture initial transients, and a slow-to-medium release time (~200 ms) to prevent audible "pumping"9. To manage highly dynamic speakers, a dual-stage compressor or a dynamic EQ is often preferred9. A dynamic EQ or a multiband compressor can target and compress just the low-frequency boominess below 200 Hz when a speaker gets loud or leans in too close to the microphone, leaving the mid and high frequencies uncompressed to preserve a natural, open vocal character9.
Furthermore, advanced leveling systems incorporate automated parameters such as Tail Guarding (e.g., APU Loudness Leveler/Compressor)21. This mechanism prevents the gain structure of the leveler from automatically ramping up during the quiet pauses at the end of spoken phrases, which would otherwise amplify unwanted mouth clicks, physiological breaths, or baseline room hum12.
For high-end or cinematic productions, engineers often utilize hybrid processing suites12. This workflow may combine surgical digital tools with hardware-modeled emulation12. For example, running the primary vocals through virtual modeling of classic 1176 fast-limiting and LA-2A optical leveling chains adds harmonic depth and saturation, smoothing out vocal contours12. Specialized spectral processors (such as Gullfoss or Soothe 2) are then positioned near the end of the channel insert slots to dynamically adapt the frequency spectrum in real time, taming resonance build-ups and high-frequency harshness12.
Dialogue alignment and editing must be completed prior to the application of final level automation10. A common challenge occurs when speakers construct run-on sentences or transition abruptly into tangential thoughts, leaving behind unnatural, jarring edit boundaries in the script23. The dialogue editor uses pitch contouring tools (such as iZotope RX Dialogue Contour) to select the final syllable of an edit and subtly draw its pitch down, simulating a natural, complete full-stop cadence23. This pitch adjustment, paired with a faded bed of captured room tone positioned beneath the edit, creates a seamless narrative transition23.
Once these spectral and edit fixes are established, final level automation is written across the timeline10. This process is performed dynamically, starting with the primary host track as an anchor level targeting -24 LUFS, and manually riding the fader to ensure that conversational emphasis and macro-level dynamics are preserved10.
Advanced Multitrack Waveform Synchronization and Gain-Sharing Automixing
When multiple hosts and guests are recorded in the same physical space, microphone bleed—where one speaker's voice is captured by a neighboring microphone—presents a significant challenge24. This bleed creates a secondary, delayed version of the signal25. When these signals are summed together in a multitrack mix, the time delay 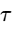
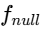
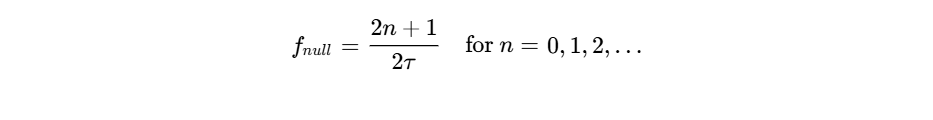
This delay is directly proportional to the physical distance between the sound source and the bleeding microphone25.
To resolve these phase discrepancies, modern post-production workflows utilize advanced time and phase alignment plug-ins, such as Sound Radix Auto-Align 2 and Auto-Align Post 222. These processors utilize ARA 2 (Audio Random Access) integration to analyze raw multitrack files across the timeline prior to editing22. The algorithm identifies shared acoustic information and automatically shifts individual tracks forward or backward in time—using sample-accurate time offsets—to align matching waveforms22.
Beyond basic static time offsets, these tools employ Spectral Phase Optimization22. This process detects frequency-dependent phase shifts caused by electronic circuitry, microphone preamplifier high-pass filters, or complex acoustic reflections, and applies precise, all-pass filters to rotate the phase of specific frequency bands, restoring transient punch and mid-range intelligibility22. For these alignment tools to calculate optimal correlation, the sidechain detector threshold must be set above the noise floor of the bleed, preventing irrelevant acoustic noise from misaligning the primary signals26.
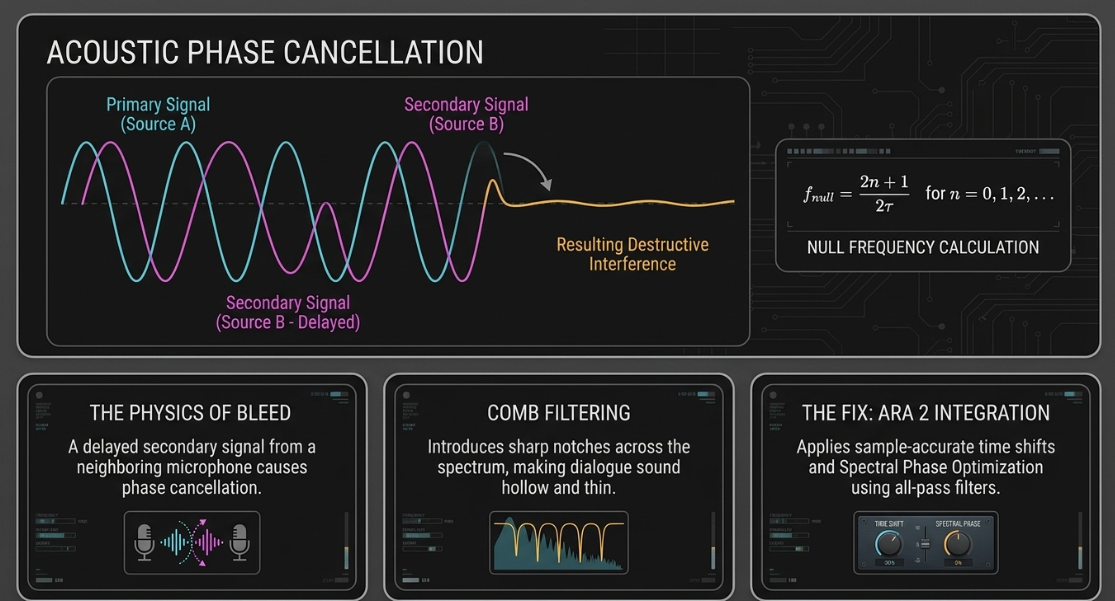
While phase alignment addresses acoustic cancellations, managing the continuous ambient noise floor of multiple open microphones requires specialized dynamic control25. Standard noise gates are often unsuitable for speech; their strict binary open/close behavior can cut off subtle sentence endings and produce abrupt changes in the room tone, known as "gate chatter"9. To resolve this, gain-sharing automixers (based on the Dan Dugan algorithm) are widely used in professional multi-mic setups24.

A gain-sharing automixer dynamically adjusts the attenuation of each individual channel in real time, ensuring that the total system gain remains constant and equal to the gain of a single open microphone (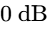
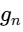
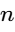
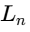
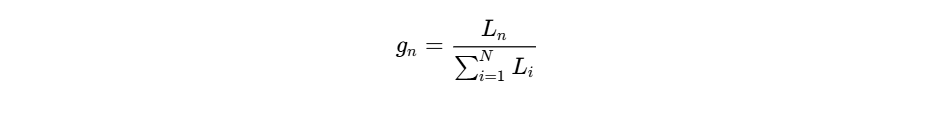
Under this model, the total system gain is conserved:
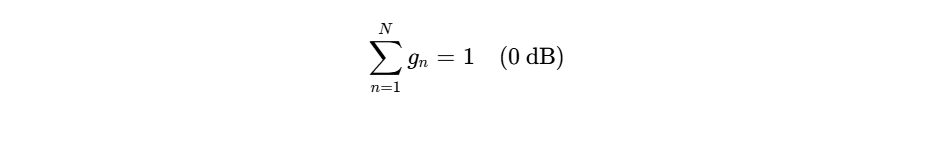
When one host is actively speaking, their channel’s signal level dominates the denominator, causing the automixer to route full gain to that microphone while attenuating all other inactive channels31. If multiple hosts speak simultaneously, the available gain is distributed proportionally among them31. When all participants are silent, the gain is distributed equally across all microphones, which prevents the acoustic "pumping" of background room noise that occurs with standard gates or high-ratio expanders32.
To optimize this process in noisy environments, professional automixers (such as BSS Soundweb or Waves Dugan) incorporate dedicated voice-band filters within the sidechain detection circuit24. These band-pass filters restrict the detector’s sensitivity to the human vocal range (approximately 300 Hz to 3 kHz), ensuring that low-frequency air-conditioning hum or high-frequency keyboard clatter does not trigger the automixer, allowing the speaking host’s voice to remain focused and clear33.
Sound Design Integration, Music Architecture, and Advanced Ducking Topologies
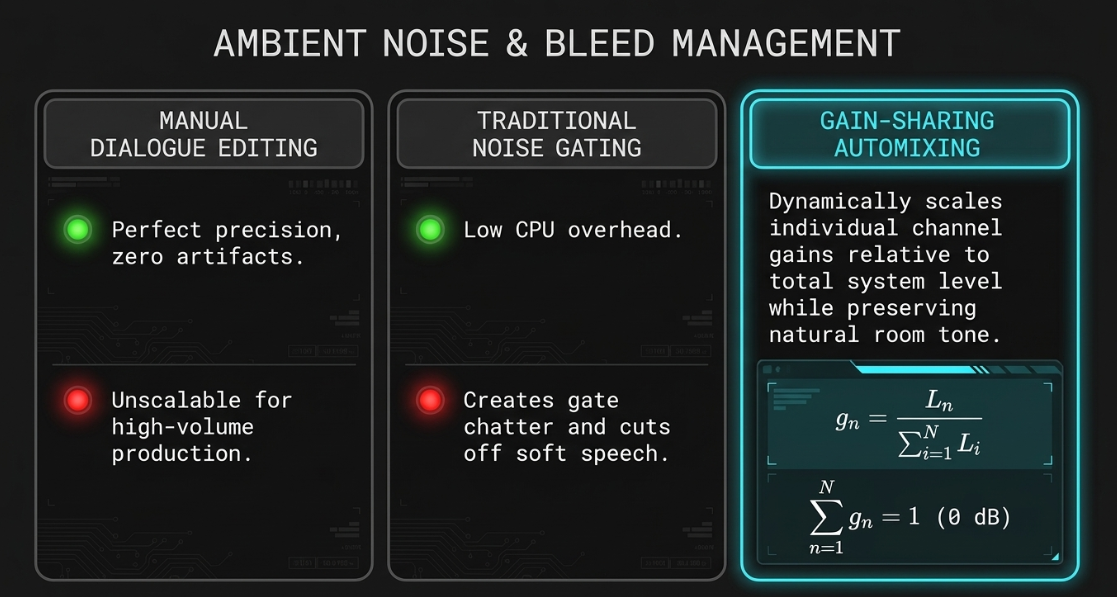
Sound design and music beds are essential for establishing a podcast's narrative pace, structuring segments, and providing cognitive relief between dense sections of spoken dialogue4. The primary challenge when mixing these elements is preventing background music or sound effects from masking the dialogue, which is the primary source of information in the program1.
To build a professional soundstage, the music is arranged as a structural framework:
Intro Theme: An opening sequence that establishes the show's aesthetic, concluding with a sparse rhythm-section "bed" designed to fade smoothly beneath the host's introduction4.
Stings: Short, five-second musical transitions positioned between thematic blocks (e.g., between an interview segment and ad rolls) to punctuate the timeline4.
Outro Theme: A closing sequence starting with a slow fade-in beneath the host's sign-off, building to a definitive, uncompressed ending to round out the program4.
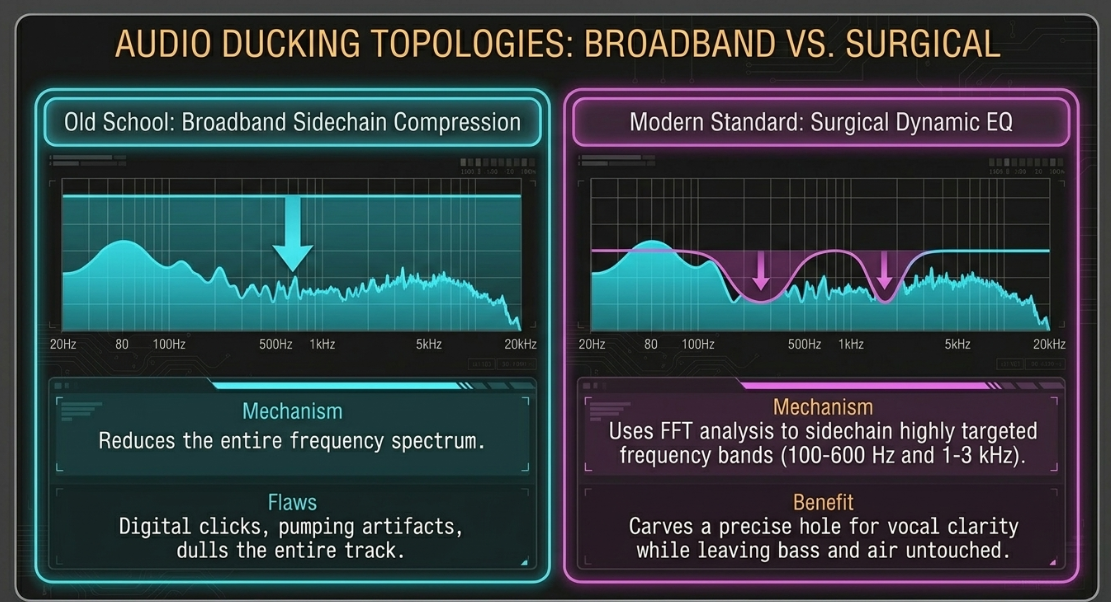
To maintain vocal prominence over these beds, mixers use ducking techniques to automatically lower the music volume when dialogue is present34. The traditional method uses broadband sidechain compression, where a compressor is inserted on the music channel and its control circuit is triggered by a pre-fader auxiliary send from the dialogue bus34.
When a host speaks, the signal triggers the compressor, reducing the music's volume across the entire frequency spectrum34. The linear gain multiplier 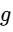
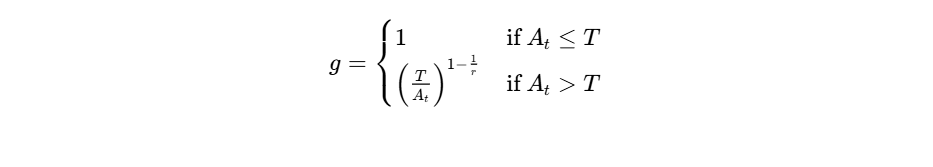
where 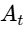
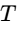
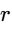
The envelope of the trigger signal is estimated using a first-order recursive filter:
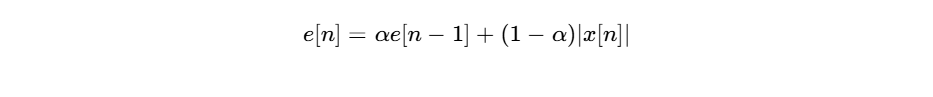
where 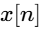
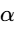
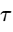
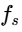
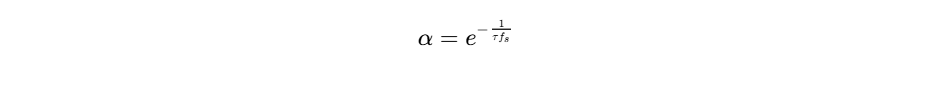
Typically, attack times range from 1 to 10 ms to catch vocal transients quickly, while release times sit between 50 and 200 ms to restore the music bed level naturally after speech pauses34.
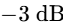
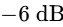
While broadband sidechain compression is highly effective for heavy electronic pumping effects, it can sound unnatural in speech-focused productions34. If the attack time is set too fast, the rapid drop in music volume can create digital clicks; if the release time is too fast, the music volume will "chatter" or pump distractingly between words34. Conversely, if the release time is too slow, the music will remain too quiet for too long after the speaker finishes, disrupting the pacing of the segment36.
To avoid these artifacts, professional workflows favor sidechain dynamic EQ or spectral ducking38. Rather than attenuating the entire frequency spectrum of the music, a dynamic EQ (such as FabFilter Pro-Q 3) targets only the specific frequency bands that directly conflict with vocal clarity38.
Vocal energy is concentrated in distinct spectral regions: the fundamental chest tones live between 100 Hz and 600 Hz, while the presence and intelligibility frequencies live between 1 kHz and 3 kHz14. By routing the dialogue track to the dynamic EQ’s external sidechain, the music’s low-mid and high-mid frequencies are targeted and attenuated only when dialogue is active38. This approach acts as a scalpel: the high-frequency air and low-frequency bass of the music remain untouched, maintaining the perceived energy of the music bed while carving out a clean spectral space for the voice38.
For even greater precision, advanced spectral ducking tools (such as Trackspacer or Soothe 2 in sidechain mode) are employed12. These processors utilize real-time Fourier transform (FFT) analysis to continuously measure the spectral footprint of the incoming dialogue41. They then apply an inverse filter with dozens of highly targeted dynamic bands across the music channel, attenuating only the exact frequencies active in the speaker's voice on a millisecond-by-millisecond basis41. This approach ensures vocal clarity with minimal gain reduction, making the ducking process virtually transparent to the listener38.
Spatial Localization, Mid-Side Stereo Alignment, and Object-Based Immersive Production
Spatial localization in a professional mix expands the stereo image to create a clear, natural soundstage, preventing frequency masking between multiple sound sources43. In multi-host podcasts, subtle panning is used to simulate a natural physical soundstage, allowing the listener's brain to distinguish between different speakers9. When panning, audio engineers must distinguish between stereo balance and true stereo panning43. A standard stereo balance control simply adjusts the relative volume of the left and right channels; panning a stereo track to the left with a balance control merely attenuates the right channel, which can discard unique spatial information and make the mix feel lopsided43. True stereo panning or dual-mono panning, by contrast, physically repositions both channels within the stereo field, preserving the width and acoustic integrity of the source43.
To ensure a balanced stereo image, low frequencies (such as the fundamental frequencies of a bass instrument or a deep male voice) should remain centered43. Low frequencies are non-directional to human ears, and panning them can weaken the impact of the mix and cause imbalances on systems with dedicated subwoofers45. Conversely, high frequencies (such as stings, sound effect transients, or acoustic guitar accompaniments) can be panned wider to create a spacious stereo field43.
Mid-Side (M/S) processing is highly effective for managing spatial width43:
Mid Channel: Contains the sum of the left and right channels (
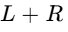
Side Channel: Contains the difference between the left and right channels (
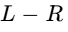
To ensure that the spatial mix translates accurately across all systems, engineers must monitor mono compatibility43. Because many consumers listen via single-speaker smart assistants, mobile phones, or mono-summed public address systems, a mix that relies on extreme phase offsets to create width can collapse or experience severe phase cancellation in mono43. Engineers use correlation meters to evaluate phase relationships; a reading of 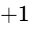
The adoption of Dolby Atmos has introduced object-based spatial audio workflows to modern podcasting49. Unlike traditional channel-based surround sound formats (such as 5.1 or 7.1), which assign audio elements to fixed speakers, Dolby Atmos uses a metadata-driven architecture containing up to 128 channels51. This system organizes audio assets into Beds and Objects51:
Beds: Channel-based submixes (e.g., 7.1.4, which includes height channels) that provide a stable, speaker-mapped foundation51. Beds are typically used for music beds, background environmental ambiances, and main drum groups50.
Objects: Independent audio streams with accompanying spatial metadata (x, y, z coordinates)51. Spoken dialogue, transitional sound effects, and specific musical leads are treated as Objects, allowing the playback system to render their positions accurately relative to the listener50.
Because more than 80% of immersive spatial audio is consumed on headphones, spatial mixers rely heavily on Binaural Rendering and Head-Related Transfer Functions (HRTFs)49. HRTFs use physical modeling and mathematical filters to simulate how sound waves interact with the human head, shoulders, and pinnae, creating cues like Interaural Time Differences (ITD) and Interaural Level Differences (ILD) to position sound sources in a 3D space49. The Dolby Atmos Renderer allows engineers to assign specific binaural distance models (Off, Near, Mid, Far) to individual objects49.
For example, a host's voice is set to "Near" to maintain presence and focus, while a sweeping transition effect is set to "Far" with automated movement along the z-axis (height) to create an immersive, vertical lift without masking the primary dialogue49. While panning objects can add creative movement, excessive motion can be distracting51. The primary objective remains supporting the narrative structure of the show51.
Master Bus Processing Architectures and Loudness Compliance Standards
The master bus serves as the final summing point for all audio tracks, stems, and processing chains within a Digital Audio Workstation (DAW)20. Rather than applying master bus processing at the very end of a mix, professional engineers prefer to mix directly into an active master chain from the start20. This approach ensures that track-level EQ and compression decisions are made in the context of the collective mix bus behavior20.
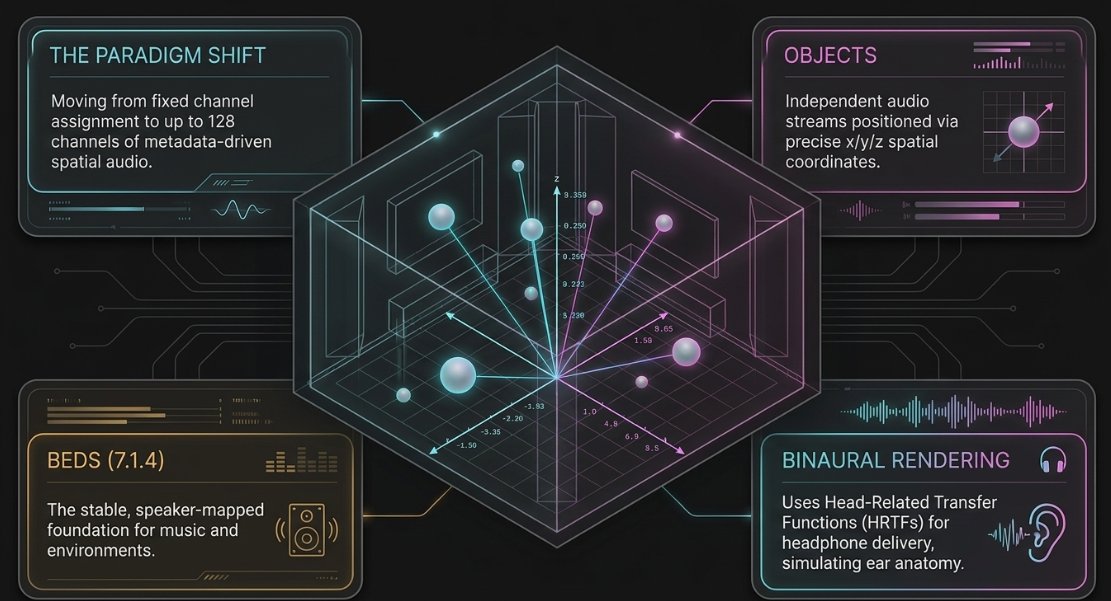
A professional master bus signal chain for podcasting is designed to add cohesion and control peak levels using highly subtle processing20. The first processor is a surgical equalizer used to clean up the overall mix20. A high-pass filter is set with a steep slope at 25 Hz to 30 Hz to remove sub-bass frequencies, protecting headroom and preventing downstream compressors from over-reacting20.
A dynamic VCA-style glue compressor (such as the SSL G-Master Buss Compressor) is placed next to tie the individual tracks together20. The settings are configured to be highly conservative: a slow attack time (typically 30 ms) allows transient details to pass uncompressed, while an auto-release setting ensures a natural, musical recovery20. A low compression ratio (1.5:1 or 2:1) is paired with a high threshold to achieve just 1 to 2 dB of gain reduction on the loudest program peaks20.
During multi-microphone dialogue, a primary mastering challenge is managing the buildup of high-mid frequencies (1 kHz to 5 kHz) when multiple hosts speak or laugh simultaneously9. While the individual tracks may be balanced, their sum can sound harsh and pierce the listener's ears9. To resolve this, a master bus multiband compressor or dynamic EQ is set with a high threshold and a fast release9. This processor engages only when the high-mid energy exceeds the threshold during simultaneous speech, taming the harsh accumulation without dulling the individual tracks when hosts speak independently9.
Subtle harmonic saturation is then applied to mimic the natural compression and warmth of vintage analog tape20. Processors such as Soundtoys Decapitator are set to a low wet/dry blend (often 10% or less)55. This process adds gentle odd and even harmonics, warming the mid-range and smoothing harsh high frequencies to help the mix translate better on consumer playback systems55.
The final processor in the chain is a brick-wall limiter to prevent digital clipping20. The output ceiling is set strictly between -1.0 dBTP and -2.0 dBTP to avoid intersample peak clipping during digital-to-analog conversion on consumer playback devices5. The threshold is adjusted until the overall mix achieves the target integrated loudness, ensuring that the limiter engages only on the absolute highest peaks20.
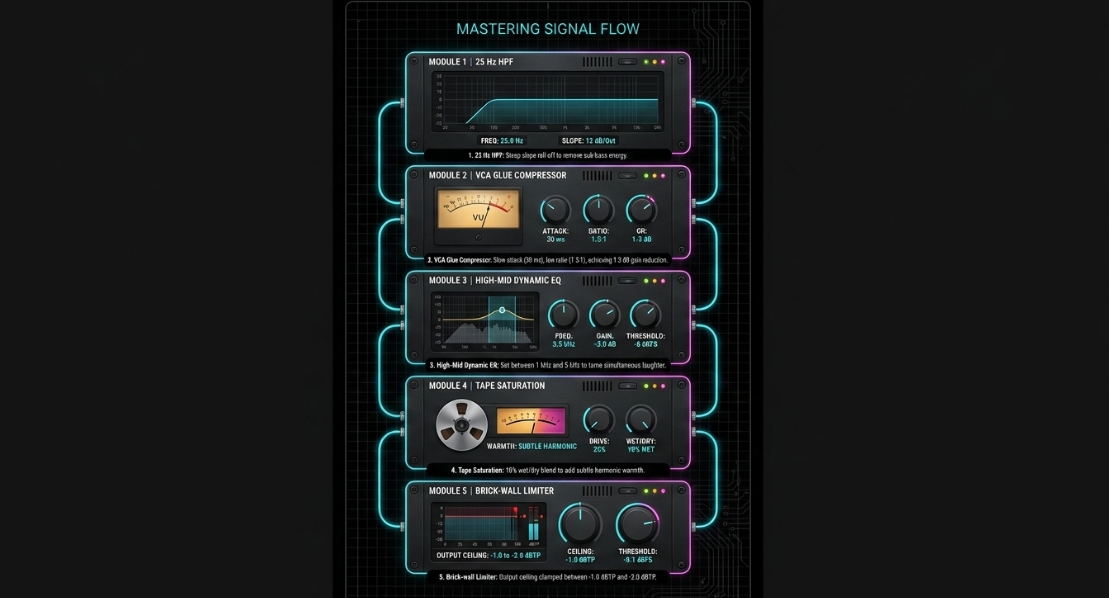
To resolve the inconsistencies of peak-normalization and end the "loudness wars," the global broadcast and streaming industries have transitioned to loudness normalization protocols based on the ITU-R BS.1770 standard57. This standard uses K-weighting filters, which mimic the human ear’s acoustic sensitivity by applying a low-frequency roll-off (to discount non-directional bass energy) and a high-mid presence boost (to emphasize frequencies critical to human speech)60.
Loudness is measured in LUFS (Loudness Units relative to Full Scale) or LKFS (Loudness, K-weighted, relative to Full Scale), which are mathematically equivalent60. Loudness meters evaluate three distinct time-scales:
Momentary Loudness (
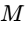
Short-term Loudness (
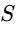
Integrated Loudness (
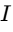
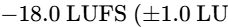
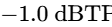
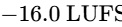
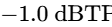
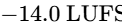
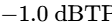
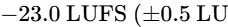
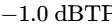

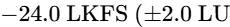
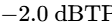
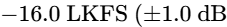
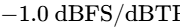
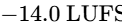
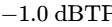
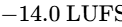
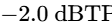
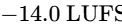
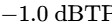
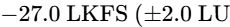
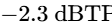
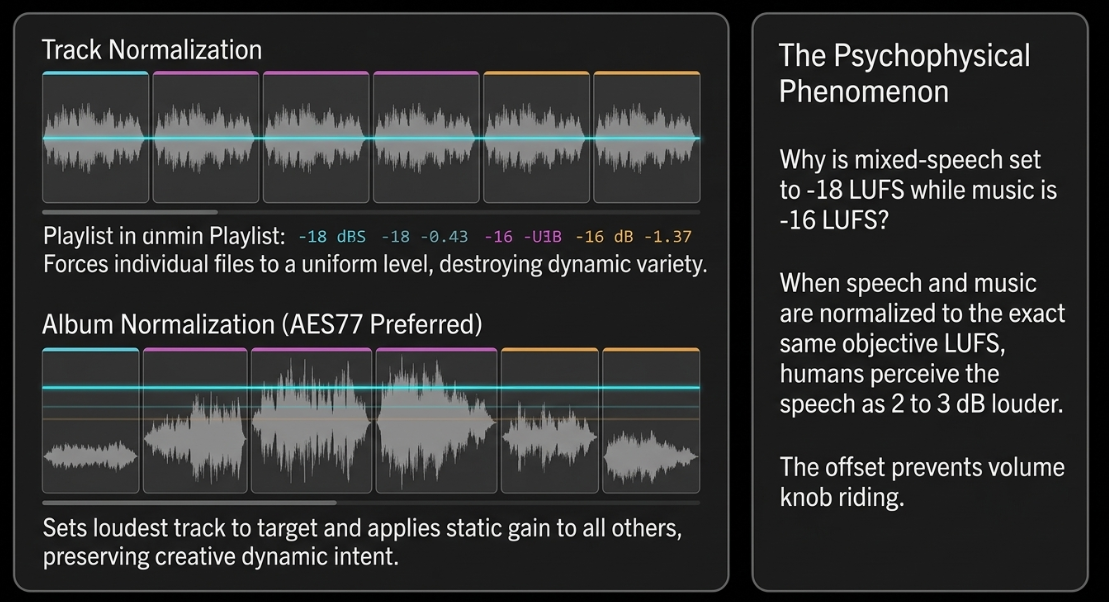
The development of AES77-2023 (AES Recommended Practice Loudness Guidelines for Internet Audio Streaming and On-Demand Distribution), based on the technical document AES TD1008, provides clear instructions for streaming distributors and content producers69. Mixed content containing speech elements combined with music or sound effects (classified as "Assorted Content") must be normalized to an integrated loudness of -18 LUFS64. By contrast, music streams are normalized to a higher target of -16 LUFS64.
This 2 dB target difference accounts for a well-documented psychophysical phenomenon: formal listening tests show that when speech and music are normalized to the exact same objective integrated LUFS level, human listeners perceive the speech as 2 to 3 dB louder than the music64. Normalizing mixed-format speech to -18 LUFS aligns it with music at -16 LUFS, preventing listeners from having to adjust their volume controls during playback64.

For music normalization within podcasts or streams, AES77-2023 strongly prefers Album Normalization over Track Normalization64. Album normalization first measures the integrated loudness of every track on an album and sets the loudest track to -14 LUFS64. The same gain adjustment is then applied to the remaining tracks on the album64. This workflow preserves the intended relative dynamic differences between tracks, maintaining the artist's creative intent64. Track normalization, by contrast, forces every track to a uniform -16 LUFS, flattening dynamic variety64.
Additionally, short-form content (such as commercial advertisements and promotional segments under three minutes) must be normalized to -18 LUFS67. This target prevents the "blasting" effect common in peak-normalized broadcasts, where ads are highly compressed to maximize their perceived loudness67.
On television and radio networks, the EBU R128 s4 (Supplement 4) update enforces strict guidelines to protect dialogue intelligibility71. In dramatic or cinematic content, music and sound effects are often mixed much louder than dialogue, with the dialogue mixed 10 to 15 LU below the overall program loudness71.
To prevent listener annoyance, EBU R128 s4 mandates that the "loudness-to-dialogue ratio" be restricted to no greater than 5 LU71. Furthermore, the average dialogue level should fluctuate within a range of +/- 7 LU relative to the average integrated target of -23 LUFS80. This standard maintains a comfortable dynamic range while ensuring that speech remains clear and intelligible across all playback devices71.
Systemic Conclusions and Actionable Post-Production Recommendations
To deliver highly competitive, broadcast-ready audio that maintains listener engagement, professional post-production workflows must adopt a structured and systematic approach:
Phase 1: Upstream Calibration and Capture Control
Mitigate physical acoustic anomalies by applying broadband absorption and wood diffusers to manage room reflections and flutter echoes2.
Use dynamic microphones with heavy diaphragms to reduce physiological clicks and sibilance, and pair them with inline signal boosters to ensure a high signal-to-noise ratio at the preamplifier stage4.
Capture isolated background noise at the time of recording to train noise-reduction algorithms on a clean, uncorrupted noise profile4.
Phase 2: Structural Session Preparation and Static Level Alignment
Organize session tracks clearly by separating hosts, guests, music beds, and sound effects into dedicated, color-coded channels1.
Build a solid static mix with basic volume balances and panning before applying dynamic insert plugins6.
Monitor at conservative volume levels to evaluate the overall cohesiveness of the mix and protect long-term auditory health8.
Phase 3: Waveform Synchronization and Multitrack Management
Use ARA 2-integrated phase alignment tools (such as Auto-Align 2) early in the workflow to apply sample-accurate time shifts and phase rotations across all microphones22. This step addresses acoustic delay and prevents comb filtering22.
Deploy gain-sharing automixers (such as Dugan or WTautomixer) across multi-mic panels24. This workflow manages bleed and ambient noise by dynamically scaling channel gains while maintaining a constant system gain, avoiding the artificial noise fluctuations of standard gates25.
Phase 4: Surgical Dialogue Restoration and Channel Strip Processing
Clean the low end of vocal channels using a steep high-pass filter set between 80 Hz and 120 Hz10. Use the sweep technique to locate and cut boxy mid-range room resonances15.
Separate the tonal centers of similar-sounding voices using complementary EQ adjustments to ensure each speaker reads clearly in the combined mix1.
Apply targeted spectral de-essers to control sibilant consonants9. Use dynamic levelers with Tail Guarding to prevent the amplification of breaths and background noise during pauses12.
Phase 5: Spectral Ducking and Musical Punctuation
Structure the program's narrative pacing using defined opening themes, stings, and closing musical beds4.
Avoid broadband dynamic ducking on music beds39. Instead, use dynamic EQs or spectral processors (such as FabFilter Pro-Q 3 or Trackspacer) sidechained pre-fader to the dialogue bus36.
Carve out specific cuts only in the vocal fundamental and presence regions (100 Hz to 600 Hz and 1 kHz to 3 kHz) when dialogue is active, preserving the musical energy and high-frequency air of the bed14.
Phase 6: Spatial Design and Spatial Audio Optimization
Keep low-frequency elements centered in the Mid channel, and place ambient reverbs and stings in the Side channel43. Regularly check mono compatibility using a correlation meter43.
When mixing in Dolby Atmos, separate assets into Beds (for background ambiances and drums) and Objects (for precise dialogue and sound effect placement)51.
Optimize spatial cues using binaural rendering distance models and Head-Related Transfer Functions (HRTFs) for headphone listening, and apply subtle, tempo-synchronized pan gestures to enhance spatial depth49.
Phase 7: Master Bus Optimization and Loudness Compliance
Mix directly into a master bus chain featuring subtractive EQ, gentle VCA glue compression, tape saturation, and dynamic multiband compression across the 1 kHz to 5 kHz region to control high-mid build-up during simultaneous speech9.
Normalize the final integrated loudness to platform-specific standards: target -18 LUFS for mixed-format podcast audio (per AES77-2023), -16 LUFS for general stereo podcast distribution (per Apple Podcasts), or -14 LUFS for Spotify and YouTube57.
Ensure the maximum peak level remains at or below -1.0 dBTP to avoid intersample peak distortion on consumer playback devices5.
Works cited
Audio Mixing Techniques for Pro-Level Podcasts & Video - Flexwork Studios, https://flexworkstudios.com/audio-mixing-techniques/
10 Top Tips for Recording & Mixing Better-Sounding Podcasts | Blog - Waves Audio, https://www.waves.com/top-tips-for-recording-mixing-better-sounding-podcasts
Podcast & Dialogue Editing - JMH Sound Design, https://jmhsounddesign.com/podcast-dialogue-editing/
Podcast Like A Pro! - Sound On Sound, https://www.soundonsound.com/techniques/podcast-like-a-pro
Podcast Production 101: The Difference Between Mixing and Mastering - Tansy Aster Academy, https://tansyasteracademy.com/podcast-production-101-the-difference-between-mixing-and-mastering/
9 Tips to Mix Dialogue, Music, and SFX Without Losing Audio Clarity - PodcastVideos.com, https://www.podcastvideos.com/9-tips-to-mix-dialogue-music-and-sfx-without-losing-audio-clarity/
The 3 Plugins Your Mix Bus Signal Chain Should Include - Joe Crow - The Audio Pro, https://www.joecrowtheaudiopro.com/2021/06/30/mix-bus-signal-chain/
So You Want to Edit and Mix Your Own Podcast? | by Drew Arigadas | Better Marketing, https://bettermarketing.pub/so-you-want-to-edit-and-mix-your-own-podcast-but-dont-know-where-to-start-9b7a99ac9fa3
Anyone have a good work flow for mixing podcasts they'd like to share? - Reddit, https://www.reddit.com/r/audioengineering/comments/bsaxqu/anyone_have_a_good_work_flow_for_mixing_podcasts/
Mixing dialogue in audio storytelling | News - Sound Radix, https://www.soundradix.com/articles/mixing-dialogue-in-audio-storytelling/
Podcast Editing Made Easy: Multi-Speaker Separation + Diarization - AudioShake, https://www.audioshake.ai/post/how-to-edit-podcasts-with-multiple-speakers--fast
How much magic to put on a podcast? : r/audioengineering - Reddit, https://www.reddit.com/r/audioengineering/comments/10rw2ym/how_much_magic_to_put_on_a_podcast/
Audio Compression and EQ for Podcasters | Enhance Your Sound - Listen2It, https://www.getlisten2it.com/blog/audio-compression-and-eq-for-podcasters-enhance-your-sound/
A Guide to Audio Processing and FX For Podcasting (AU) - RØDE, https://rode.com/en-au/about/news-info/a-guide-to-audio-processing-and-fx-for-podcasting
Tips on EQing your vocals : r/podcasts - Reddit, https://www.reddit.com/r/podcasts/comments/9b6j00/tips_on_eqing_your_vocals/
EQ for Podcasting | Podigy, https://www.podigy.co/podcasters-eq
How to EQ Your Dialogue from Start to Finish: Recording Step 3 - Bryan Hurt Audio, https://www.bryanhurtaudio.com/blog/how-to-eq-voice-recording-recording-step-3
EQ and Compression for Podcasters (Who Have Never Used Them Before) - Medium, https://medium.com/@drew.arigadas/eq-and-compression-for-podcasters-who-have-never-used-them-before-206500b1562c
Industry-standard audio repair and post production with RX 12 Advanced - iZotope, https://www.izotope.com/products/rx-advanced
Master Bus FAQs for Modern Metal Production - Nail The Mix, https://www.nailthemix.com/master-bus-faqs
EBU R128, Broadcast Loudness Target - APU Software, https://apu.software/ebu-r128-loudness-target/
Auto-Align 2 User Manual - Sound Radix, https://assets.soundradix.com/downloads/Auto-Align%202.0.0r2%20User%20Manual.pdf
8 Tips for Editing Dialogue with RX 7 - iZotope, https://www.izotope.com/community/blog/8-tips-for-editing-dialogue-with-rx-7
Podcast Editing: Phasing issue in Multitrack : r/audioengineering - Reddit, https://www.reddit.com/r/audioengineering/comments/1izjxkf/podcast_editing_phasing_issue_in_multitrack/
Automatic Microphone Mixer White Paper - Yamaha, https://data.yamaha.com/files/download/other_assets/7/329527/Automixer_WhitePaper_en.pdf
Darrell Thorp using auto align to correct phase - Puremix, https://www.puremix.com/blog/darrell-thorp-using-auto-align-to-correct-phase
Pro Tools delivers Auto-Align & Post ARA support - Avid, https://www.avid.com/resource-center/sound-radix-ara
PLUGINS & SOFTWARE | Auto-Align by Sound Radix - Tutorial, https://www.creatingthesound.com/courses/plugin-tutorials-auto-align-by-sound-radix-automatic-phase-alignment
Drums microphones alignment techniques - Radicals' Lounge - Sound Radix, https://forum.soundradix.com/t/drums-microphones-alignment-techniques/33
Gain Sharing Auto Mixer, https://tesira-help.biamp.com/Component_Objects/Audio/Mixers/Gain_Sharing_Automixer.htm
Gain-Sharing Automatic Mic Mixer - Q-SYS Help, https://help.qsys.com/q-sys_10.3/Content/Schematic_Library/auto_mixer.htm
Gain Sharing Auto Mixer - Build - Audulus forum, https://forum.audulus.com/t/gain-sharing-auto-mixer/1744
Automixer Gain Sharing, https://adn.harmanpro.com/static/archimedia/aa_help/Soundweb_London/Signal_Processing_Objects/Mixers_Gains/Automixer_Gain_Sharing.htm
Ducking - Grokipedia, https://grokipedia.com/page/Ducking
Free Online Podcast Automixer — Creator Tools - ENDE.APP, https://ende.app/en/creator-tools/podcast-automixer
Sidechain Compression: The Ultimate Guide to Audio Dynamic Manipulation, https://acestudio.ai/blog/sidechain-compression-the-ultimate-guide/
How to Use Sidechain Compression in Pro Tools - Avid, https://www.avid.com/pro-tools/user-guide/sidechain-compression
Sidechain Compression Vs Sidechain EQ - Which is Better - Music Guy Mixing, https://www.musicguymixing.com/sidechain-compression-vs-sidechain-eq/
Better Ducking for Voiceovers & Podcasts - PreSonus, https://www.presonus.com/blogs/home/better-ducking-for-voiceovers-podcasts
How to Sidechain, Part 5: Podcast Intro Music - YouTube, https://www.youtube.com/watch?v=pXfP7lp3Zxw
What's the difference between compression sidechain and eq sidechain? - Reddit, https://www.reddit.com/r/audioengineering/comments/1hrd7zi/whats_the_difference_between_compression/
Difference between sidechaining with EQ vs Compressor? - Logic Pro Help, https://www.logicprohelp.com/forums/topic/152514-difference-between-sidechaining-with-eq-vs-compressor/
Stereo Imaging 101: Panning vs Balance, Width, Phase & Mono Compatibility, https://musiccitysf.com/accelerator-blog/stereo-imaging-panning-vs-balance-width-phase-mono/
Panning Tips - Sage Audio, https://www.sageaudio.com/articles/panning-tips
Guide to Panning and Stereo Width - Mastering The Mix, https://www.masteringthemix.com/blogs/learn/guide-to-panning-and-stereo-width
Ultimate guide to panning audio & instruments in a mix - Avid, https://www.avid.com/resource-center/panning-audio-guide
Creating Realistic Stereo Image with Panning - Audio Recording, https://www.audiorecording.me/creating-realistic-stereo-image-with-panning.html
Stereo Imaging: How to Widen Your Mix and Stereo Image - Avid, https://www.avid.com/resource-center/stereo-imaging-guide
Mixing and Mastering Dolby Atmos on Headphones - PodcastVideos.com, https://www.podcastvideos.com/articles/mixing-and-mastering-dolby-atmos-on-headphones/
Immersive Sound for Independent Artists: A Comprehensive Guide to Spatial Audio, Dolby Atmos & 3D Mixing | Indiefy, https://indiefy.net/blog/immersive-sound-for-independent-artists-a-comprehensive-guide-to-spatial-audio-dolby-atmos--3d-mixing
Mixing Music In Dolby Atmos Workflows and Strategies - Abbey Road Institute, https://abbeyroadinstitute.co.uk/blog/mixing-music-in-dolby-atmos-workflow-and-strategies/
Mixing Music in Dolby Atmos & Spatial Audio: From Basics to Advanced Techniques - MasteringBOX, https://www.masteringbox.com/learn/mixing-music-in-dolby-atmos
Immersive Audio Mixing Techniques: How to Create Spatial Mixes in Dolby Atmos and 3D Music - Berklee Online Take Note, https://online.berklee.edu/takenote/immersive-audio-mixing-techniques-how-to-create-spatial-mixes-in-dolby-atmos-and-3d-music/
Master Bus Processing Chains from 3 Mix Engineers - Produce Like A Pro Academy, https://producelikeapro.com/blog/master-bus-processing-chains-3-mix-engineers/
How to Process Your Master Bus - Music Guy Mixing, https://www.musicguymixing.com/master-bus/
The First Plugins to Use in a Mix Chain (and Why Order Matters) | Blog - Waves Audio, https://www.waves.com/what-plugin-go-first-in-a-mix-chain-explained
Broadcast Loudness Made Simple - NUGEN Audio, https://nugenaudio.com/broadcast-loudness-made-simple/
Podcast Loudness Standards 2026: Spotify, Apple, YouTube Requirements, https://sone.app/blog/podcast-loudness-standards-2026-spotify-apple-youtube
Understanding LUFS for Audio Consistency | PDF | Sound | Information And Communications Technology - Scribd, https://www.scribd.com/document/846356775/AA-Whitepaper-AudioLoudness-2302021
EBU R 128 - Wikipedia, https://en.wikipedia.org/wiki/EBU_R_128
Loudness Basics - AES - Audio Engineering Society, https://aes.org/resources/audio-topics/loudness-project/loudness-basics/
EBU R 128: Loudness Normalisation Guide | PDF | Science & Mathematics - Scribd, https://www.scribd.com/doc/220758589/Ebu-R-128-Loudness
Loudness metering – MiRA, https://doc.flux.audio/mira/Metering_Loudness.html
Streaming Audio Loudness Guidelines Explained - Radio World, https://www.radioworld.com/tech-and-gear/tech-tips/streaming-audio-loudness-guidelines-explained
EBU R128 Loudness Normalisation Guide | PDF | Telecommunications | Acoustics - Scribd, https://www.scribd.com/document/517404082/EBU-r128-2020
In Praise of Loudness - Musik Hack, https://downloads.musikhack.com/Papers/InPraiseOfLoudness.pdf
Recommendations for Loudness of Internet Audio Streaming and On-Demand File Playback, https://www.aesmelbourne.org.au/wp-content/uploads/2022/12/Melbourne-AES-loudness-presentation-final.pdf
Worldwide Loudness Delivery Standards - RTW Audio, https://www.rtw.com/blog/rtw-knowledge-base-1/worldwide-loudness-delivery-standards-4
AES Standards Store - Audio Engineering Society, https://aes.org/publications/standards-store/
Streaming Loudness - AES Recommendations 2021, and why you should care, https://productionadvice.co.uk/td1008/
EBU R 128 s4: What It Means, And How To Implement It Today - Telos Alliance, https://blogs.telosalliance.com/ebu-r-128-s4-what-it-means-how-to-implement-today
New R128 s4 spec: produce compliant audio with ATS - Bminty, https://www.bminty.com/r128-s4-specification-compliant-audio
Loudness Targets for Mobile Audio, Podcasts, Radio and TV - Auphonic, https://auphonic.com/blog/2013/01/07/loudness-targets-mobile-audio-podcasts-radio-tv/
Bob Katz on AES TD1008: Current recommendation is to set loudness normalization at -16 LUFS to -20 LUFS for streaming services, but the industry is working towards standardizing to -24 LUFS as consumer products improve to align it with existing broadcast, radio and video production standards : r/musicproduction - Reddit, https://www.reddit.com/r/musicproduction/comments/1qg5ukr/bob_katz_on_aes_td1008_current_recommendation_is/
Loudness and Dialogue Intelligibility = Better Listening - Radio World, https://www.radioworld.com/tech-and-gear/tech-tips/loudness-and-dialogue-intelligibility-better-listening
Fix Common Problems in Audio Streaming - Radio World, https://www.radioworld.com/tech-and-gear/tech-tips/fix-common-problems-in-audio-streaming
AES Publishes Loudness Guidelines for Online Audio - Radio World, https://www.radioworld.com/news-and-business/headlines/aes-publishes-loudness-guidelines-for-online-audio
Loudness Normalization - AES - Audio Engineering Society, https://aes.org/resources/audio-topics/loudness-project/loudness-normalization/
EBU R128 pour les Podcasts et les Sagas MP3 ? - Les Sondiers, https://d9.lessondiers.com/article/f%25C3%25A9v-2016/ebu-r128-pour-les-podcasts-et-les-sagas-mp3











