
Spoken-word post-production is a technical discipline that transforms raw, imperfect acoustic captures into highly polished, broadcast-ready assets1. Raw voice recordings inherently possess a wide and unpredictable dynamic range dictated by human physiology, varying mic techniques, and room acoustics1. Left unmanaged, these fluctuations lead to rapid listener fatigue, particularly in environments with high ambient noise where quiet syllables are easily masked and loud passages become overwhelming5.
Dynamic range processors—encompassing compressors, limiters, expanders, noise gates, and automated fader systems—work programmatically to construct an idealized version of acoustic reality that feels intimate, consistent, and pristine1. This report analyzes the technical mechanisms, circuit topologies, spatial routing matrices, sibilance control systems, and international loudness criteria that define modern professional podcast engineering.

Theoretical Foundations and Psychoacoustic Dynamics
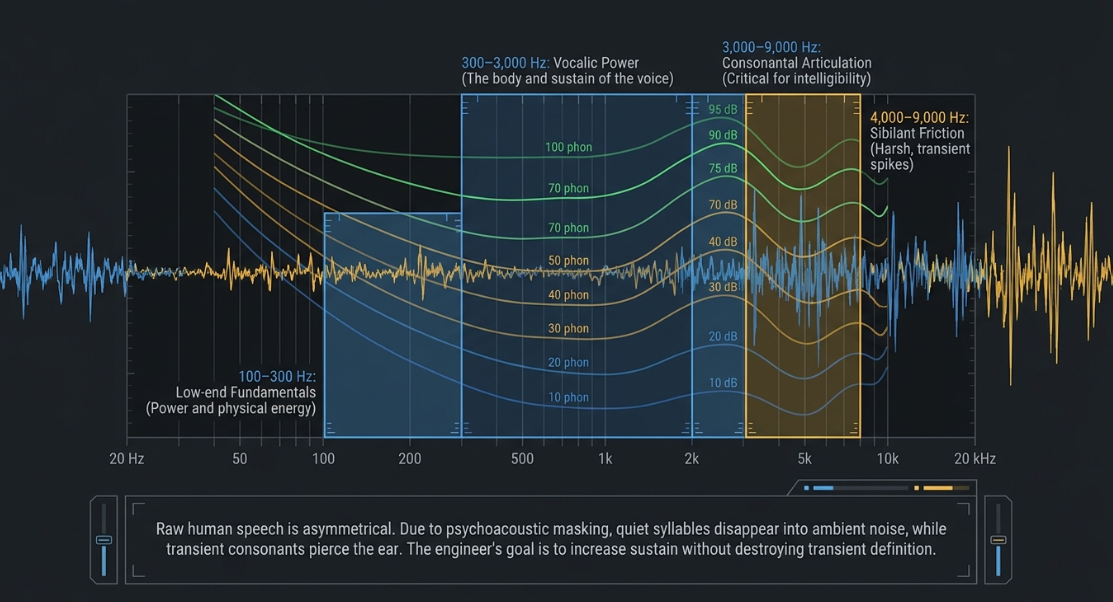
Spoken-word audio is a highly complex acoustic structure spanning the majority of the human hearing range, which extends from to 9. Speech is highly asymmetrical, characterized by low-frequency fundamentals concentrated between and 9, vocalic power (which determines the body of the voice) located between and 9, and consonantal articulation (critical for intelligibility) residing between and 9. Sibilant friction, which produces harsh high-frequency transients, is typically centered between and 9.
Understanding the human perception of these frequencies is critical to post-production. According to psychoacoustic principles, human hearing is non-linear across the frequency spectrum, a phenomenon mathematically modeled by equal-loudness contours11. An increase in physical sound pressure level results in a disproportionate increase in the human perception of low-frequency richness and high-frequency clarity1. Consequently, untrained listeners almost universally select a louder mix as a "better" mix, even if its dynamic integrity has been severely compromised by over-compression1.
In podcasting, applying heavy dynamic range compression to a voice reduces its transient nature and increases its sustain1. This mathematically increases its sonic weight, causing it to consume more space in the mix and mask neighboring elements like background music beds or sound design1. Thus, dynamic processing must be executed with high surgical precision to preserve transient definition while achieving essential level consistency1.
The post-production chain begins with a clear structural separation between editing (determining what content stays and goes) and mixing (shaping the balance, tone, and dynamic profile of the track)2. This workflow is executed within professional Digital Audio Workstations (DAWs) such as Avid Pro Tools, Reaper, or Apple Logic Pro14. Additionally, the storage medium dictates how raw files are handled5. Lossy compression formats, such as MP3, reduce file sizes by eliminating bits of audio deemed psychoacoustically undetectable to human ears, at the cost of transient detail and dynamic fidelity5. Conversely, lossless compression formats, such as FLAC or WAV, preserve the exact bit-for-bit integrity of the original capture, making them the mandatory choice for archiving and initial mixing stages5.
Hardware-Emulated Compressor Topologies
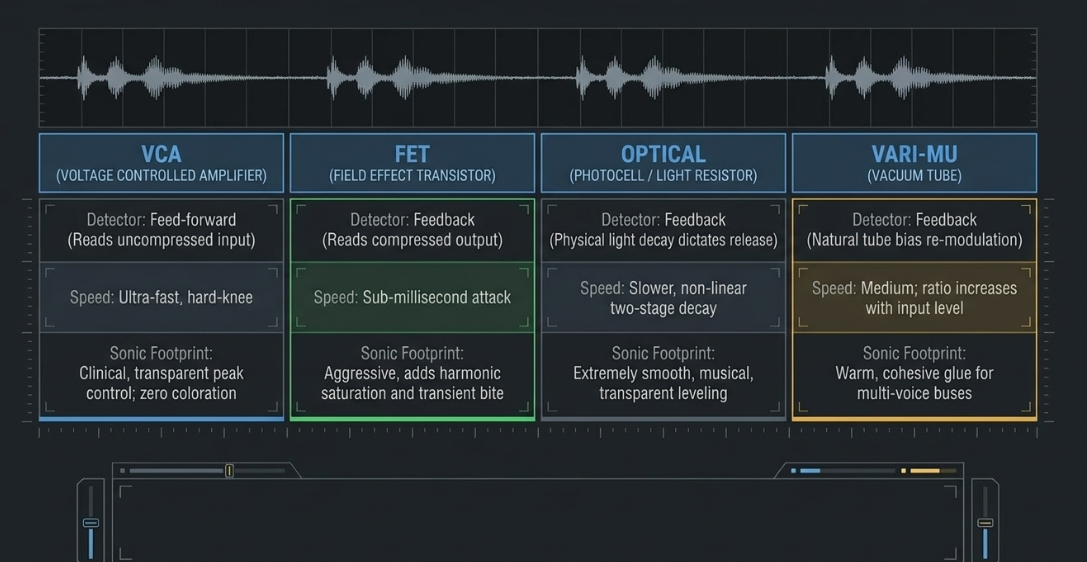
In the analog domain, compressors are defined by their electronic circuit architectures, which dictate how they detect and attenuate signals19. In digital post-production, the emulation of these classic topologies provides the mixing engineer with unique structural and harmonic profiles to shape the voice19.
The primary solid-state and tube-based topologies utilized in professional spoken-word mixing are Voltage Controlled Amplifiers (VCA), Field Effect Transistors (FET), Optical (Opto) photocells, and Variable-Mu (Vari-Mu) vacuum tubes19.
Topological Interactions in Spoken Word
The differences between feedback and feed-forward architectures are highly relevant to speech processing24. Feed-forward VCA compressors analyze the raw, incoming signal directly, executing precise, hard-knee mathematical gain reduction based on user-defined thresholds24. This makes them excellent for master bus limiting or transparent clinical gating19.
In contrast, feedback compressors (such as FET and Optical units) analyze the signal after the gain reduction circuit has already acted24. Because the detector evaluates an already compressed waveform, the resulting gain reduction is inherently smoother, more musical, and highly self-adjusting20.
For highly dynamic voices, coupling these topologies in series leverages the fast, transient-catching response of an FET circuit with the gentle, leveling behavior of an Optical circuit, creating a transparent compression profile27.
Advanced Serial and Multistage Compression Architectures
Applying a single stage of heavy compression to a dynamic voice channel frequently introduces unpleasant side effects: the noise floor is audibly raised, high frequencies can sound squashed, and "pumping" artifacts degrade the natural cadence of the speech3. Professional engineers bypass these limitations by splitting the dynamic workload across multiple processors and routing configurations3.
Serial Compressor Stacking (Double Compression)
Serial compression is the practice of placing two or more compressors in sequential order on a single vocal insert chain27. The fundamental philosophy of this technique is to achieve subtle, transparent leveling by distributing gain reduction28. Instead of forcing one compressor to execute of gain reduction, separate compressors are configured to apply of reduction each3.
[Raw Audio Input]
│
▼
┌──────────────┐
│ Compressor 1 │ ◄── Fast Attack (~20ms) / Hard Knee (Tames sudden transient peaks) [cite: 5, 28]
└──────┬───────┘
│
▼
┌──────────────┐
│ Equalizer │ ◄── Tonal shaping (HPF at ~80Hz, low-mid cuts, presence boost) [cite: 5, 30]
└──────┬───────┘
│
▼
┌──────────────┐
│ Compressor 2 │ ◄── Slow Attack / Long Release (~200ms) (Establishes vocal leveling) [cite: 5, 28]
└──────┬───────┘
│
▼
┌──────────────┐
│ Compressor 3 │ ◄── Ultra-Slow, Program-Dependent Release (Smooths overall tone) [cite: 3, 28]
└──────┬───────┘
│
▼
[Processed Vocal Output]
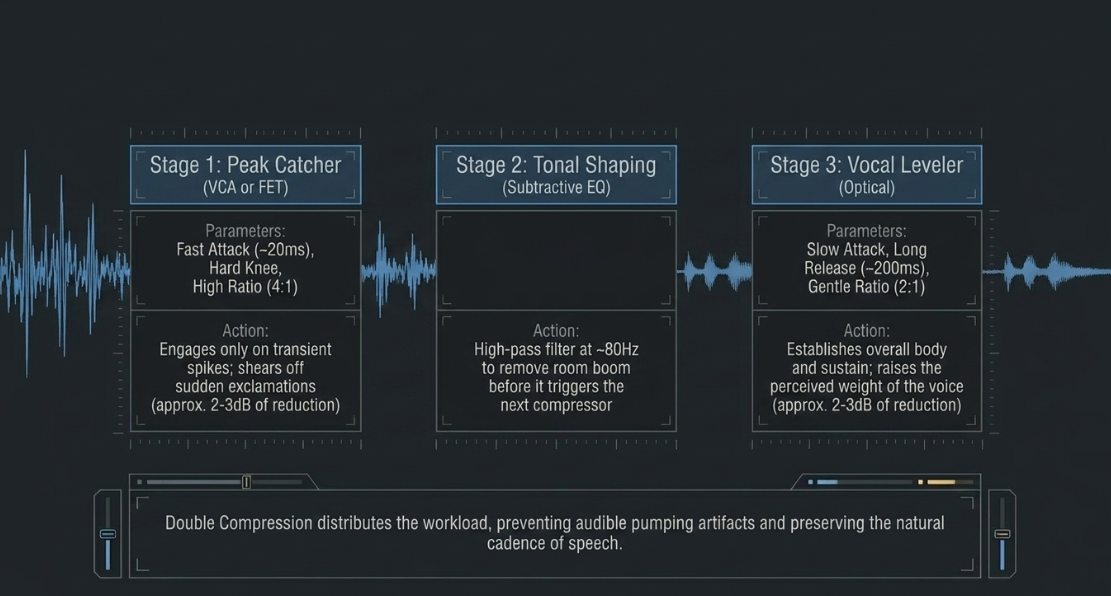
In a standard serial chain, Compressor 1 is positioned at the top of the insert stack to act strictly as a peak-catcher3. It utilizes a fast attack time () and a relatively high ratio () with a high threshold27. This ensures it only engages during sudden exclamations or transient spikes, leaving the average conversational passages completely untouched1.
Following an intermediate equalization stage to correct low-end room boom or muddy mid-frequencies3, Compressors 2 and 3 are introduced to handle overall leveling and tone shaping3. These units employ slow attack times, gentle ratios (), and soft knees, allowing the vocal transients to pass through unimpeded while raising the perceived sustain and body of the spoken voice3.
A classic software implementation of this multi-stage concept is Sonic Anomaly’s Trileveler 23. This plugin houses three virtual compressor engines operating in tandem3. The first engine uses a fast attack to tame sudden peaks; the second operates with medium speed parameters to manage the main body of the vocal; the third acts as a slow leveller to ensure the global program level conforms to broadcast loudness targets3.
Two-Stage Parallel-to-Series Integration
Distinct from standard series daisy-chaining, two-stage compression involves blending a compressed signal with an uncompressed signal and then compressing the summed result33. This routing path can be established digitally using auxiliary buses:
┌─────────► [Dry / Uncompressed Bus] ────────┐
│ │
[Raw Input Track]─┤ ▼
│ ┌─────────────┐
└─────────► [Compressor 1 (Parallel)]►│Summed Bus ──►Compressor 2]
└─────────────┘
The first stage of this technique utilizes parallel compression6. The dry, uncompressed signal is split, with one path routed to a heavy compressor (Compressor 1) set for of gain reduction with a slow release28. The output of Compressor 1 is returned on an auxiliary channel and blended underneath the dry signal33.
During quiet conversational passages, the highly compressed parallel path adds dense body, low-level detail, and room presence without destroying vocal transients6. During louder sections, the parallel path hits its ceiling within the compressor, allowing the dry signal to naturally dominate the mix and mask any pumping artifacts33.
The summed blend of both paths is then routed to Compressor 2, which acts with gentle parameters to glue the final summed performance together33.
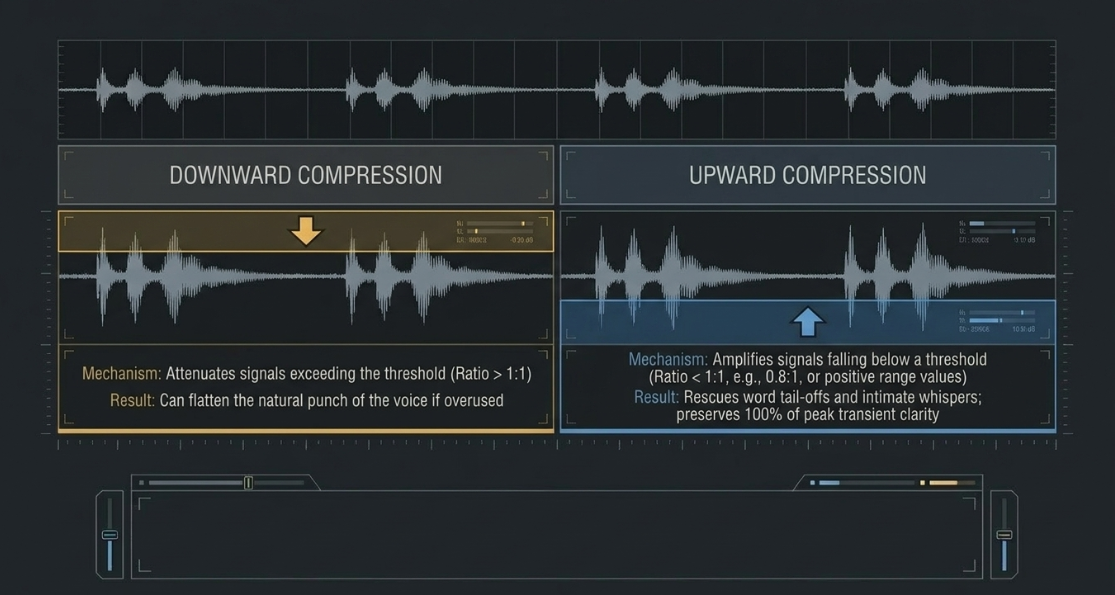
Upward (Low-Level) Compression Mechanics
While traditional downward compression acts by attenuating signals that exceed a specified threshold34, upward compression achieves dynamic range reduction by amplifying signals that fall below a set threshold35.
The mathematical transfer function of upward compression is characterized by ratio values represented below (e.g., or in digital processors like iZotope Neutron)38, or by positive range values on multiband expanders like FabFilter Pro-MB37 and Waves F640. When the input signal falls below the low-level threshold, the processor increases the gain of that specific band up to a predetermined maximum ceiling, typically defined by a range parameter37.
The primary advantage of upward compression in podcast post-production is its ability to rescue low-level speech nuances—such as word tail-offs, quiet guest pronunciations, or emotional whispers—without modifying the peak transients of the voice23. Because peak transients are left entirely uncompressed, the natural punch, clarity, and open character of the vocal performance are completely preserved6.
Over-processing with upward compression, however, runs the risk of unnaturally elevating room hiss, headphone bleed, and vocal mouth-clicks, requiring a balanced combination of expansion and gating upstream3.
Bleed Mitigation, Cross-Talk Suppression, and Automatic Mixing
In multi-microphone, non-isolated environments (such as a round-table podcast recording in a shared room), microphone bleed represents a major challenge42. Bleed occurs when sound waves from a primary speaker leak into adjacent microphones, arriving at slightly different times due to physical distance42. This temporal offset causes comb filtering and phase cancellation upon summing the tracks, resulting in a thin, hollow, and unnatural vocal tone42.
Dynamic processors are the primary tool used to mitigate bleed and restore phase authority in the mix42.
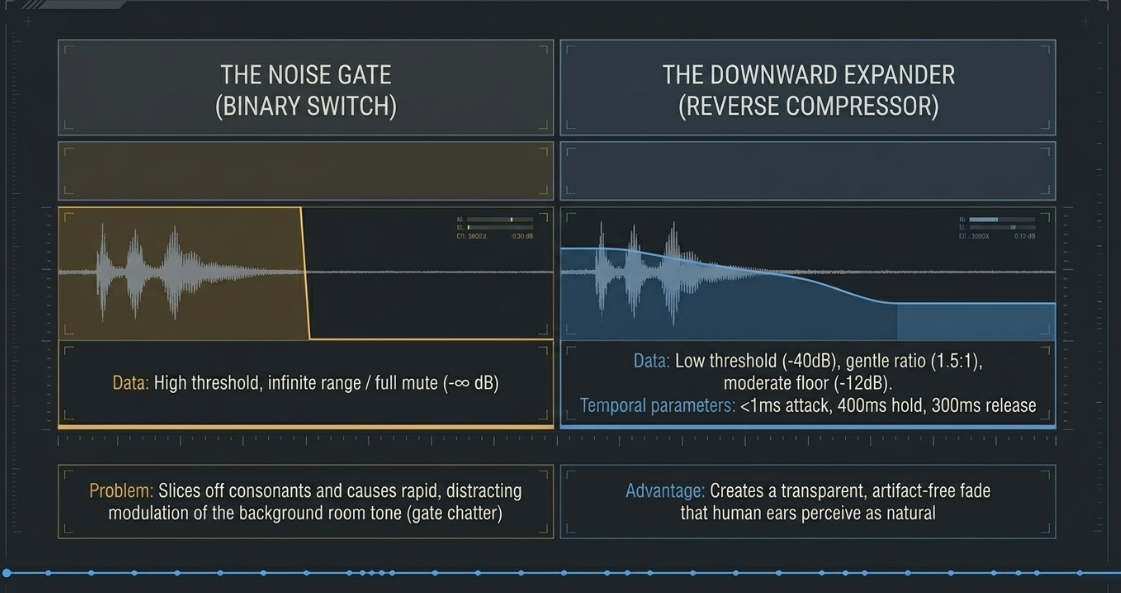
Technical Divergence: Noise Gates vs. Downward Expanders
Noise gates and downward expanders both attenuate signals that fall below a specified threshold, but their mathematical application of attenuation differs significantly8.
A noise gate operates as a binary switch: if the signal falls below the threshold, the gate closes and applies complete attenuation (often ) or a fixed amount determined by a range control45. If a speaker tails off their sentence or speaks softly, a noise gate will abruptly slice off the consonants, creating a highly distracting, choppy listening experience46. Furthermore, when the speaker does speak, the gate swings open, suddenly revealing the background noise floor46. This sudden modulation of noise is highly noticeable to the human brain, which is adept at filtering out constant room tone but highly sensitive to abrupt transitions47.
Downward expanders, conversely, are modeled as "reverse compressors"46. Rather than executing an all-or-nothing cutoff, they reduce the gain of below-threshold signals proportionally based on a gentle ratio15. For example, with a downward expander ratio of and a threshold of , a signal that falls to ( below threshold) will be attenuated by only (outputting at ), while a signal at is attenuated by 15. This produces a smooth fade into the background noise floor15.
To prevent the dynamic processor from rapidly cycling open and closed when a signal hovers near the threshold—a destructive phenomenon known as "gate chatter"—engineers utilize specific temporal controls45:
Attack: Set extremely fast () to ensure the processor opens instantly upon the first consonant of a spoken word15.
Hold: Configured between 45. This forces the gate or expander to remain fully open for a brief period after the signal drops below the threshold, allowing conversational pauses and short breaths to pass through un-truncated15.
Release: Set to a gentle window () to smoothly fade out the tail end of words5.
Range (or Floor): Restricts the maximum attenuation to a modest value (e.g., ) rather than complete silence46. This maintains a continuous, low-level room tone, preventing unnatural "black holes" of absolute digital silence in the stereo field48.
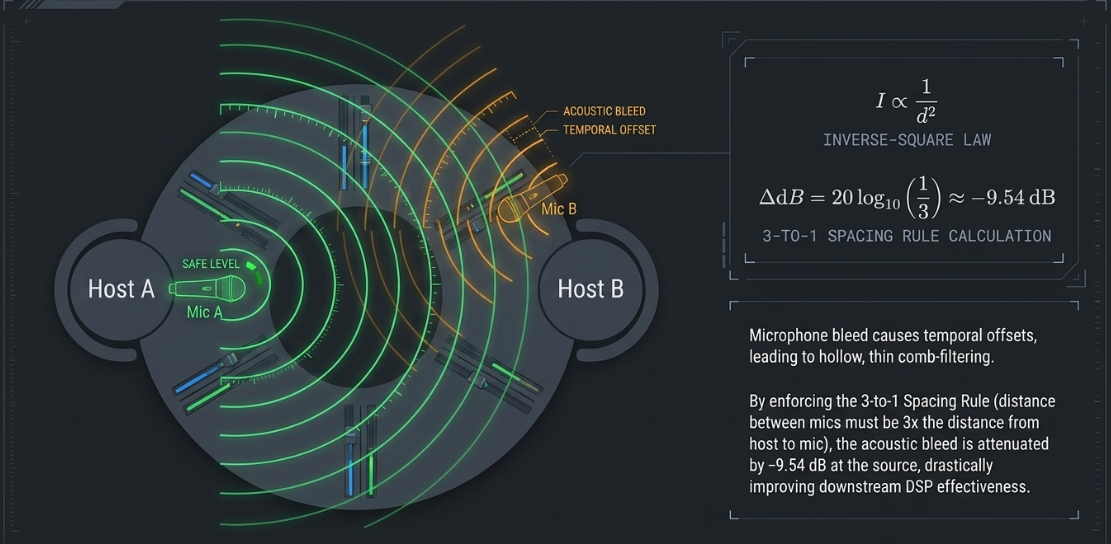
Physical Spacing and Algorithmic Phase Mitigation
While dynamic expanders manage bleed in post-production, physical acoustics dictate the ultimate signal-to-noise limit of what can be achieved42. Engineers enforce the 3-to-1 Spacing Rule, which dictates that the distance between any two active microphones must be at least three times the distance from each microphone to its respective talker42.
This rule is grounded in the inverse-square law of sound propagation, which states that sound intensity decreases inversely proportional to the square of the distance from the source42:
By tripling the distance of the secondary microphone from the primary talker (), the bleed signal undergoes significant acoustic attenuation42:
This reduction in bleed level at the acoustic source dramatically increases the efficiency of downstream expanders and prevents comb filtering42.
For multi-mic setups where physical separation is restricted, engineers utilize specialized phase alignment algorithms in post-production, such as Sound Radix Auto-Align Post 242. Unlike static phase alignment tools that apply a single, fixed time-delay to an entire track, dynamic post-production aligners analyze clips continuously, applying real-time, intra-clip micro-delay shifts and phase rotations to compensate for physical movement of the talkers relative to the microphones42.
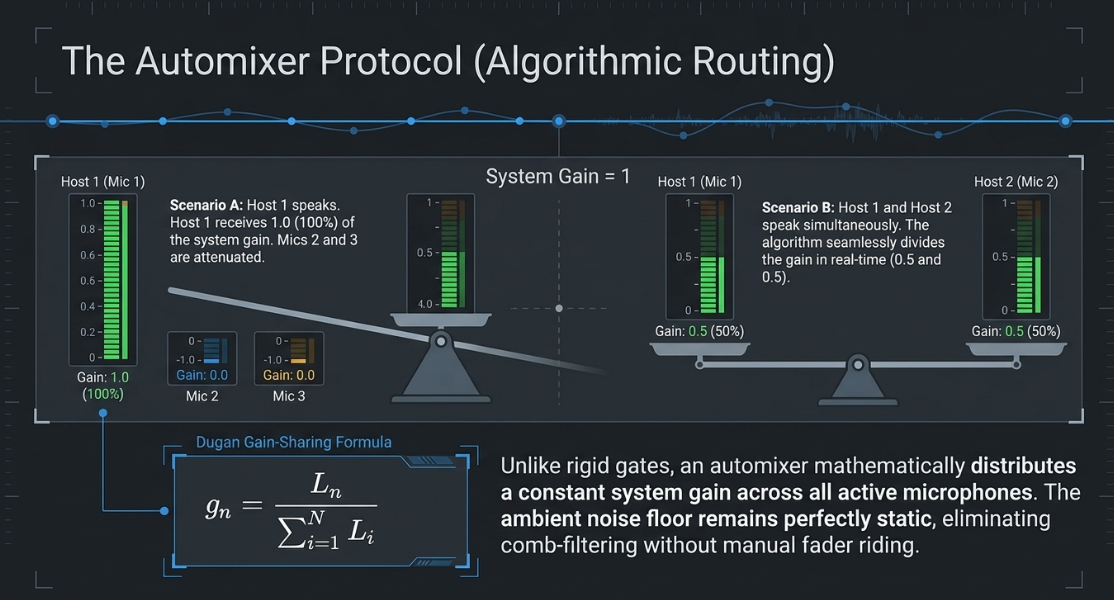
Gain-Sharing Automixers
In panel discussions or podcasts with three or more active hosts, manual fader riding of all channels is highly labor-intensive, and simple gating causes choppy background noise modulation44. For these scenarios, engineers employ real-time gain-sharing automixers, most notably those based on Dan Dugan's proprietary automixing algorithm (such as Waves Dugan Speech)44.
The Dugan algorithm operates by mathematically distributing a constant sum of system gain across all active microphones54. The gain () assigned to channel is calculated in real time based on the ratio of that channel's input level () to the sum of all channel inputs44:
If only one person speaks, their microphone receives () of the system gain, while all other microphones are attenuated proportionally44. If two people speak simultaneously, the gain is shared equally ( each), ensuring the total combined ambient noise and system gain remains exactly equal to a single open microphone44. This eliminates comb filtering, controls room reverberation build-up, and prevents the abrupt gating artifacts that distract listeners44.
Sibilance Management: Wide-Band, Split-Band, and Spectral De-Essing
As vocal tracks undergo serial compression and high-frequency presence boosting, sibilant consonants (such as "s," "z," "ch," and "sh") are inevitably amplified, creating harsh, piercing spikes in the to region9. To tame this harshness without dulling the entire performance, engineers implement specialized frequency-dependent compressors known as de-essers10.
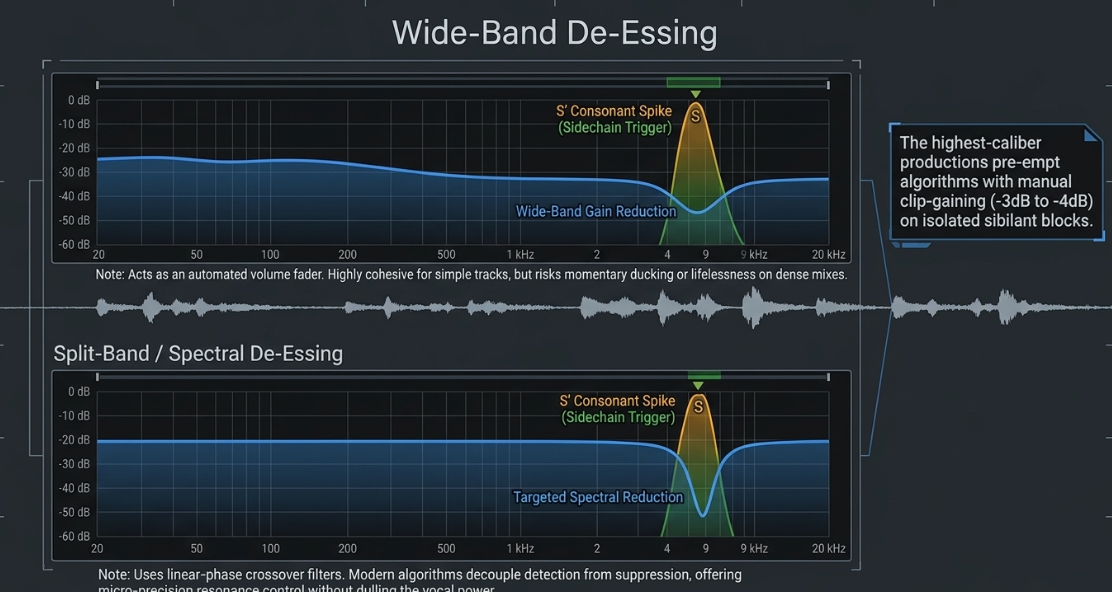
Functional Divergence: Wide-Band vs. Split-Band De-Essing
De-essers utilize a sidechain filter loop to isolate sibilant frequencies, using this filtered path to trigger gain reduction on the main vocal signal10. However, how they execute this gain reduction defines their architectural type59.
In Wide-Band De-essing, when high-frequency sibilance crosses the sidechain detector threshold, the processor attenuates the volume of the entire vocal spectrum evenly57. This is a digital replication of manual clip-gain attenuation10. While wide-band de-essing can sound highly cohesive and transparent on isolated, single-vocal tracks with moderate dynamics57, it can introduce noticeable volume dipping on heavily compressed or dense vocal tracks, causing the vocal to feel momentarily "ducked" or lifeless60.
In Split-Band De-essing, when sibilance is detected, the compressor applies gain reduction exclusively to a targeted high-frequency band (using a linear-phase crossover filter, typically starting around to )57. The lower frequencies (vowels, mid-range body) remain completely untouched, ensuring consistent vocal power and presence59.
However, if split-band crossovers are pushed too aggressively, they can introduce phase shifts at the crossover point, causing the high end of the vocal to sound disconnected, unnatural, or slightly lispy57.
Manual Clip-Gaining of Sibilants
Before applying any de-essing software, the highest-caliber vocal productions utilize manual sibilance editing9. The editor visually identifies sibilant passages in the raw DAW timeline (which present as dense, high-frequency "blocks" in the waveform), splits them into isolated clips, and manually reduces the clip gain by 10.
While highly labor-intensive, this completely eliminates the workload on subsequent automatic de-essers, yielding a perfectly natural, artifact-free high-frequency response10.
Advanced Digital De-Essers and Resonators
Modern post-production relies on highly precise digital algorithms that extend far beyond simple band-attenuation:
FabFilter Pro-DS: Renowned for its highly intelligent "Single Vocal" detection algorithm, which accurately distinguishes between actual sibilant consonants and vocalized vowels, applying program-dependent compression with look-ahead capabilities up to 56.
oeksound soothe2: A dynamic resonance suppressor that operates via high-resolution spectral analysis across the entire frequency range56. It tracks resonances on the fly and dynamically attenuates them with hundreds of micro-precision bands, offering pristine, transparent sibilance control23.
Softube Weiss Deees: A line-by-line digital port of the classic Weiss DS1-MK3 hardware56. It features a dual-band interface with ultra-precise filter shapes and a low-latency mode, ensuring transparent, mastering-grade high-frequency limiting56.
Lindell Audio 902: A digital emulation of the classic dBx 902 hardware de-esser56. It features a threshold-free design that continuously compares high-frequency energy against the overall program level, delivering identical, smooth de-essing on both whispered and belted passages56.
Klevgrand Esspresso: A modern de-esser that decouples the sibilant detection range from the active suppressor band56. This allows the engineer to listen to and detect a narrow, offending high-frequency transient (e.g., ) while compressing a completely different, wider shelf (e.g., )56.
Linear Fader Riding and Leveling Automation
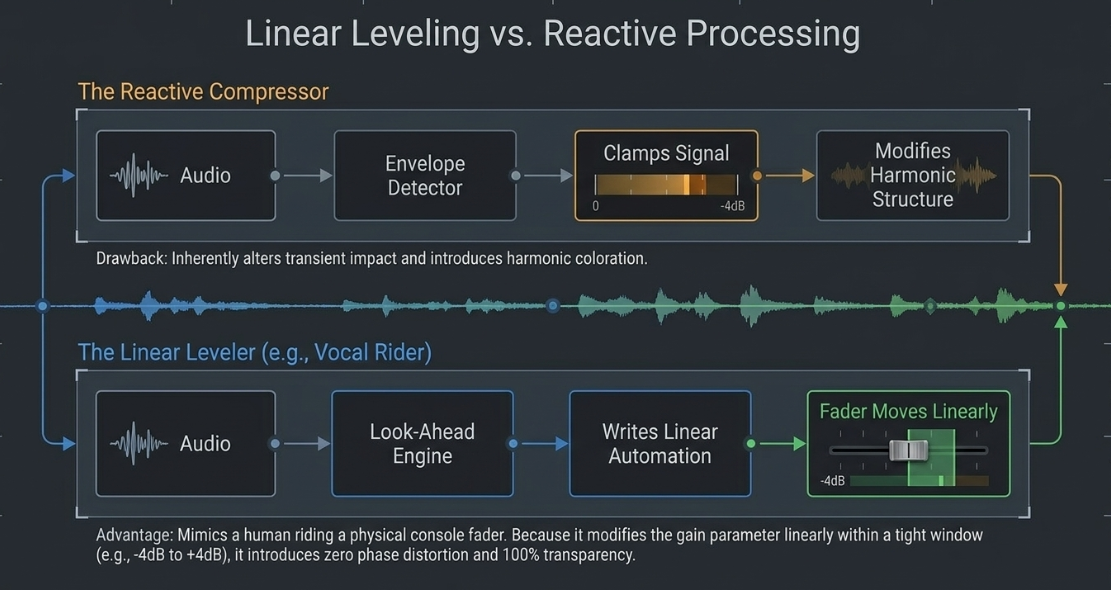
While dynamic range compressors are highly effective at smoothing out speech, they are reactive processors that modify the transient and harmonic structure of the signal1. For maximum transparency, engineers often prefer to level out broad volume swings using fader automation—a process historically executed by physically riding the console faders4. In modern digital workflows, this task is automated using intelligent look-ahead gain-shaping plugins, most notably Waves Vocal Rider23.
Mechanical Discrepancy: Vocal Rider vs. Compressor
A compressor reacts when a signal crosses a threshold, using an envelope detector to clamp down on the audio and introduce harmonic coloration, transient flattening, and potential distortion1.
Waves Vocal Rider, conversely, operates as an automated fader4. It employs an intelligent look-ahead analysis engine to continuously evaluate the average level of the incoming vocal, comparing it directly to a user-defined target level23.
The plugin then automatically writes linear volume automation to raise or lower the channel gain, exactly mimicking a human engineer riding a physical fader4. Because it modifies the gain parameter linearly, it introduces zero coloration, zero phase distortion, and preserves the natural transient impact of the vocal performance4.
Strategic Parameters of Automated Gain Shapers
To optimize fader riding in a complex mix, the dynamic engine of Vocal Rider is adjusted using four critical interactive controls4:
Vocal Sensitivity: Acts as an input gate threshold, telling the algorithm to ignore background noises, mouth clicks, or breathing, and only engage fader movements when active vocal speech is detected4.
Target: Sets the desired focal point of the output signal (typically matching the overall channel balance target)4.
Range (Min/Max): Restricts the maximum physical travel of the automated fader4. For spoken-word dialogue, a tight window of to is standard to prevent dramatic noise-floor swells during long pauses62.
Music Sensitivity (Sidechain): Allows the plugin to ingest an auxiliary send from the background instrumental/music track4. The plugin dynamically adjusts the vocal target based on the music volume—raising the fader when the music swells to maintain voice intelligibility, and lowering it when the music thins out4.
Tactical Signal Chain Sequencing
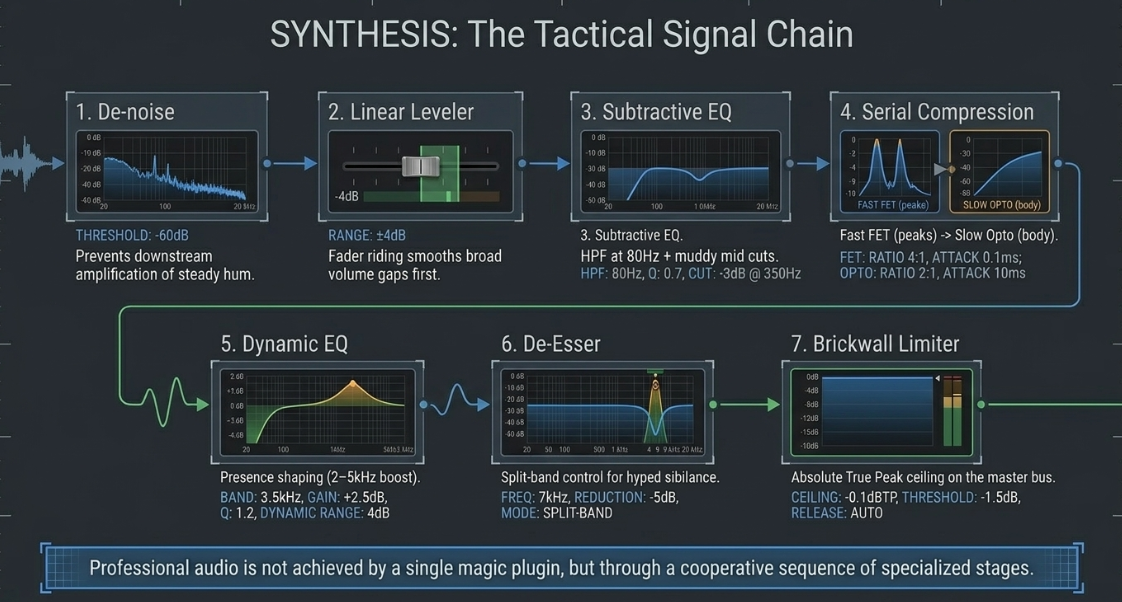
In a professional spoken-word channel strip, processors must be ordered in a logical sequence to prevent negative downstream interactions29:
Cleanup & De-noising: iZotope RX Voice De-noise is placed first to clean up any steady hum, preventing downstream compressors from amplifying background noise23.
Linear Leveler (Vocal Rider): Positioned next to smooth out broad dynamic swings and conversational volume gaps before hitting any reactive plugins29.
Subtractive Equalization & Filters: High-pass filter (typically ) to remove subsonic mud and room rumble, followed by surgical cuts in the boxiness region5.
Serial Compression: A fast-attack compressor to catch remaining peaks, followed by a slow optical leveling compressor to add cohesive tone and density3.
Dynamic EQ & Presence Shaping: Precise, high-mid boosts () to enhance presence and clarify consonants5.
De-Esser: Placed after compression and EQ to ensure any high-frequency sibilance hyped up by downstream processing is targeted and tamed3.
Brickwall Limiter: Positioned at the very end of the master stereo bus to guarantee absolute peak control and prevent digital clipping2.
International Loudness Normalization and Compliance
The final stage of podcast post-production is mastering, where the mixed program is prepared for distribution2. Unlike music mastering, which historically chased competitive peak-normalization levels, podcast mastering is governed strictly by international loudness standards designed to ensure consistent playback volume across various distribution platforms14.
The Mathematical Framework of ITU-R BS.1770-5
International loudness measurement is standardized under the ITU-R BS.1770-5 recommendation, which defines the algorithms for calculating subjective program loudness and digital True Peak levels66.
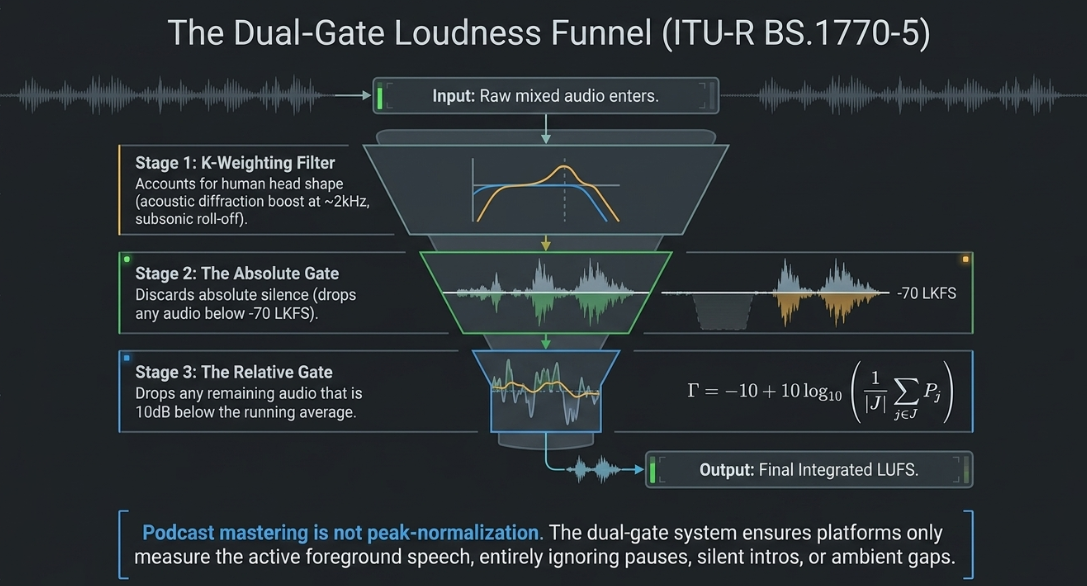
Traditional VU and peak meters fail to represent how the human ear actually perceives sound intensity13. To address this, the ITU-R BS.1770 standard introduces K-Weighting, a two-stage pre-filtering curve that weights frequencies based on human physiological perception11.
The first stage of pre-filtering accounts for the acoustic diffraction of the human head, modeled as a rigid sphere, and is implemented via a second-order high-shelf filter providing a boost starting around 11. The second stage applies a simple high-pass filter to roll off low frequencies below that contribute significantly to physical energy but are psychoacoustically weighted far less by human hearing5.
Once the multi-channel signal is passed through the K-weighting filter, the power (mean square) of each filtered channel is calculated over a specified measurement interval ()66:
For a gated loudness measurement, the program is divided into overlapping gating blocks of duration with a overlap ( step)66. The power () of the -th gating block of the -th channel is calculated66:
The momentary loudness () of each segment is calculated69:
where represents the weighting coefficients for individual channels ( for Left, Right, and Center, and for surround channels to account for psychoacoustic rear-field acoustic summation, with the LFE channel excluded entirely)66.
The Dual-Gate Architecture of Gated Loudness
To prevent quiet pauses, silent intros, or ambient gaps from skewing the average loudness measurement of an entire program, ITU-R BS.1770 employs a dual-gate measurement framework11:
Absolute Gate: The momentary power of any gating block with a loudness level falling below is discarded from the calculation11.
Relative Gate: Using the remaining blocks, a relative threshold () is computed at exactly below the average loudness of all blocks that passed the absolute gate11:
Any gating block falling below this relative threshold () is discarded11.The final Integrated Loudness is calculated strictly from the remaining blocks, ensuring that the measurement represents the active foreground programming rather than silent gaps11.
Time-Domain Loudness Metrics
In addition to the Integrated Loudness (the average loudness calculated over the entire duration of a file)13, engineers monitor two short-term time-domain measurements to assess real-time dynamics13:
Momentary Loudness: Represents the ungated loudness calculated over a fast, sliding window, useful for monitoring sudden speech bursts or transient swells13.
Short-Term Loudness: Represents the ungated loudness integrated over a sliding window, providing a highly reliable visual approximation of the perceived conversational volume of the current sentence13.
Loudness Range (LRA): Quantifies the variations in loudness over the duration of the track12. LRA is calculated as the difference between the 10th percentile and the 95th percentile of the short-term loudness distribution13. Excluding the bottom 10% prevents fades or silent pauses from distorting the range, while excluding the top 5% ensures that a single unusually loud event (such as a sudden mic bump or exclamation) does not disproportionately skew the measurement13.
Platform Normalization Standards and Behaviors
Podcast distribution networks ingest master files and apply real-time loudness normalization to achieve uniform playback volume for their consumers16.
Because different platforms utilize different target levels and normalization engines, understanding their structural behavior is vital for post-production mastering7.
The critical architectural distinction lies in how these platforms handle quiet masters16. Apple Podcasts (using its Sound Check protocol) and Spotify will apply positive gain to boost a quiet podcast up to their target level16. However, to preserve dynamic range and prevent distortion, Apple will refuse to apply the full positive boost if doing so would cause the True Peak to exceed 65.
YouTube and Amazon Music, on the other hand, employ a downward-only normalization workflow16. If a podcast is mastered too loud (e.g., ), these platforms will turn it down to the standard 16. But if a podcast is mastered too quiet (e.g., ), they will never apply positive gain16. The file will play at its original quiet level, forcing the listener to manually adjust their volume and risking a poor user experience7.
Therefore, mastering professionals widely adopt integrated with a ceiling as a safe, cross-platform standard for pure spoken-word podcasts16. For video-centric podcasts distributed primarily on YouTube and Spotify, mastering to integrated ensures compliance with their louder targets while preserving sufficient dynamic range for natural speech delivery16.
Conclusions and Actionable System Integration
Dynamic range processing in professional podcast post-production requires a deep understanding of acoustics, circuit topologies, and digital signal processing1. A professional mix is achieved not by a single heavy-handed processor, but through a sequence of subtle, cooperative stages: manual cleanup, clip-gain normalization, look-ahead fader riding, topological serial compression, split-band de-essing, and careful loudness measurement2.
By balancing and controlling spoken-word dynamics, post-production engineers build a cohesive, accessible listening experience that respects the listener's time and attention2. This technical precision establishes the foundation for high-quality audio that translates perfectly across consumer playback systems worldwide6.
Works cited
Audio Engineering in a Professional Podcast Post-Production - Finchley Studios, https://www.finchley.co.uk/finchley-learning/visual-podcast/audio-engineering-in-a-professional-podcast-post-production
Post Production in Audio: Editing and Mixing - Journalism University, https://journalism.university/audio-podcast/post-production-audio-editing-mixing/
Compression for Podcasting - Podigy, https://www.podigy.co/compression-for-podcast
Is Waves Vocal Rider the Solution to Levels? - Produce Like A Pro, https://producelikeapro.com/blog/waves-vocal-rider/
Audio Compression and EQ for Podcasters | Enhance Your Sound — Listen2It Blog, https://www.getlisten2it.com/blog/audio-compression-and-eq-for-podcasters-enhance-your-sound
Audio Mixing Techniques for Pro-Level Podcasts & Video, https://flexworkstudios.com/audio-mixing-techniques/
Why Setting the Correct LUFs for Your Podcast is Crucial: A Guide for Podcasters, https://www.podcaststudioglasgow.com/podcast-studio-glasgow-blog/why-setting-the-correct-lufs-for-your-podcast-is-crucial-a-guide-for-podcasters
A Guide to Audio Processing and FX For Podcasting (GB) - RØDE, https://rode.com/en-gb/about/news-info/a-guide-to-audio-processing-and-fx-for-podcasting
What is de-essing? The dos and don'ts of using a de-esser - iZotope, https://www.izotope.com/community/blog/the-dos-and-donts-of-de-essing
Mastering for Spotify, Apple Music & More – the Loudness of the Pros | HOFA-College, https://hofa-college.de/en/blog/mastering-for-spotify-apple-music-more-the-loudness-of-the-pros/
K-weighting - Fora Soft, https://www.forasoft.com/learn/audio-for-video/glossary/terms-audio/k-weighting
Several Things About Loudness | Audiokinetic, https://www.audiokinetic.com/fr/community/blog/about-loudness/
Mastering Podcast Editing and Post-Production: Your Ultimate Guide - Podigy, https://www.podigy.co/mastering_podcast_editing_and_post-production_your_ultimate_guide
A Podcaster's Guide To Noise Reduction | by Joe Nash - Medium, https://medium.com/@jowie/a-podcaster-s-guide-to-noise-reduction-e8cad9fc21f4
Podcast Loudness Standards 2026: Spotify, Apple, YouTube Requirements, https://sone.app/blog/podcast-loudness-standards-2026-spotify-apple-youtube
Podcast Loudness Standard: Perfecting Your Sound in 2026 - Descript, https://www.descript.com/blog/article/podcast-loudness-standard-getting-the-right-volume
Loudness normalization on Spotify, https://support.spotify.com/us/artists/article/loudness-normalization/
Different Types of Compressors and Their Uses - Resonance Studios, https://resonancestudios.co.uk/blogs/news/different-types-of-compressors-and-their-uses
Exploring Types of Audio Compressor Circuits: VCA to VARI-MU - MasteringBOX, https://www.masteringbox.com/learn/audio-compressors-vca-opto-fet-compression-circuit-types
Audio Compressor Types Explained: VCA, FET, Optical & Vari-mu - Simply Mixing, https://www.simplymixing.com/blog/audio-compressor-types
Compression Explained: FET, VCA, Optical, Variable-Mu - Mastering.com, https://mastering.com/compression-explained-fet-vca-optical-variable-mu/
Top 10 Audio Plugins for Podcast Production, https://podcastengineeringschool.com/top10/
4 Types of Analog Compression—and Why They Matter in a Digital World - iZotope, https://www.izotope.com/community/blog/4-types-of-analog-compression-and-why-they-matter-in-a-digital-world
Guitar Compressor Types Explained - Michael Banfield, https://www.michaelbanfieldguitar.com/blog/compressor-types
Plugins for Streaming & Podcasting - Waves Audio, https://www.waves.com/plugins/streaming-podcasting
How do you do the double compressor vocal technique? : r/audioengineering - Reddit, https://www.reddit.com/r/audioengineering/comments/1g8ohag/how_do_you_do_the_double_compressor_vocal/
Double Compressions Changes Everything | Korneff Audio Inc, https://korneffaudio.com/double-compressions-changes-everything/
Pro Audio: Plugins and Processing Tips for Mixing Podcasts - MacSales.com, https://eshop.macsales.com/blog/66337-plugins-processing-tips-for-mixing-podcasts/
Crafting a Basic Vocal Chain: A Step-by-Step Tutorial - Audient, https://audient.com/tutorial/crafting-a-basic-vocal-chain-a-step-by-step-tutorial/
How to Build the Ultimate Vocal Chain for Professional Sound: Mixing & Vocal Processing Guide | Antares Tech - AutoTune, https://www.antarestech.com/community/what-is-a-vocal-chain
Is their a native approach to Waves VocalRider? - Cubase - Steinberg Forums, https://forums.steinberg.net/t/is-their-a-native-approach-to-waves-vocalrider/895741
Two Stage Compression: Advanced Dynamics Control - Tape Op, https://tapeop.com/interviews/61/two-stage-compression
Your audio journey – Part 42 – Noise gate / Downward expander - Mark Denholm, http://markdenholm.com/your-audio-journey-part-42-noise-gate-downward-expander/
Upward Compression - Podcast Engineering School, https://podcastengineeringschool.com/upward-compression/
WTF Is Upward Compression (and Why You NEED IT!) - Raytown Productions, https://www.raytownproductions.com/blog/what-is-upward-compression-and-why-you-need-it/
How To Use Upward Compression - Md3sign Studio, https://md3signstudio.com/blogs/mixing/how-to-use-upward-compression-md3sign-studio
4 tips for using upward compression in Neutron - iZotope, https://www.izotope.com/community/blog/4-tips-for-using-upward-compression-in-neutron
C6 Multiband Compressor Plugin with Sidechain - Waves Audio, https://www.waves.com/plugins/c6-multiband-compressor
Upward Compression: The Overlooked Mix Hack You've Been Missing | Blog - Waves Audio, https://www.waves.com/upwards-compresion-the-overlooked-mix-hack-youve-been-missing
Upward Compression on Vocals? : r/audioengineering - Reddit, https://www.reddit.com/r/audioengineering/comments/1mc8c5q/upward_compression_on_vocals/
Audio Engineering in a Professional Podcast Post-Production: Tools: Phase, https://www.finchley.co.uk/finchley-learning/visual-podcast/audio-engineering-in-a-professional-podcast-post-production-tools-phase
Strategy for mixing tracks with lots of bleed? : r/audioengineering - Reddit, https://www.reddit.com/r/audioengineering/comments/8g22eo/strategy_for_mixing_tracks_with_lots_of_bleed/
Dugan Speech – Automixer for eMotion LV1 - Waves Audio, https://www.waves.com/mixers-racks/dugan-speech
Noise Gate vs Expander 101: Key Differences & Creative Tips - Unison Audio, https://unison.audio/noise-gate-vs-expander/
What is a noise gate? And what's an expander? - LEWITT Audio, https://www.lewitt-audio.com/blog/what-is-a-noise-gate-expander
Production Techniques Using Gates & Expanders, https://www.soundonsound.com/techniques/production-techniques-using-gates-expanders
Expander vs Noise Gate for Podcasting - Geeky Nerdy Techy, https://geekynerdytechy.com/expander-vs-noise-gate/
Advice on reducing mic bleed/spill for podcast with multiple people - Reddit, https://www.reddit.com/r/audioengineering/comments/ol5ywt/advice_on_reducing_mic_bleedspill_for_podcast/
The Basics of Room Tone in Audio Editing - iZotope, https://www.izotope.com/community/blog/basics-of-room-tone-audio-editing
Expanders. When do you use them? : r/audioengineering - Reddit, https://www.reddit.com/r/audioengineering/comments/4t4mjp/expanders_when_do_you_use_them/
View topic - Reducing Room Tone in Dialogue - Blackmagic Forum, https://forum.blackmagicdesign.com/viewtopic.php?t=106647&p=718435
When you are mixing with a downward expansion - Sound Design Stack Exchange, https://sound.stackexchange.com/questions/6844/when-you-are-mixing-with-a-downward-expansion
Dan Dugan Automixer - Waves Audio, https://www.waves.com/mixers-racks/dugan-automixer
Mic Bleed on a Podcast with 4 People : r/audioengineering - Reddit, https://www.reddit.com/r/audioengineering/comments/1qzg7cu/mic_bleed_on_a_podcast_with_4_people/
9 Best De-Esser Plugins (+ Mix Tips) - Pro Audio Files, https://theproaudiofiles.com/de-esser-plugins/
Best Ways to De-Ess in Samplitude - Boris FX, https://borisfx.com/blog/best-ways-to-de-ess-in-samplitude/
Do you guys like wide band or split band deessing more? : r/audioengineering - Reddit, https://www.reddit.com/r/audioengineering/comments/4d8a6n/do_you_guys_like_wide_band_or_split_band_deessing/
FabFilter Pro-DS Help - Advanced controls, https://www.fabfilter.com/help/pro-ds/using/advancedcontrols
What is a De-Esser? (Key Features And 7+ Best Techniques) - Unison Audio, https://unison.audio/what-is-a-de-esser/
Waves Vocal Rider - How is it Different to a Compressor? - SOS FORUM, https://www.soundonsound.com/forum/viewtopic.php?t=48616
Is Waves Vocal Rider Cheating? A Metal Mixer's Guide - Nail The Mix, https://www.nailthemix.com/waves-vocal-rider
Vocal Rider before or after EQ & Compression : r/audioengineering - Reddit, https://www.reddit.com/r/audioengineering/comments/oza2vj/vocal_rider_before_or_after_eq_compression/
What is a De-Esser (And How do I Use It for Vocals)? - Blog - Splice, https://splice.com/blog/what-is-a-de-esser/
The Loudness Lookup - LUFS Standards for Every Platform - Dan Murtagh, https://danmurtagh.com/lufs-loudness-standards/
RECOMMENDATION ITU-R BS.1770-3* - Algorithms to measure audio programme loudness and true-peak audio level, https://www.itu.int/dms_pubrec/itu-r/rec/bs/R-REC-BS.1770-3-201208-S!!PDF-E.pdf
Recommendation ITU-R BS.1770-5 (11/2023) Algorithms to measure audio programme loudness and true-peak audio level, https://www.itu.int/dms_pubrec/itu-r/rec/bs/R-REC-BS.1770-5-202311-I!!PDF-E.pdf
Learn More: Peak Metering - Audio Engineering Society, https://aes.org/resources/audio-topics/loudness-project/learn-more/
integratedLoudness - Measure integrated loudness and loudness range - MATLAB - MathWorks, https://www.mathworks.com/help/audio/ref/integratedloudness.html











