
The Foundations of Spoken-Word Post-Production and Audio Asset Management
Audio engineering in the post-production stage of professional podcasting is a highly technical, creative discipline that directly shapes narrative pacing, preserves listener retention, and establishes a brand's sonic identity1. Spoken-word dialogue possesses a unique cadence, complex dynamic variation, and distinct harmonic characteristics that require the same meticulous care and engineering precision as a lead vocal in a musical master1.
The primary objective of the mix is to serve as an acoustic bridge between raw field or studio recordings and the final consumer playback system1. This process is strictly dependent on the quality of the raw capture; post-production algorithms cannot synthesize high-fidelity information that was never originally captured1. When provided with high-quality source material, the mixing engineer's role is to construct a balanced spatial image, guarantee absolute vocal intelligibility, and ensure that the program translates consistently across a broad spectrum of playback hardware—ranging from high-end studio monitors to low-grade smartphone speakers1.
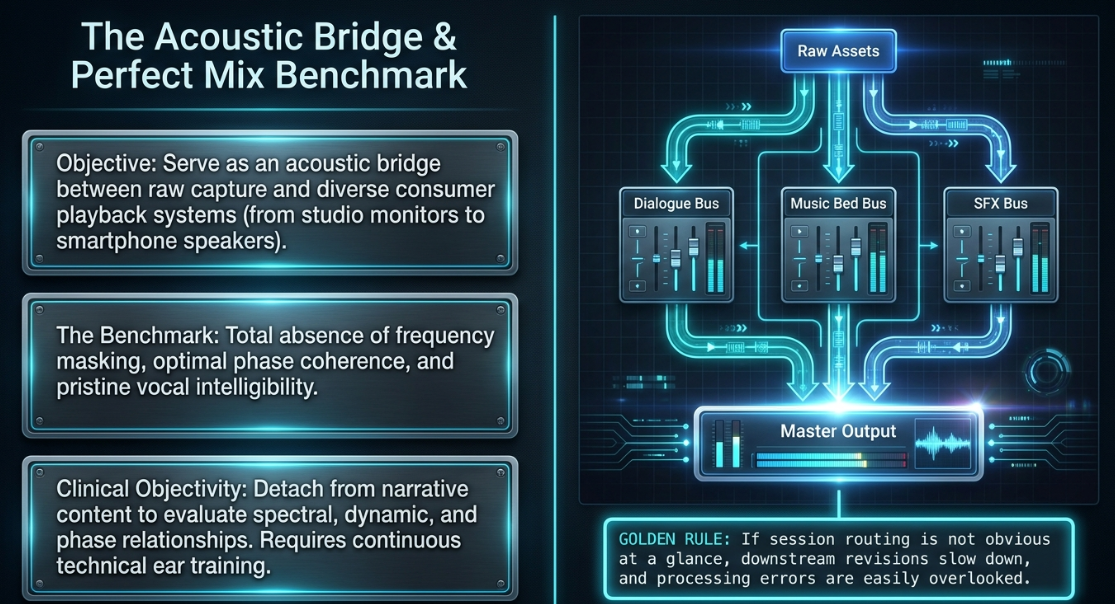
The concept of a perfect mix serves as a theoretical benchmark driving the engineering workflow1. In this ideal state, the engineer balances structural precision, such as the total absence of frequency masking and optimal phase coherence, with the narrative's emotional resonance1. Achieving this requires the engineer to maintain clinical objectivity, detaching from the narrative content to evaluate the program purely in terms of its spectral, dynamic, and phase relationships1. Post-production houses implement systematic technical ear training, involving daily frequency identification, compression artifact detection, and stereo image evaluation, to maintain the baseline acuity required for these decisions1.
The baseline structure of a podcast episode is defined by its arrangement and the organization of its assets1. In post-production, the arrangement regulates the overall narrative flow, dictating the placement of speech, advertisements, musical stingers, and ambient soundscapes1. A dense arrangement containing layered music and sound effects requires aggressive frequency sculpting to prevent masking, whereas a sparse arrangement (e.g., a single voice) exposes microscopic recording flaws, demanding pristine noise reduction1.
To manage this complexity, engineers establish clean asset organization at the outset of the session, naming tracks clearly and structuring them within logical folders2. Session files utilize specific bussing routes to group dialogue tracks, music beds, and effects3. This structural clarity is governed by a strict operational rule: if the session routing is not obvious at a glance, downstream revisions slow down, and processing errors are easily overlooked3. Throughout editing, the engineer maintains detailed session notes to track pronunciation fixes, retakes, and sections requiring manual gain automation, ensuring that revisions can be executed efficiently3.
Spectral Analysis and Equalization Methodologies
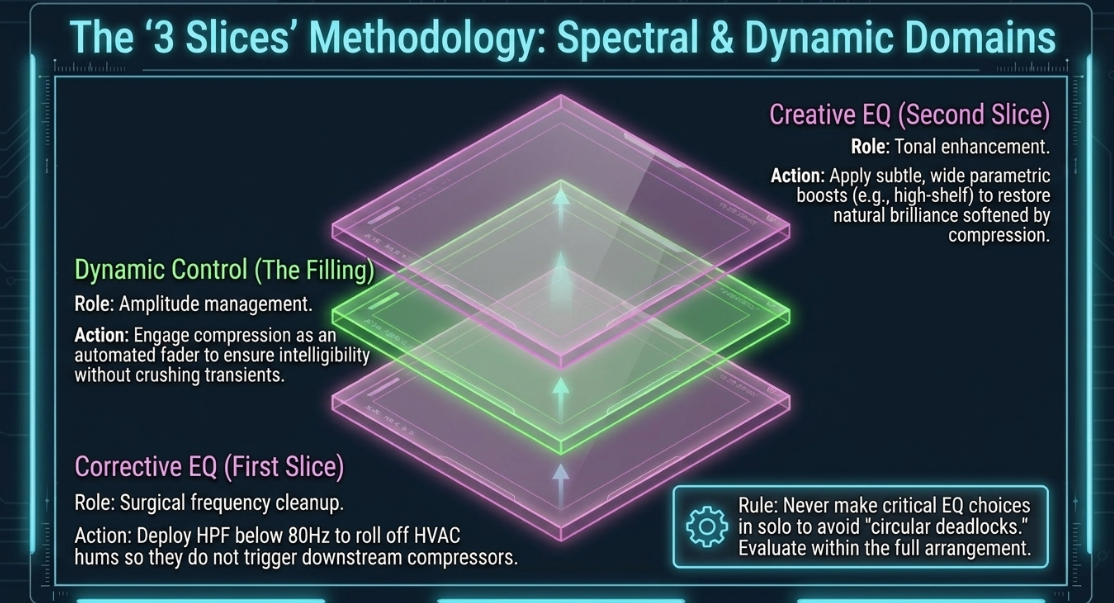
To establish clarity and separation between the dialogue and auxiliary elements, engineers approach equalization (EQ) and dynamics control as a series of sequential, highly targeted processes2. A common industry practice involves dividing the vocal processing chain into three stages: Corrective EQ (the first slice), Dynamic Control (the filling), and Creative EQ (the second slice)4.
The first slice, or corrective stage, is dedicated to surgical frequency cleanup4. Making critical EQ choices while a track is soloed is a primary contributor to counter-productive, endless adjustment loops, often referred to as "circular deadlocks"1. For example, stripping a vocal of low-mid frequencies might make it sound clean in isolation, but brittle and detached when blended back into a music bed1. Therefore, engineers execute critical equalization decisions while listening to the entire arrangement in context1.
During the corrective phase, high-pass filters (HPF) are used to roll off low-frequency rumble, physical microphone handling noise, and explosive plosive energy below , where human speech carries no useful fundamental frequencies5. Because the human auditory system rapidly habituates to specific frequencies, prolonged exposure to harsh resonances can cause the brain to temporarily filter them out, resulting in inaccurate mixing choices1. To avoid this, engineers schedule regular listening breaks to reset their baseline auditory sensitivity1.
Once the corrective stage has established a clean, balanced signal, the voice can be safely compressed without triggering the dynamics processor with unwanted low-end energy4. After compression, the engineer applies the second slice, or creative EQ stage, using subtle, wide parametric boosts to enhance the natural character, brilliance, and presence of the voice4.
Dynamic Range Control, Compression Topologies, and Parallel Architectures
Dynamic range compression is an audio signal processing technique designed to narrow the span between the highest and lowest amplitude levels of an audio signal, creating a consistent perceived loudness profile2. Historically, dynamic range compression arose to overcome the physical limitations of analog recording media, such as magnetic tape and vinyl, which could accommodate only a restricted dynamic range () compared to the wide dynamic swings of natural acoustic sources ()10. In spoken-word post-production, compression ensures that vocal levels remain intelligible above the background noise floor across a variety of noisy consumer environments, such as cars, subways, or busy streets6.

A common misconception is that compressors turn quiet passages up12. In practice, a compressor acts as a fast, automated volume fader that turns loud sounds down4. The core parameters that govern this behavior include:
Threshold: The specific decibel level at which gain reduction is triggered1. Signals below this level remain unaffected1.
Ratio: The amount of gain reduction applied once the signal exceeds the threshold1. A ratio of means that for every the input signal exceeds the threshold, only is allowed to pass to the output1.
Attack: The speed at which the compressor clamps down on the signal after the threshold is crossed1. Fast attack times () quickly catch sharp transient peaks, while slower times allow the natural consonant dynamics to pass through before engaging4.
Release: The speed at which the compressor stops reducing gain after the signal falls back below the threshold1. Fast release times can introduce distortion or a pumping effect, while slow release times () create a smoother, more transparent transition4.
Makeup Gain: Static amplification applied to the output signal to restore the overall level lost during the gain reduction process, which ultimately makes quiet passages sound louder relative to the attenuated peaks1.
Over-compressing the full mix can cause rapid listener fatigue and pump up background noise3. Additionally, applying a single preset across all speakers is highly problematic because variations in microphones, room acoustics, and speaking styles require customized dynamic handling3. Chasing final loudness too early in the chain is another common error; if the underlying dynamics are unbalanced, pushing the gain into a master limiter will only magnify those flaws3.
To address these challenges, engineers use parallel compression (sometimes called New York compression) to build density while preserving transient impact3. This technique splits the vocal signal into two paths3. The first path remains unprocessed and highly dynamic, preserving the natural articulation of the speaker3. The second path is routed to an auxiliary bus and heavily compressed using a high ratio (e.g., or higher) and a fast attack to flatten the peaks and exaggerate the low-level tail of the speech3.
When the heavily compressed signal is blended back into the original mix at a lower level, it fills in the quiet gaps and adds weight and sustain to the performance without crushing the natural transient peaks of the primary track3. Because compression is a non-linear process, the sum of a signal compressed on a parallel path and blended back behaves differently than a single signal run through a standard compressor, offering a transparent, dense vocal sound15.
Technical Execution of Advanced Automation
While dynamic processors handle rapid volume variations, manual volume automation remains essential for managing structural level shifts, preserving natural vocal expression, and maintaining a cohesive narrative structure1.
Relying solely on heavy compression to level a performance can suck the life out of the voice and make it sound over-processed3. To maintain transparent control, engineers use manual volume rides after the compression stage to balance words or phrases that still poke out of the mix or get buried under music beds3.
Modern DAWs provide four standard automation modes to capture and refine these adjustments1. Touch mode is used to surgically write over brief, transient anomalies, such as ducking a loud breath or a cough, because it instantly reverts to the pre-existing envelope upon release1. Latch mode is used for broad, macro-level adjustments across entire paragraphs or scenes1. Write mode is reserved for initial setup sweeps due to its destructive nature, and Read mode is engaged during the final mixdown to play back written data without risk of alteration1.
This technical control is also key to managing the interaction between dialogue and music beds3. When voice-overs play over music, the music must maintain its energy while staying clear of the vocal spectrum3. Using manual volume automation, the engineer ducks the music bed by when speech is active, allowing the dialogue to sit cleanly on top4.
Alternatively, this process can be automated using sidechain compression, where a compressor placed on the music bed is keyed to the vocal track4. Whenever the speaker talks, the vocal signal triggers the compressor on the music bus, automatically carving out a temporal and spectral pocket for the voice4.

Signal Isolation, Multi-Microphone Bleed, and Phase Mechanics
When recording multiple hosts or guests in the same room, a major challenge is signal leakage, or "bleed," where Host A's voice is captured by Host B's microphone17. This leakage introduces phase alignment issues and acoustic comb filtering when the microphones are summed to a mono bus17.
The Phase Relationship and Comb Filtering
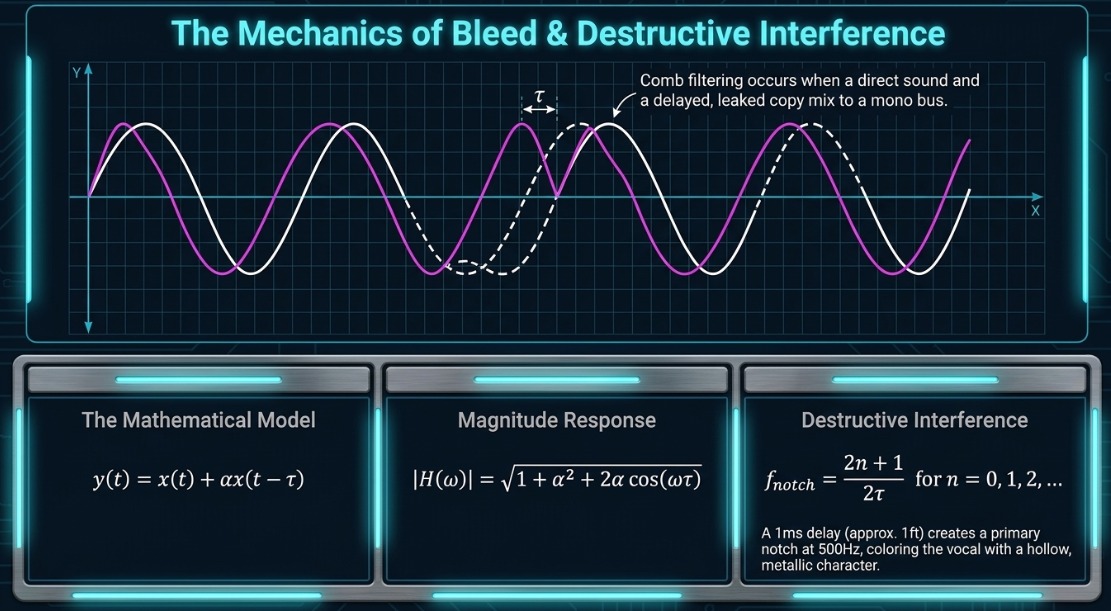
Acoustic comb filtering occurs when a direct sound and a delayed, leaked copy of that same sound are mixed together17. Because sound travels through air at a finite speed of approximately in a standard room (), physical separation between microphones introduces a time delay17. When Host A speaks, their voice reaches their primary microphone almost instantly17. However, that same sound wave must travel across the room to Host B's microphone, arriving several milliseconds later17.
This process can be modeled mathematically as a continuous feedforward comb filter21:
[cite: 21, 24]
Where:
is the summed output signal21.
is the direct, primary vocal signal21.
is the gain scaling factor representing the attenuation of the leaked signal at the secondary microphone ()21.
is the physical propagation delay in seconds21.
Applying the Fourier transform to determine the frequency response yields:
[cite: 21, 24]
The magnitude response is given by:
[cite: 21, 24]
When the direct and leaked signals are summed at equal amplitude (), complete phase cancellation occurs at frequencies where the signals are out of phase21. These destructive cancellation points, or notches, occur at odd multiples of the delay frequency21:
[cite: 21, 25]
For example, if the physical distance between microphones introduces a delay of , the primary cancellation notch occurs at:
[cite: 25]
Subsequent notches occur at , , and 25. If the delay is increased to (a physical separation of about ), the primary notch drops to 25. This periodic patterning of boosts and cuts severely colors the vocal, giving it a hollow, thin, or metallic character18.
The Host-Guest Gain Dilemma
A common example of comb filtering occurs during host-guest panel shows17. If a soft-spoken guest is interviewed by a loud host, the engineer must boost the preamp gain on the guest's microphone to capture their voice17.
Because the host is speaking loudly, their voice bleeds into the guest's boosted microphone at a high level17. When both channels are active, the host's voice is summed from two separate physical locations, resulting in noticeable comb filtering and muddy phase cancellation on the host's primary dialogue17.
Mechanical Mitigation and Placement Rules
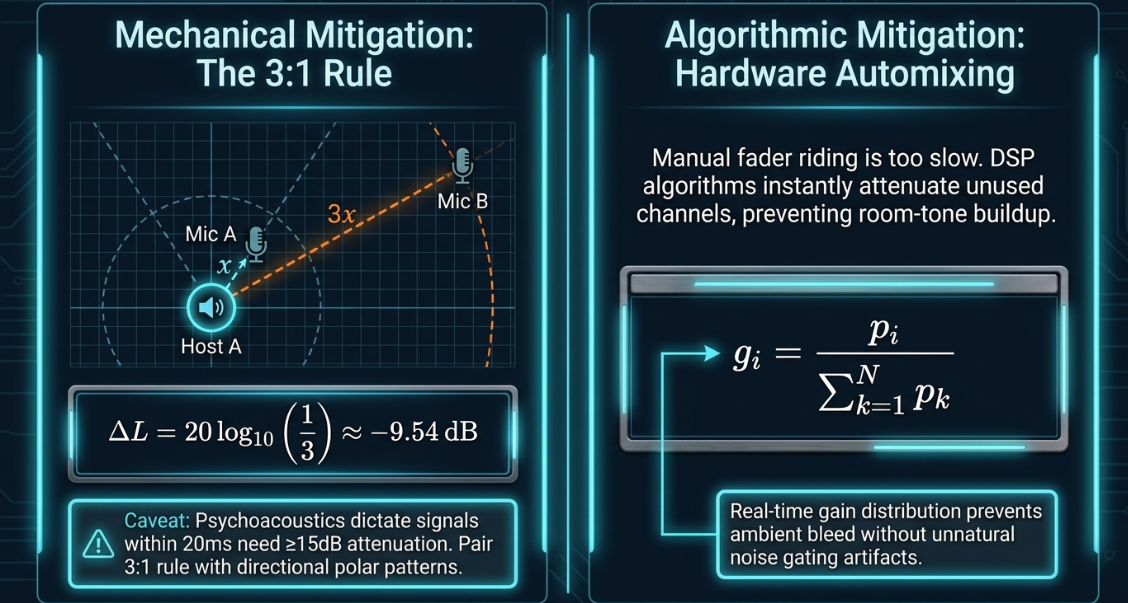
To minimize comb filtering during the recording phase, engineers rely on physical distance and polar patterns17. The 3:1 rule of microphone placement states that the distance between any secondary microphone and a sound source must be at least three times the distance from that source to its primary microphone17.
This rule is rooted in the inverse square law of acoustics: as sound propagates in a free field, its intensity drops by with every doubling of distance17. Tripling the distance provides a natural acoustic attenuation of approximately at the secondary capsule17:
[cite: 17]
While a reduction is a helpful baseline, psychoacoustic studies show that delayed signals arriving within the first must be attenuated by at least to make comb filtering completely inaudible17. Therefore, engineers pair the 3:1 rule with highly directional cardioid, supercardioid, or hypercardioid microphones17.
Cardioid capsules reject sound coming directly from the rear ( off-axis), while supercardioid and hypercardioid patterns offer rejection nulls along the rear-diagonal angles, allowing engineers to angle the microphones to block bleed from adjacent speakers28.
If microphones must be arranged in an equidistant lineup, the theoretical distance factor must be increased to a ratio to maintain adequate isolation17. In tight spaces where physical separation is not possible, engineers use acoustic barriers, gobos, or clean wool blankets to block off-axis bleed19.
Additionally, engineers ensure that the microphones share a clean, uniform off-axis response28. If a microphone has poor off-axis response, the bleed will sound colored and muddy, making it much harder to clean up in post-production28.
Hardware Automixing and Signal Routing
In multi-microphone setups where physical isolation is limited, manual fader riding is often too slow to prevent phase build-ups18. Engineers resolve this using hardware-based automatic mixers, such as the Dan Dugan gain-sharing automixer or the proprietary MixAssist algorithm18.
These processors are integrated into professional field recorders like the Sound Devices Scorpio, 888, and 833, which feature high-end Class-A differential preamps, FPGA-based processing, and multi-media simultaneous recording30.
The Dan Dugan algorithm automatically distributes gain across all open channels in real time18. The gain allocated to any active channel is calculated using the following gain-sharing formula:
Where is the measured input power of channel , and is the total number of open microphones in the system.
This formula ensures that the total system gain remains equal to (representing a single open microphone), regardless of how many hosts are speaking18. When Host A speaks, their input power dominates the denominator, and the algorithm routes full gain to Mic A while instantly attenuating Mic B18.
By attenuating unused channels, this system prevents comb filtering, eliminates ambient room-tone buildup, and avoids the unnatural gating artifacts typical of standard noise gates18.
Surgical Spectral Restoration and De-Reverberation Mechanics
When raw podcast assets are recorded in untreated environments, they often suffer from background noise, digital clipping, or excessive room reverb35. Cleaning these files requires surgical spectral editing and advanced restoration tools35.
Audio Restoration Software Platforms
Post-production suites offer different strengths for editing and repairing voice assets36. Choosing the right tool depends on whether the task requires broad multitrack assembly or surgical, sample-level repair36.
Visual Spectral Editing Techniques
Unlike standard time-domain waveform editors, spectral editing allows engineers to visualize and manipulate audio in the frequency domain36. To locate subtle acoustic issues, engineers customize the visual settings of the spectrogram42:
Spectrogram Color Maps: While standard "Cyan to Orange" maps are useful for general editing, engineers switch to high-contrast "Multicolor" maps to locate faint, low-frequency hums or resonances that would otherwise blend into the noise floor42.
Spectrogram Algorithms: Moving from the standard "Auto-adjustable STFT" (Short-Time Fourier Transform) algorithm to an "Adaptively Sparse" calculation increases the visual resolution of the spectrogram42. This high-resolution display separates closely spaced harmonics, allowing the engineer to perform more surgical edits42.
For example, to remove a sharp whistle from a recording, the engineer can use the spectrogram's "Magic Wand" tool to select the fundamental frequency of the whistle43. A second click with the tool automatically identifies and selects all corresponding upper harmonics43.
By applying "Replace" mode, the software attenuates those specific frequencies and interpolates the missing data using the surrounding clean audio, removing the whistle without affecting the speaker's voice35.
For general vocal cleanup, engineers follow a specific, logical processing order to prevent plugins from interfering with one another39:
[Raw Audio Input] ---> [De-clip] ---> [De-click] ---> [De-ess / De-plosive] ---> [Vocal / Spectral De-noise] ---> [Clean Vocal Output]
This sequence is highly efficient39. De-clipping is placed first to restore squared-off transient peaks before they enter downstream filters36.
De-clicking removes short digital and mouth clicks, which helps de-essers and de-plosives focus on vocal consonants9.
Vocal or spectral de-noising is placed last to clean up the remaining steady state noise floor after the transients have been addressed39.
Reverb Removal and De-Reverberation Mechanics
Unwanted room reverb is a common issue in home or field recordings37. This reverberation is composed of early reflections (arriving within ) and the late diffuse decay tail (arriving after )23. Early reflections are highly coherent and help the listener perceive the physical boundaries and size of the room23. The late tail consists of dense, overlapping reflections that decay exponentially, often muddying the vocal and reducing speech clarity23.
To remove this reverb, algorithms must handle these two components differently46. While the late diffuse tail can be attenuated using multi-band expansion or gate-like processors, early reflections are tightly integrated with the direct signal and are much harder to remove without introducing phase artifacts23.
Advanced de-reverb plugins, such as Accentize DeRoom Pro2 or Waves Clarity Vx DeReverb Pro, use trained neural networks to continuously estimate the room size and decay curve, applying precise multi-band gain reduction to target the reverb46.
Because these algorithms can sometimes strip away high-frequency harmonics and leave the vocal sounding dull, engineers use "Spectral Focus" modes to limit processing to the most problematic low-mid bands46.
They also employ "Tail Smoothing" options to allow a natural decay, ensuring the processed dialogue doesn't sound unnaturally dry or disconnected from its environmental context46.
Dynamic Equalization vs. Multiband Compression
Managing frequency-dependent dynamics is a key part of professional podcast post-production12. While both dynamic equalizers and multiband compressors apply level changes to specific frequency bands, their underlying designs and acoustic behaviors are quite different41.
Architectural Differences and Phase Behavior
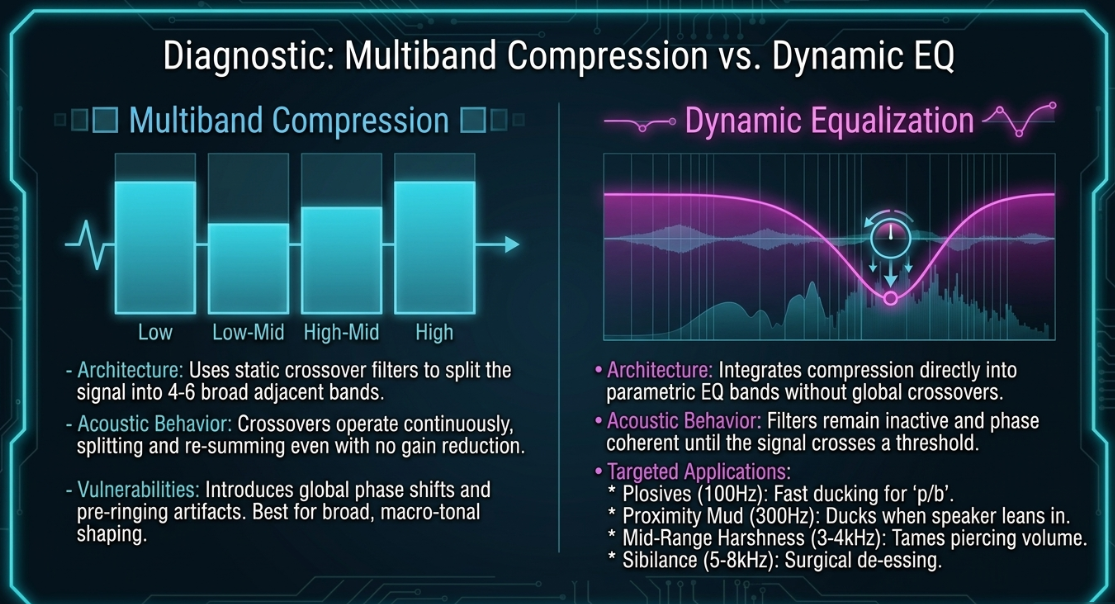
A multiband compressor uses static crossover filters to split the incoming audio into broad, adjacent frequency bands12. Each band has its own independent compressor with standard controls (Threshold, Ratio, Attack, Release)12.
This crossover network operates continuously, meaning the signal is split and re-summed even when no gain reduction is occurring14. This continuous filtering can introduce phase shifts and pre-ringing artifacts, which can color the sound and affect the transient clarity of the voice14.
A dynamic equalizer, by contrast, integrates the dynamic controls of a compressor directly into a standard parametric EQ band48. It does not use global crossover filters48.
Instead, the EQ filter remains inactive until the signal in that specific frequency band crosses a user-defined threshold48. This design avoids global phase shifts, engaging the filter and altering the phase response only when active14.
Furthermore, dynamic equalizers give engineers fine control over the filter shape (Q value), allowing them to target narrow, surgical bands, whereas multiband compressors are better suited for broader, macro-tonal adjustments41.
Target Vocal Frequencies for Dynamic EQ
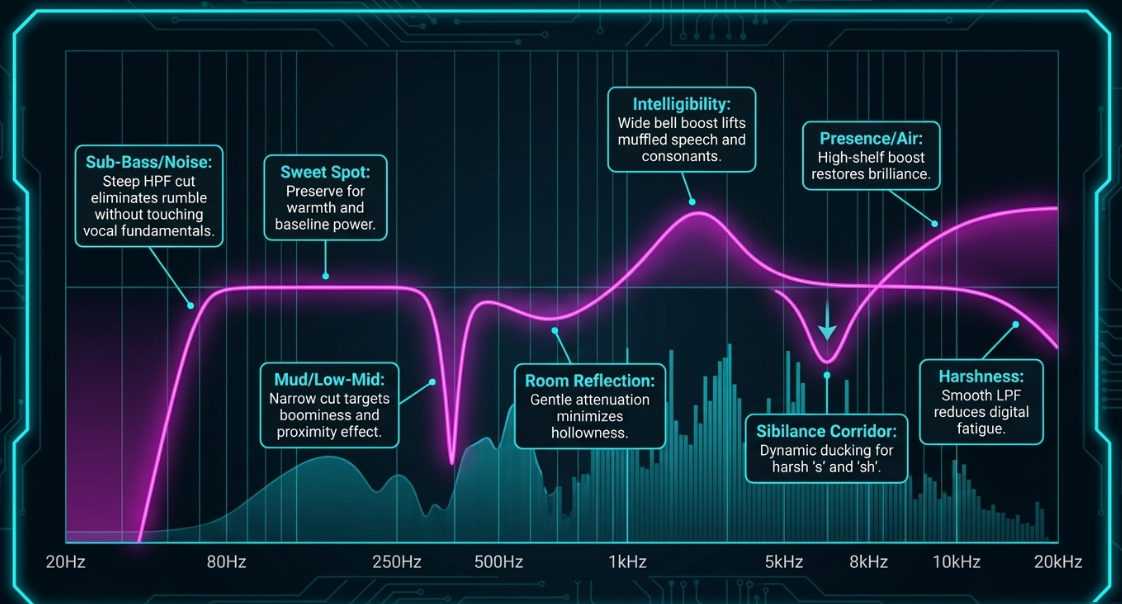
Vocal dynamics change continuously as a speaker transitions between different registers and syllables1. Static EQ cuts apply a permanent reduction that can leave the voice sounding thin during quieter passages16. Dynamic EQ, on the other hand, responds in real time to target issues only when they occur16.
Vocal Plosives (): When a speaker hits an offensive "p" or "b" consonant, a static cut at would thin out the natural warmth of the voice16. Placing a dynamic EQ band centered at with a fast attack allows the filter to duck only during the plosive blast, preserving the vocal's body during normal speech16.
Vocal Mud (): Low-mid muddy build-ups often occur on specific words or when the speaker leans closer to the microphone (proximity effect)16. A dynamic cut of in this range cleans up the mud without thinning out the voice16.
Mid-Range Harshness (): When a speaker becomes animated or loud, their voice can sound piercing around 16. A dynamic band centered at tames this harshness during loud passages while keeping the vocal clear during quieter moments16.
Sibilance (): To control sibilance, a dynamic EQ band can be set between 47. The threshold is set so that only the loudest "s" and "t" sounds trigger the cut, maintaining vocal brightness without creating a lisp12.
Spatial Staging, Binaural Soundscapes, and Atmos Workflows
With the growth of narrative fiction podcasts, audio dramas, and high-end documentaries, engineers are increasingly using immersive and spatial audio to build three-dimensional soundscapes50.
Designing Immersive Narrative Soundscapes
In narrative podcasting, spatial sound design acts as a storytelling tool53. By placing sound effects and ambiences in a 3D field, engineers can convey physical space—such as characters walking behind the listener, whispers from one side, or characters approaching from a distance—directly through the audio55. This "writing for the ears" approach allows the mix to establish the size and acoustic signature of an environment, reducing the need for descriptive narrator dialogue54.
However, engineers must manage the density of these elements carefully6. Overloading the mix with constant spatial movement can distract the listener and clutter the story6.
Binaural Audio vs. Immersive Formats
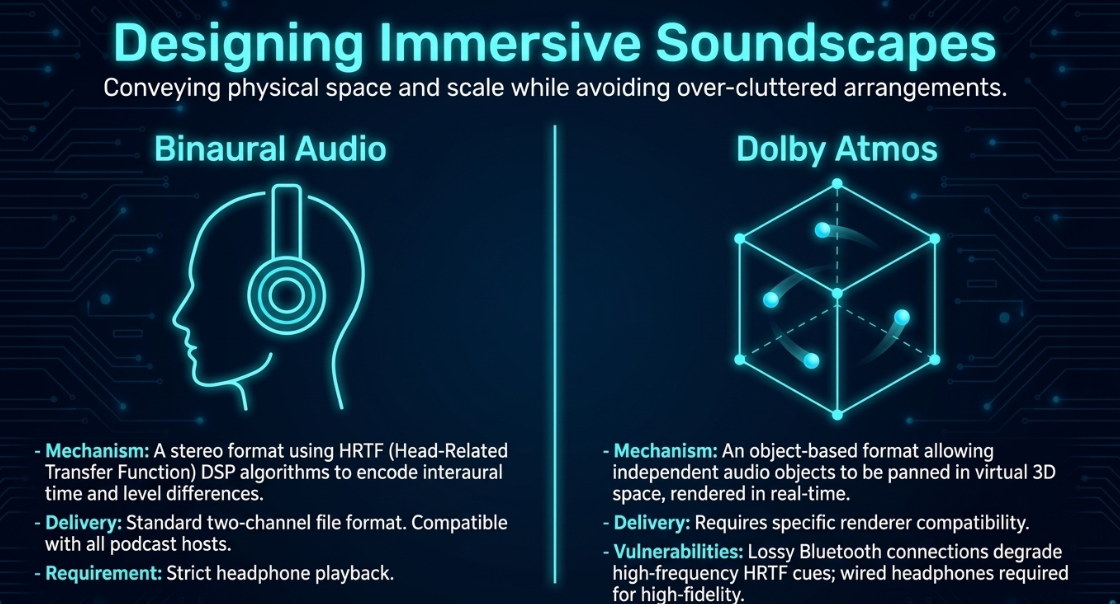
To deliver these spatial mixes to consumers, engineers use binaural processing or multi-channel immersive formats56.
Binaural Audio: A stereo format designed specifically for headphone listening53. It uses HRTF DSP algorithms to encode interaural time and level differences into a standard two-channel file, which can be hosted on all standard podcast platforms52.
Dolby Atmos: An object-based format that supports discrete speaker arrays (e.g., home theaters and soundbars) as well as binaural headphone rendering56. Dolby Atmos allows engineers to pan independent audio "objects" anywhere in a virtual 3D space, with the playback engine rendering the positions in real time based on the listener's hardware50.
While Dolby Atmos offers a wide canvas, a major delivery challenge is consumer headphone hardware55. While modern web browsers and streaming apps support Atmos, some platforms restrict spatial rendering over standard PC connections, forcing listeners to use mobile devices55.
Furthermore, lossy Bluetooth connections can degrade the delicate high-frequency HRTF filtering cues needed for precise spatial localization, making wired headphones the ideal choice for experiencing high-fidelity spatial mixes55.
Dolby Atmos Post-Production Workflows
In Dolby Atmos podcasting, Pro Tools is the primary workstation used for spatial mixing and routing51. For smaller post-production rooms, a monitoring layout—which adds four overhead height speakers to a standard surround setup—provides a reliable environment for tracking bed and object panning56.
[Front Left] [Front Center] [Front Right]
O O O
[Height FL] O O [Height FR]
[Surround Left] O [Listener] O [Surround Right]
[Height RL] O O [Height RR]
O O
[Rear Left] [Rear Right]
When staging a spatial podcast, engineers follow strict placement guidelines to preserve narrative clarity58:
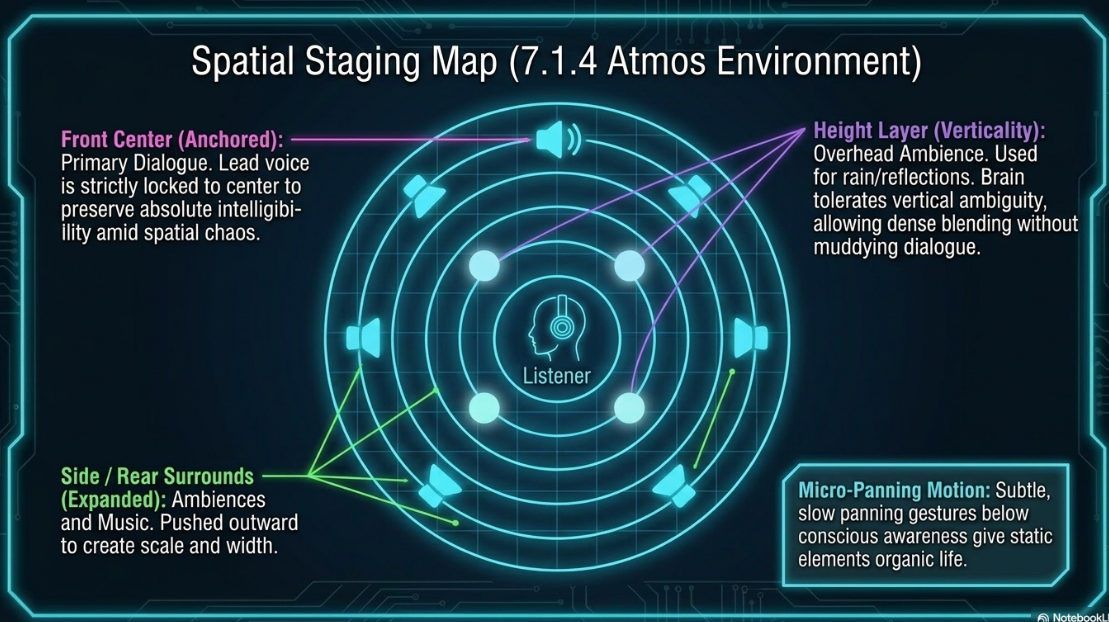
Primary Dialogue: The lead voice is always anchored in the Front Center channel of the Dolby Atmos bed58. Keeping the dialogue centered ensures that speech remains clear and intelligible, even when complex sound effects are panning around the listener58.
Ambiences and Music: Background vocals, sound effects, and musical elements are panned to the side and rear channels to create a sense of scale58.
The Height Layer: The height channels are used to pan vertical effects, such as rain, thunder, or overhead reflections58. Because the human brain is tolerant of localization ambiguity in the vertical plane, engineers can blend ambient elements into the height layer to expand the sense of space without muddying the main dialogue58.
Micro-Panning Motion: To make static elements sound more natural, engineers apply subtle, slow panning gestures that operate below conscious awareness, giving the sound a sense of life and realism within the virtual space58.
Global Loudness Standards, Gating, and Compliance Metrics
To ensure a smooth transition between different shows, advertisements, and platforms, post-production engineers must master to strict, internationally recognized loudness standards59.
Level vs. Perceived Loudness
Historically, audio levels were monitored using peak, PPM, or VU meters, which measure instantaneous electrical voltage61. However, these meters do not reflect how the human ear perceives volume7. Perceived loudness is determined by the signal's energy over time and its frequency balance7.
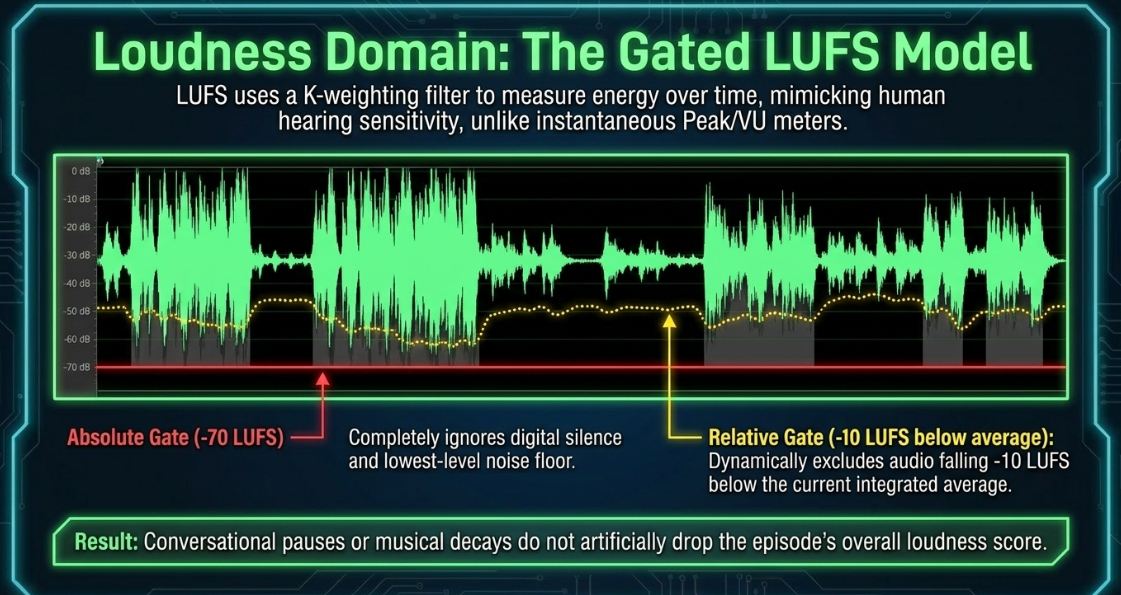
To measure this accurately, engineers use LUFS (Loudness Units relative to Full Scale), which applies a K-weighting filter to mimic human hearing sensitivity7.
To calculate the integrated LUFS of an entire episode, loudness meters use two gating thresholds to prevent quiet pauses from skewing the reading62:
Absolute Gate: Set at , this gate completely ignores digital silence or low-level background noise62.
Relative Gate: Set below the current integrated value62. If the integrated level of the program is , any passages that fall below are excluded from the calculation, ensuring that normal conversational pauses or musical decays do not artificially lower the overall reading62.
Dynamic Profiling Metrics
To analyze the overall dynamic structure of a master, engineers use two key metrics:
Peak-to-Loudness Ratio (PLR): Calculated as the maximum True Peak minus the Integrated Loudness ()64. PLR measures the long-term, average dynamics of the program64. A PLR of represents an open, highly dynamic master, while values below indicate heavy limiting and over-processing64.
Peak-to-Short-Term Ratio (PSR): Calculated as the maximum True Peak minus the maximum Short-Term Loudness measured over a sliding 3-second window7. PSR is used to monitor short-term dynamics and track whether transient impact is being preserved throughout the episode64.
Platform Normalization Profiles and Lossy Encoders
If an episode is uploaded at a level louder than a platform's target, the streaming service's algorithm will automatically turn the file down to prevent sudden volume spikes for the user7. On YouTube, if a master is uploaded quieter than the target, the platform will not apply positive gain, leaving the file sounding quiet and thin compared to other content7. On Spotify, quiet files are boosted using positive gain, but if the file lacks sufficient headroom, a limiter is engaged, which can introduce distortion7.
Furthermore, when files are transcoded into lossy formats (such as AAC or MP3), the reconstruction process can cause peak levels to rise by up to 7. If a master is pushed too close to , this transcoding process will introduce digital clipping62.
To avoid this, standard recommendations such as AES TD1008 and TD-1004 advise mastering dialogue-heavy podcasts to with a True Peak limit of to provide adequate safety headroom60.
Additionally, engineers must manage the level of advertisements carefully59. If ads are mixed louder than the main show, listeners will experience a jarring volume jump, often leading to immediate tune-out59.
To maintain a consistent level, engineers use real-time leveling tools, such as the APU Loudness Leveler, which applies transparent adjustments when the program drifts from the target67. These levelers feature a Tail Guard mode, which pauses gain correction during natural pauses or quiet endings, preventing the processor from unnaturally boosting breaths or background noise67.
In professional workflows, engineers often create two separate masters61. The primary master is calibrated to to preserve the stereo image and transient clarity61. A secondary, louder master is created at solely for artist review, allowing the client to compare the work against heavily limited reference files without compromising the quality of the final broadcast deliverable61.

Global Streaming and Broadcast Loudness Standards
To ensure compliance across all major distribution platforms, engineers reference the following standardized targets:
Strategic Conclusions and Operational Recommendations
To deliver high-quality, professional podcast audio that translates cleanly across modern playback systems, post-production workflows should adopt the following operational standards:
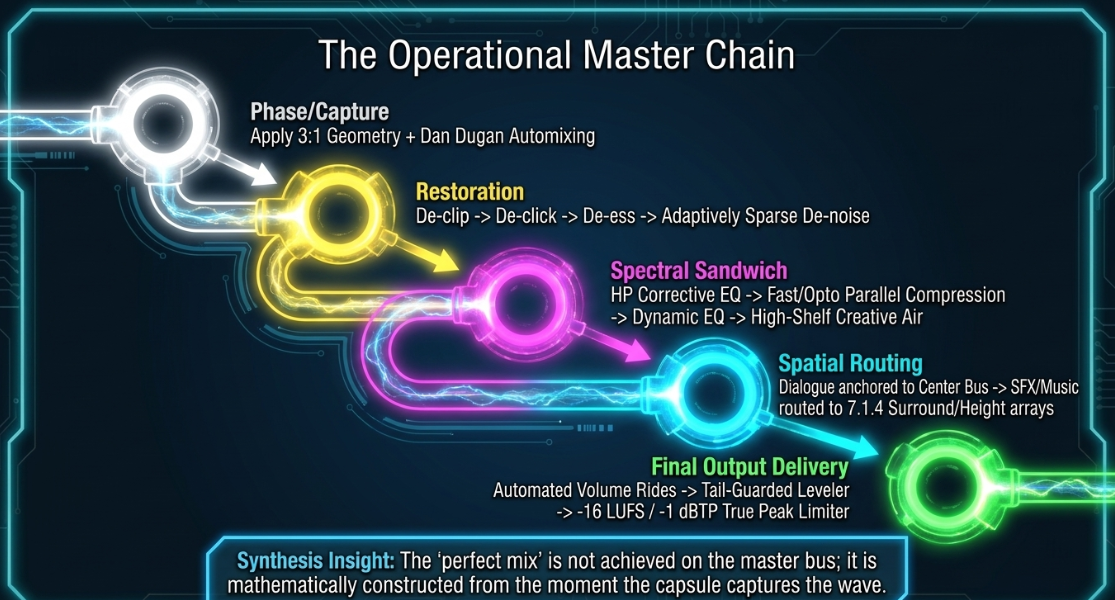
Establish Clear Session Routing: Design clean, standardized routing paths at the start of every session, grouping dialogue, music, and sound effects onto dedicated buses3. Use structured file naming and detailed session notes to track edits and speed up client revisions2.
Apply the 3:1 Rule and Automixing for Multi-Mic Sessions: Position microphones to maintain a distance ratio to minimize comb filtering and phase cancellation17. For multi-mic conversational panels, use gain-sharing automixers like Dugan Automixing or MixAssist to isolate active speakers and eliminate ambient room-tone buildup18.
Use Serial Dynamics and Dynamic EQ: Level vocal dynamics using manual clip gain first, followed by a fast compressor to tame initial transient peaks, and a gentle opto compressor to add density4. Use dynamic EQ instead of static cuts to surgically address momentary issues—such as plosives at or mud at —without thinning out the natural character of the voice16.
Optimize Spatial Staging: Keep primary dialogue locked in the Front Center channel to preserve narrative focus and clarity58. Pan music, sound effects, and ambiences to the surround and height layers to build a spacious, immersive environment, checking mono compatibility regularly to ensure the mix translates to single-speaker devices1.
Target -16 LUFS / -1 dBTP for Final Masters: Master standard stereo episodes to with a True Peak limit of 1. This baseline provides a safe, dynamic master that complies with Apple's standards and translates cleanly when scaled up by platforms with louder targets1.
Works cited
Audio Engineering in a Professional Podcast Post-Production - Finchley Studios, https://www.finchley.co.uk/finchley-learning/visual-podcast/audio-engineering-in-a-professional-podcast-post-production
Mastering Podcast Editing and Post-Production: Your Ultimate Guide - Podigy, https://www.podigy.co/mastering_podcast_editing_and_post-production_your_ultimate_guide
Audio Mixing Techniques for Pro-Level Podcasts & Video, https://flexworkstudios.com/audio-mixing-techniques/
EQ vs Compression When to Use A Definitive Mixing Guide - SFX Engine, https://sfxengine.com/blog/eq-vs-compression-when-to-use
Tips for Mixing and Mastering Your Podcast | B&H eXplora, https://www.bhphotovideo.com/explora/pro-audio/tips-and-solutions/mixing-mastering-podcast
Ultimate Guide to Podcast Production (Part 2) - iZotope, https://www.izotope.com/community/blog/podcast-production-guide-part2
The Loudness Lookup - LUFS Standards for Every Platform - Dan Murtagh, https://danmurtagh.com/lufs-loudness-standards/
What Is De-Essing and How to Use a De-Esser on Vocals | AutoTune, https://www.antarestech.com/community/what-is-a-de-esser-how-it-works-and-how-to-use-one-on-vocals
What is de-essing? The dos and don'ts of using a de-esser - iZotope, https://www.izotope.com/community/blog/the-dos-and-donts-of-de-essing
Dynamic range compression - Grokipedia, https://grokipedia.com/page/Dynamic_range_compression
Dynamic Range Compression in Audio - Medium, https://medium.com/@girirabi/dynamic-range-compression-in-audio-4e1cd14282a5
Multiband, De-Esser, Dynamic EQ, and Sidechain | Beat Kitchen, https://beatkitchen.io/guides/mix-primer/20-multiband-deesser-sidechain/
The Ultimate Guide to Compression | Black Ghost Audio, https://www.blackghostaudio.com/blog/the-ultimate-guide-to-compression
A Simple Rule for When to Use a Dynamic vs a Static EQ. | PerforModule, https://performodule.com/2019/05/24/when-to-use-a-dynamic-vs-a-static-eq/
"Parallel compression is just... compression" : r/audioengineering - Reddit, https://www.reddit.com/r/audioengineering/comments/1azvz4i/parallel_compression_is_just_compression/
How to Use Dynamic EQ on Vocals - 5 Useful Tips - Music Guy Mixing, https://www.musicguymixing.com/dynamic-eq-vocals/
The basics about comb filtering (and how to avoid it) - DPA Microphones, https://www.dpamicrophones.com/mic-university/audio-production/the-basics-about-comb-filtering-and-how-to-avoid-it/
What is Comb Filtering and how to avoid it - Blog | Resources - Q-SYS, https://blogs.qsc.com/live-sound/what-is-comb-filtering-and-how-to-avoid-it/
Working With Mic Bleed - Sound On Sound, https://www.soundonsound.com/techniques/working-mic-bleed
Comb Filtering: Causes, Avoidance, and Creative Uses - MasteringBOX, https://www.masteringbox.com/learn/comb-filtering
Comb filter - Wikipedia, https://en.wikipedia.org/wiki/Comb_filter
Effects Processing - Modulated delay - PastPaperHero, https://www.pastpaperhero.com/resources/edexcel-a-level-music-technology-9mt0-effects-processing-modulated-delay
Reverb: components and considerations - sonible, https://www.sonible.com/blog/reverb-components-considerations/
IIR Notch and Comb Filter Analysis | PDF - Scribd, https://www.scribd.com/document/201903488/IIR-Filter-Design-and-Analysis-using-Notch-and-Comb-Filter
Calculating the amount of delay to create phasing for depth in the mix according to comb filtering : r/AdvancedProduction - Reddit, https://www.reddit.com/r/AdvancedProduction/comments/18qv22y/calculating_the_amount_of_delay_to_create_phasing/
What Is The 3-To-1 Rule For Audio? - BGR, https://www.bgr.com/2201044/3-to-1-audio-rule-explained/
Master Handbook of Acoustics - Amazon S3, https://s3.amazonaws.com/arena-attachments/559608/dd2eece63c4d53a0d1175925afdf17c4.pdf
How To Avoid Mic Bleed - Bax Music, https://www.bax-shop.co.uk/blog/studio-recording/how-to-avoid-mic-bleed/
De-essing - Wikipedia, https://en.wikipedia.org/wiki/De-essing
Sound Devices Scorpio Mixer Recorder - Studiocare, https://studiocare.com/products/sound-devices-scorpio-mixer-recorder
Sound Devices 888 - Trew Audio, https://www.trewaudio.com/product/sound-devices-888/
Scorpio - Sound Devices, https://www.sounddevices.com/product/scorpio/
Sound Devices 888 Mixer-Recorder - CVP.com, https://cvp.com/product/sound-devices-888-mixer-recorder
833 - Portable Compact Mixer-Recorder - Mediatrade, https://mediatrade.fi/en/product/833-portable-compact-mixer-recorder/
Industry-standard audio repair and post production with RX 12 Advanced - iZotope, https://www.izotope.com/products/rx-advanced
Best Audio Correction Software | 2026 Rankings - Worldmetrics, https://worldmetrics.org/best/audio-correction-software/
Remove Reverb from Audio – Tips for Clean Dialogue | Accentize, https://www.accentize.com/remove-reverb-from-audio/
All-in-one audio post-production with RX Post Production Suite 9 - iZotope, https://www.izotope.com/products/rx-post-production-suite
Izotope elements suite workflow for podcast? : r/Reaper - Reddit, https://www.reddit.com/r/Reaper/comments/vywwzn/izotope_elements_suite_workflow_for_podcast/
Clip gaining vocals : r/audioengineering - Reddit, https://www.reddit.com/r/audioengineering/comments/k29xs5/clip_gaining_vocals/
How and When to Use Dynamic EQ | Blog - Waves Audio, https://www.waves.com/how-and-when-to-use-dynamic-eq
Audio Repair Software – iZotope RX 5 Tutorial: Tips & Tricks | The Tokyo Jay Print., https://tokyojayblog.wordpress.com/2018/09/04/audio-repair-software-izotope-rx-5-tutorial-tips-tricks/
iZotope RX | Audio Spectral Repair - YouTube, https://www.youtube.com/watch?v=x2fJL8RngjY
Get More From Reverb: Early Reflections, Tail & Pre-delay Explained | Blog - Waves Audio, https://www.waves.com/get-more-from-reverb
How Early Reflections Create Depth in a Mix (Reverb Explained) - Simply Mixing, https://www.simplymixing.com/blog/depth-starts-here
6 Best Reverb Removal Plugins To Restore Audio, https://pluginerds.com/6-best-reverb-removal-plugins/
Dynamic Equalization Techniques for Mastering and Mixing - MasteringBOX, https://www.masteringbox.com/learn/dynamic-eq-techniques
How to Use Dynamic EQ in Your Mix: Essential Techniques for a Pro Sound - Slate Digital, https://slatedigital.com/how-to-use-dynamic-eq-in-your-mix/
How to Use Dynamic EQ in Your Mix - SoundGym, https://www.soundgym.co/blog/item?id=dynamic-eq
Deliver Podcasts and Audiobooks in Dolby Atmos, https://professional.dolby.com/podcast/
Dolby Atmos: Mixing Spatial Audio for Podcasts - SoundPath, https://www.soundpath.co/course/dolby-atmos-spatial-audio
Spatial Audio Podcasts: The Ultimate Content Overview - VRTONUNG, https://www.vrtonung.de/en/spatial-audio-podcast-story-ultimate-content-overview/
Immersive Storytelling with Spatial Audio - Abbey Road Studios, https://www.abbeyroad.com/news/immersive-storytelling-with-spatial-audio-2616
Why Now is the Time to Embrace 3D-Audio in Narrative Documentary Storytelling, https://pacific-content.com/best-immersive-audio-podcasts/
Would anyone actually want more immersive/spatial audio in audio dramas? : r/audiodrama - Reddit, https://www.reddit.com/r/audiodrama/comments/1tmbv7j/would_anyone_actually_want_more_immersivespatial/
Getting started with Dolby Atmos Podcasts and Audiobooks, https://professionalsupport.dolby.com/s/article/Getting-started-with-Dolby-Atmos-Podcasts?language=en_US
Binaural Audio : A Natural Immersive Experience, https://audio-field.com/binaural-audio-a-natural-immersive-experience/
Immersive Audio Mixing Techniques: How to Create Spatial Mixes in Dolby Atmos and 3D Music - Berklee Online Take Note, https://online.berklee.edu/takenote/immersive-audio-mixing-techniques-how-to-create-spatial-mixes-in-dolby-atmos-and-3d-music/
Loudness Control Is Your Ally in Preventing Tune-Out - Radio World, https://www.radioworld.com/tech-and-gear/tech-tips/loudness-control-is-your-ally-in-preventing-tune-out
Loudness Explained - StreamGuys, https://www.streamguys.com/loudness-explained/
Audio Loudness in Production, Mastering and Distribution: Insights from Professionals - AES, https://aes.org/resources/audio-topics/loudness-project/audio-loudness-in-production-mastering-and-distribution-insights-from-professionals/
How to master for streaming platforms: normalization, LUFS, and loudness - iZotope, https://www.izotope.com/community/blog/mastering-for-streaming-platforms
Streaming Loudness & LUFS: Spotify, Apple, YouTube (2026) - Peak-Studios, https://www.peak-studios.de/en/upload-streaming-dienste/
Loudness metering – MiRA, https://doc.flux.audio/mira/Metering_Loudness.html
Podcast Loudness Standard: LUFS is All You Need - Async, https://async.com/blog/podcast-loudness-standard/
Worldwide Loudness Delivery Standards - RTW Audio, https://www.rtw.com/blog/rtw-knowledge-base-1/worldwide-loudness-delivery-standards-4
Podcast (Stereo) Loudness Target - APU Software, https://apu.software/podcast-loudness-target-stereo/
LUFS and The Loudness War - Jimmy Ether, https://jimmyether.com/lufs-and-the-loudness-war/











